 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs
Sep 11, 2025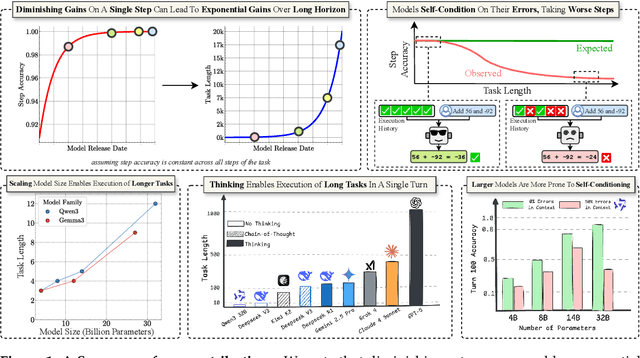
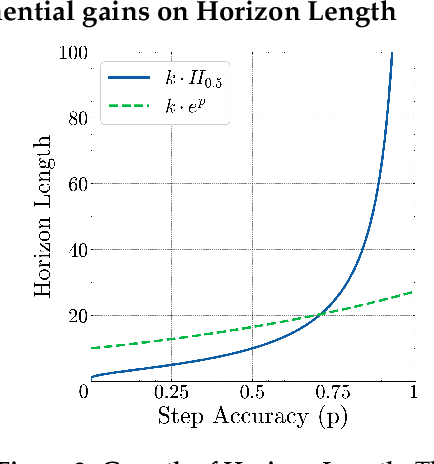
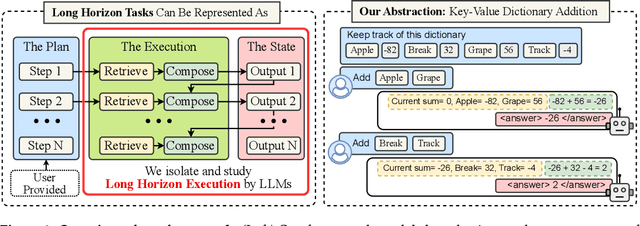
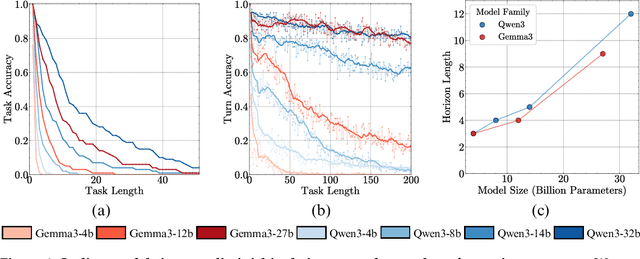
Does continued scaling of large language models (LLMs) yield diminishing returns? Real-world value often stems from the length of task an agent can complete. We start this work by observing the simple but counterintuitive fact that marginal gains in single-step accuracy can compound into exponential improvements in the length of a task a model can successfully complete. Then, we argue that failures of LLMs when simple tasks are made longer arise from mistakes in execution, rather than an inability to reason. We propose isolating execution capability, by explicitly providing the knowledge and plan needed to solve a long-horizon task. We find that larger models can correctly execute significantly more turns even when small models have 100\% single-turn accuracy. We observe that the per-step accuracy of models degrades as the number of steps increases. This is not just due to long-context limitations -- curiously, we observe a self-conditioning effect -- models become more likely to make mistakes when the context contains their errors from prior turns. Self-conditioning does not reduce by just scaling the model size. In contrast, recent thinking models do not self-condition, and can also execute much longer tasks in a single turn. We conclude by benchmarking frontier thinking models on the length of task they can execute in a single turn. Overall, by focusing on the ability to execute, we hope to reconcile debates on how LLMs can solve complex reasoning problems yet fail at simple tasks when made longer, and highlight the massive benefits of scaling model size and sequential test-time compute for long-horizon tasks.
SEMMA: A Semantic Aware Knowledge Graph Foundation Model
May 26, 2025Knowledge Graph Foundation Models (KGFMs) have shown promise in enabling zero-shot reasoning over unseen graphs by learning transferable patterns. However, most existing KGFMs rely solely on graph structure, overlooking the rich semantic signals encoded in textual attributes. We introduce SEMMA, a dual-module KGFM that systematically integrates transferable textual semantics alongside structure. SEMMA leverages Large Language Models (LLMs) to enrich relation identifiers, generating semantic embeddings that subsequently form a textual relation graph, which is fused with the structural component. Across 54 diverse KGs, SEMMA outperforms purely structural baselines like ULTRA in fully inductive link prediction. Crucially, we show that in more challenging generalization settings, where the test-time relation vocabulary is entirely unseen, structural methods collapse while SEMMA is 2x more effective. Our findings demonstrate that textual semantics are critical for generalization in settings where structure alone fails, highlighting the need for foundation models that unify structural and linguistic signals in knowledge reasoning.
A Cognac shot to forget bad memories: Corrective Unlearning in GNNs
Dec 01, 2024



Graph Neural Networks (GNNs) are increasingly being used for a variety of ML applications on graph data. As graph data does not follow the independently and identically distributed (i.i.d) assumption, adversarial manipulations or incorrect data can propagate to other data points through message passing, deteriorating the model's performance. To allow model developers to remove the adverse effects of manipulated entities from a trained GNN, we study the recently formulated problem of Corrective Unlearning. We find that current graph unlearning methods fail to unlearn the effect of manipulations even when the whole manipulated set is known. We introduce a new graph unlearning method, Cognac, which can unlearn the effect of the manipulation set even when only 5% of it is identified. It recovers most of the performance of a strong oracle with fully corrected training data, even beating retraining from scratch without the deletion set while being 8x more efficient. We hope our work guides GNN developers in fixing harmful effects due to issues in real-world data post-training.
Ensemble of Task-Specific Language Models for Brain Encoding
Oct 24, 2023


Language models have been shown to be rich enough to encode fMRI activations of certain Regions of Interest in our Brains. Previous works have explored transfer learning from representations learned for popular natural language processing tasks for predicting brain responses. In our work, we improve the performance of such encoders by creating an ensemble model out of 10 popular Language Models (2 syntactic and 8 semantic). We beat the current baselines by 10% on average across all ROIs through our ensembling methods.
CAFIN: Centrality Aware Fairness inducing IN-processing for Unsupervised Representation Learning on Graphs
Apr 10, 2023Unsupervised representation learning on (large) graphs has received significant attention in the research community due to the compactness and richness of the learned embeddings and the abundance of unlabelled graph data. When deployed, these node representations must be generated with appropriate fairness constraints to minimize bias induced by them on downstream tasks. Consequently, group and individual fairness notions for graph learning algorithms have been investigated for specific downstream tasks. One major limitation of these fairness notions is that they do not consider the connectivity patterns in the graph leading to varied node influence (or centrality power). In this paper, we design a centrality-aware fairness framework for inductive graph representation learning algorithms. We propose CAFIN (Centrality Aware Fairness inducing IN-processing), an in-processing technique that leverages graph structure to improve GraphSAGE's representations - a popular framework in the unsupervised inductive setting. We demonstrate the efficacy of CAFIN in the inductive setting on two popular downstream tasks - Link prediction and Node Classification. Empirically, they consistently minimize the disparity in fairness between groups across datasets (varying from 18 to 80% reduction in imparity, a measure of group fairness) from different domains while incurring only a minimal performance cost.