 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAFIN: Centrality Aware Fairness inducing IN-processing for Unsupervised Representation Learning on Graphs
Apr 10, 2023Unsupervised representation learning on (large) graphs has received significant attention in the research community due to the compactness and richness of the learned embeddings and the abundance of unlabelled graph data. When deployed, these node representations must be generated with appropriate fairness constraints to minimize bias induced by them on downstream tasks. Consequently, group and individual fairness notions for graph learning algorithms have been investigated for specific downstream tasks. One major limitation of these fairness notions is that they do not consider the connectivity patterns in the graph leading to varied node influence (or centrality power). In this paper, we design a centrality-aware fairness framework for inductive graph representation learning algorithms. We propose CAFIN (Centrality Aware Fairness inducing IN-processing), an in-processing technique that leverages graph structure to improve GraphSAGE's representations - a popular framework in the unsupervised inductive setting. We demonstrate the efficacy of CAFIN in the inductive setting on two popular downstream tasks - Link prediction and Node Classification. Empirically, they consistently minimize the disparity in fairness between groups across datasets (varying from 18 to 80% reduction in imparity, a measure of group fairness) from different domains while incurring only a minimal performance cost.
HLDC: Hindi Legal Documents Corpus
Apr 02, 2022

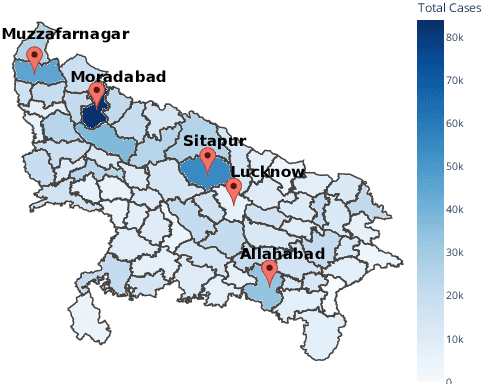
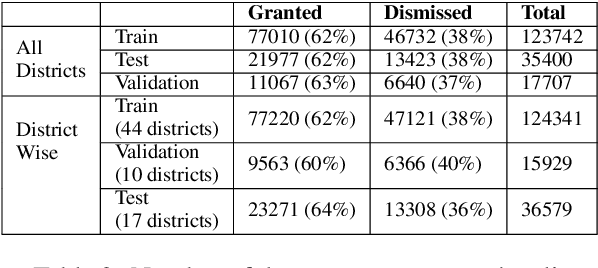
Many populous countries including India are burdened with a considerable backlog of legal cases. Development of automated systems that could process legal documents and augment legal practitioners can mitigate this. However, there is a dearth of high-quality corpora that is needed to develop such data-driven systems. The problem gets even more pronounced in the case of low resource languages such as Hindi. In this resource paper, we introduce the Hindi Legal Documents Corpus (HLDC), a corpus of more than 900K legal documents in Hindi. Documents are cleaned and structured to enable the development of downstream applications. Further, as a use-case for the corpus, we introduce the task of bail prediction. We experiment with a battery of models and propose a Multi-Task Learning (MTL) based model for the same. MTL models use summarization as an auxiliary task along with bail prediction as the main task. Experiments with different models are indicative of the need for further research in this area. We release the corpus and model implementation code with this paper: https://github.com/Exploration-Lab/HLDC