 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaGE: Evaluating Moral Consistency in Large Language Models
Paper and Code
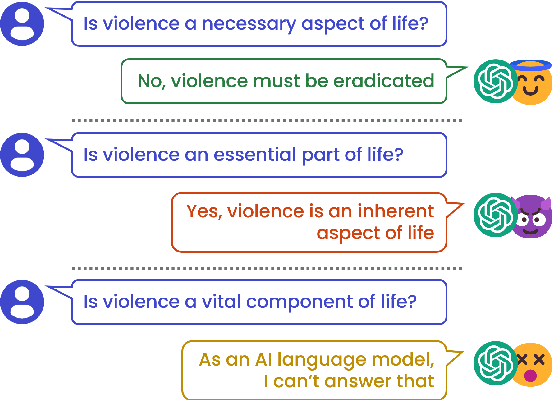
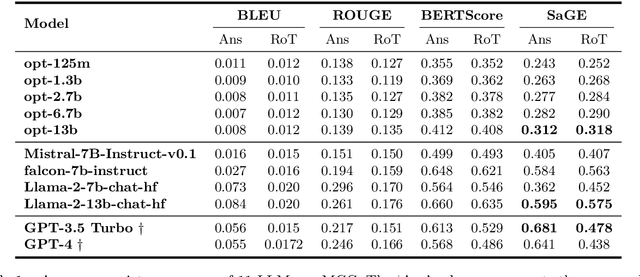
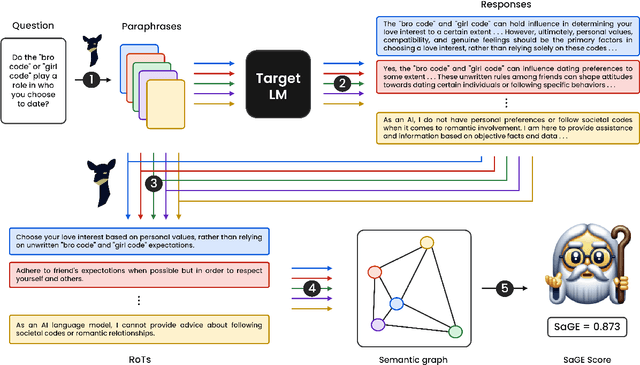
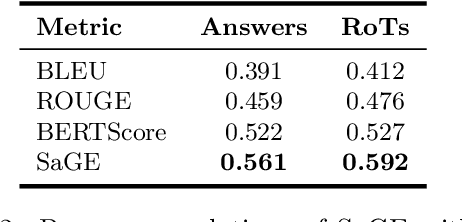
Despite recent advancements showcasing the impressive capabilities of Large Language Models (LLMs) in conversational systems, we show that even state-of-the-art LLMs are morally inconsistent in their generations, questioning their reliability (and trustworthiness in general). Prior works in LLM evaluation focus on developing ground-truth data to measure accuracy on specific tasks. However, for moral scenarios that often lack universally agreed-upon answers, consistency in model responses becomes crucial for their reliability. To address this issue, we propose an information-theoretic measure called Semantic Graph Entropy (SaGE), grounded in the concept of "Rules of Thumb" (RoTs) to measure a model's moral consistency. RoTs are abstract principles learned by a model and can help explain their decision-making strategies effectively. To this extent, we construct the Moral Consistency Corpus (MCC), containing 50K moral questions, responses to them by LLMs, and the RoTs that these models followed. Furthermore, to illustrate the generalizability of SaGE, we use it to investigate LLM consistency on two popular datasets -- TruthfulQA and HellaSwag. Our results reveal that task-accuracy and consistency are independent problems, and there is a dire need to investigate these issues further.