 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASEval: Extending Multi-Agent Evaluation from Models to Systems
Mar 09, 2026The rapid adoption of LLM-based agentic systems has produced a rich ecosystem of frameworks (smolagents, LangGraph, AutoGen, CAMEL, LlamaIndex, i.a.). Yet existing benchmarks are model-centric: they fix the agentic setup and do not compare other system components. We argue that implementation decisions substantially impact performance, including choices such as topology, orchestration logic, and error handling. MASEval addresses this evaluation gap with a framework-agnostic library that treats the entire system as the unit of analysis. Through a systematic system-level comparison across 3 benchmarks, 3 models, and 3 frameworks, we find that framework choice matters as much as model choice. MASEval allows researchers to explore all components of agentic systems, opening new avenues for principled system design, and practitioners to identify the best implementation for their use case. MASEval is available under the MIT licence https://github.com/parameterlab/MASEval.
Auditing Language Model Unlearning via Information Decomposition
Jan 21, 2026We expose a critical limitation in current approaches to machine unlearning in language models: despite the apparent success of unlearning algorithms, information about the forgotten data remains linearly decodable from internal representations. To systematically assess this discrepancy, we introduce an interpretable, information-theoretic framework for auditing unlearning using Partial Information Decomposition (PID). By comparing model representations before and after unlearning, we decompose the mutual information with the forgotten data into distinct components, formalizing the notions of unlearned and residual knowledge. Our analysis reveals that redundant information, shared across both models, constitutes residual knowledge that persists post-unlearning and correlates with susceptibility to known adversarial reconstruction attacks. Leveraging these insights, we propose a representation-based risk score that can guide abstention on sensitive inputs at inference time, providing a practical mechanism to mitigate privacy leakage. Our work introduces a principled, representation-level audit for unlearning, offering theoretical insight and actionable tools for safer deployment of language models.
Privacy Collapse: Benign Fine-Tuning Can Break Contextual Privacy in Language Models
Jan 21, 2026We identify a novel phenomenon in language models: benign fine-tuning of frontier models can lead to privacy collapse. We find that diverse, subtle patterns in training data can degrade contextual privacy, including optimisation for helpfulness, exposure to user information, emotional and subjective dialogue, and debugging code printing internal variables, among others. Fine-tuned models lose their ability to reason about contextual privacy norms, share information inappropriately with tools, and violate memory boundaries across contexts. Privacy collapse is a ``silent failure'' because models maintain high performance on standard safety and utility benchmarks whilst exhibiting severe privacy vulnerabilities. Our experiments show evidence of privacy collapse across six models (closed and open weight), five fine-tuning datasets (real-world and controlled data), and two task categories (agentic and memory-based). Our mechanistic analysis reveals that privacy representations are uniquely fragile to fine-tuning, compared to task-relevant features which are preserved. Our results reveal a critical gap in current safety evaluations, in particular for the deployment of specialised agents.
Differentially Private Steering for Large Language Model Alignment
Jan 30, 2025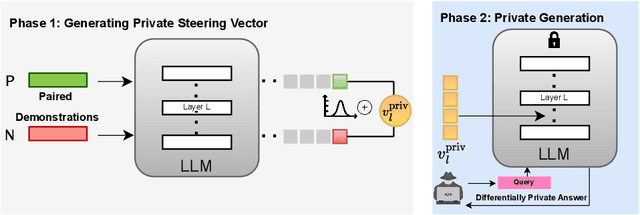

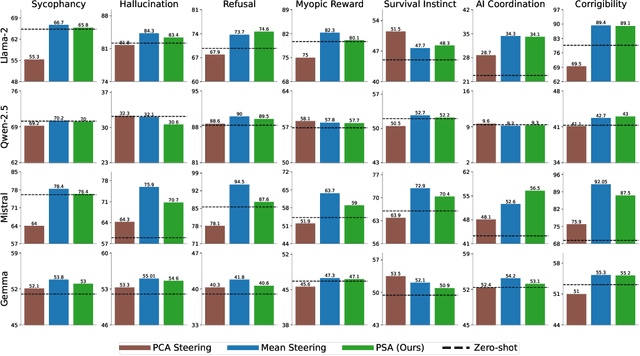
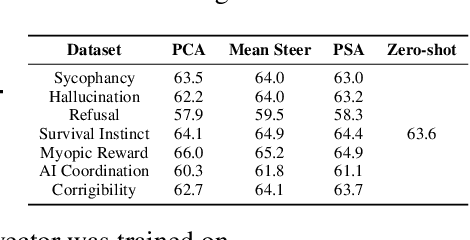
Aligning Large Language Models (LLMs) with human values and away from undesirable behaviors (such as hallucination) has become increasingly important. Recently, steering LLMs towards a desired behavior via activation editing has emerged as an effective method to mitigate harmful generations at inference-time. Activation editing modifies LLM representations by preserving information from positive demonstrations (e.g., truthful) and minimising information from negative demonstrations (e.g., hallucinations). When these demonstrations come from a private dataset, the aligned LLM may leak private information contained in those private samples. In this work, we present the first study of aligning LLM behavior with private datasets. Our work proposes the \textit{\underline{P}rivate \underline{S}teering for LLM \underline{A}lignment (PSA)} algorithm to edit LLM activations with differential privacy (DP) guarantees. We conduct extensive experiments on seven different benchmarks with open-source LLMs of different sizes (0.5B to 7B) and model families (LlaMa, Qwen, Mistral and Gemma). Our results show that PSA achieves DP guarantees for LLM alignment with minimal loss in performance, including alignment metrics, open-ended text generation quality, and general-purpose reasoning. We also develop the first Membership Inference Attack (MIA) for evaluating and auditing the empirical privacy for the problem of LLM steering via activation editing. Our attack is tailored for activation editing and relies solely on the generated texts without their associated probabilities. Our experiments support the theoretical guarantees by showing improved guarantees for our \textit{PSA} algorithm compared to several existing non-private techniques.
From Human Judgements to Predictive Models: Unravelling Acceptability in Code-Mixed Sentences
May 09, 2024



Current computational approaches for analysing or generating code-mixed sentences do not explicitly model "naturalness" or "acceptability" of code-mixed sentences, but rely on training corpora to reflect distribution of acceptable code-mixed sentences. Modelling human judgement for the acceptability of code-mixed text can help in distinguishing natural code-mixed text and enable quality-controlled generation of code-mixed text. To this end, we construct Cline - a dataset containing human acceptability judgements for English-Hindi (en-hi) code-mixed text. Cline is the largest of its kind with 16,642 sentences, consisting of samples sourced from two sources: synthetically generated code-mixed text and samples collected from online social media. Our analysis establishes that popular code-mixing metrics such as CMI, Number of Switch Points, Burstines, which are used to filter/curate/compare code-mixed corpora have low correlation with human acceptability judgements, underlining the necessity of our dataset. Experiments using Cline demonstrate that simple Multilayer Perceptron (MLP) models trained solely on code-mixing metrics are outperformed by fine-tuned pre-trained Multilingual Large Language Models (MLLMs). Specifically, XLM-Roberta and Bernice outperform IndicBERT across different configurations in challenging data settings. Comparison with ChatGPT's zero and fewshot capabilities shows that MLLMs fine-tuned on larger data outperform ChatGPT, providing scope for improvement in code-mixed tasks. Zero-shot transfer from English-Hindi to English-Telugu acceptability judgments using our model checkpoints proves superior to random baselines, enabling application to other code-mixed language pairs and providing further avenues of research. We publicly release our human-annotated dataset, trained checkpoints, code-mix corpus, and code for data generation and model training.
Socratic Reasoning Improves Positive Text Rewriting
Mar 05, 2024Reframing a negative into a positive thought is at the crux of several cognitive approaches to mental health and psychotherapy that could be made more accessible by large language model-based solutions. Such reframing is typically non-trivial and requires multiple rationalization steps to uncover the underlying issue of a negative thought and transform it to be more positive. However, this rationalization process is currently neglected by both datasets and models which reframe thoughts in one step. In this work, we address this gap by augmenting open-source datasets for positive text rewriting with synthetically-generated Socratic rationales using a novel framework called \textsc{SocraticReframe}. \textsc{SocraticReframe} uses a sequence of question-answer pairs to rationalize the thought rewriting process. We show that such Socratic rationales significantly improve positive text rewriting for different open-source LLMs according to both automatic and human evaluations guided by criteria from psychotherapy research.
InSaAF: Incorporating Safety through Accuracy and Fairness | Are LLMs ready for the Indian Legal Domain?
Feb 21, 2024



Recent advancements in language technology and Artificial Intelligence have resulted in numerous Language Models being proposed to perform various tasks in the legal domain ranging from predicting judgments to generating summaries. Despite their immense potential, these models have been proven to learn and exhibit societal biases and make unfair predictions. In this study, we explore the ability of Large Language Models (LLMs) to perform legal tasks in the Indian landscape when social factors are involved. We present a novel metric, $\beta$-weighted $\textit{Legal Safety Score ($LSS_{\beta}$)}$, which encapsulates both the fairness and accuracy aspects of the LLM. We assess LLMs' safety by considering its performance in the $\textit{Binary Statutory Reasoning}$ task and its fairness exhibition with respect to various axes of disparities in the Indian society. Task performance and fairness scores of LLaMA and LLaMA--2 models indicate that the proposed $LSS_{\beta}$ metric can effectively determine the readiness of a model for safe usage in the legal sector. We also propose finetuning pipelines, utilising specialised legal datasets, as a potential method to mitigate bias and improve model safety. The finetuning procedures on LLaMA and LLaMA--2 models increase the $LSS_{\beta}$, improving their usability in the Indian legal domain. Our code is publicly released.
X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents
Jun 30, 2023



Task-oriented dialogue research has mainly focused on a few popular languages like English and Chinese, due to the high dataset creation cost for a new language. To reduce the cost, we apply manual editing to automatically translated data. We create a new multilingual benchmark, X-RiSAWOZ, by translating the Chinese RiSAWOZ to 4 languages: English, French, Hindi, Korean; and a code-mixed English-Hindi language. X-RiSAWOZ has more than 18,000 human-verified dialogue utterances for each language, and unlike most multilingual prior work, is an end-to-end dataset for building fully-functioning agents. The many difficulties we encountered in creating X-RiSAWOZ led us to develop a toolset to accelerate the post-editing of a new language dataset after translation. This toolset improves machine translation with a hybrid entity alignment technique that combines neural with dictionary-based methods, along with many automated and semi-automated validation checks. We establish strong baselines for X-RiSAWOZ by training dialogue agents in the zero- and few-shot settings where limited gold data is available in the target language. Our results suggest that our translation and post-editing methodology and toolset can be used to create new high-quality multilingual dialogue agents cost-effectively. Our dataset, code, and toolkit are released open-source.
Are Models Trained on Indian Legal Data Fair?
Mar 14, 2023



Recent advances and applications of language technology and artificial intelligence have enabled much success across multiple domains like law, medical and mental health. AI-based Language Models, like Judgement Prediction, have recently been proposed for the legal sector. However, these models are strife with encoded social biases picked up from the training data. While bias and fairness have been studied across NLP, most studies primarily locate themselves within a Western context. In this work, we present an initial investigation of fairness from the Indian perspective in the legal domain. We highlight the propagation of learnt algorithmic biases in the bail prediction task for models trained on Hindi legal documents. We evaluate the fairness gap using demographic parity and show that a decision tree model trained for the bail prediction task has an overall fairness disparity of 0.237 between input features associated with Hindus and Muslims. Additionally, we highlight the need for further research and studies in the avenues of fairness/bias in applying AI in the legal sector with a specific focus on the Indian context.
PreCogIIITH at HinglishEval : Leveraging Code-Mixing Metrics & Language Model Embeddings To Estimate Code-Mix Quality
Jun 16, 2022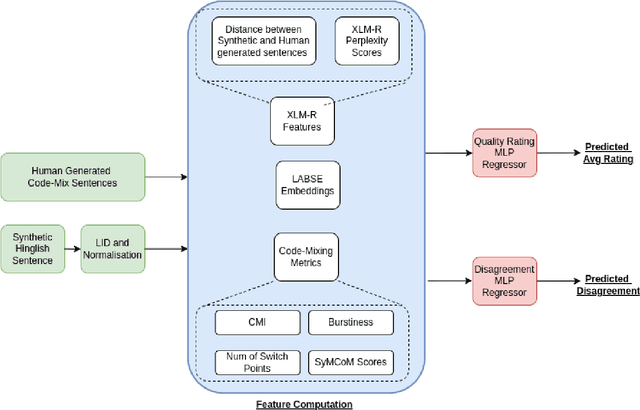

Code-Mixing is a phenomenon of mixing two or more languages in a speech event and is prevalent in multilingual societies. Given the low-resource nature of Code-Mixing, machine generation of code-mixed text is a prevalent approach for data augmentation. However, evaluating the quality of such machine generated code-mixed text is an open problem. In our submission to HinglishEval, a shared-task collocated with INLG2022, we attempt to build models factors that impact the quality of synthetically generated code-mix text by predicting ratings for code-mix quality.