 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTab-Shapley: Identifying Top-k Tabular Data Quality Insights
Jan 12, 2025



We present an unsupervised method for aggregating anomalies in tabular datasets by identifying the top-k tabular data quality insights. Each insight consists of a set of anomalous attributes and the corresponding subsets of records that serve as evidence to the user. The process of identifying these insight blocks is challenging due to (i) the absence of labeled anomalies, (ii) the exponential size of the subset search space, and (iii) the complex dependencies among attributes, which obscure the true sources of anomalies. Simple frequency-based methods fail to capture these dependencies, leading to inaccurate results. To address this, we introduce Tab-Shapley, a cooperative game theory based framework that uses Shapley values to quantify the contribution of each attribute to the data's anomalous nature. While calculating Shapley values typically requires exponential time, we show that our game admits a closed-form solution, making the computation efficient. We validate the effectiveness of our approach through empirical analysis on real-world tabular datasets with ground-truth anomaly labels.
Annotation Efficiency: Identifying Hard Samples via Blocked Sparse Linear Bandits
Oct 26, 2024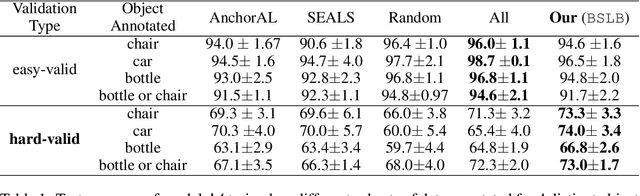
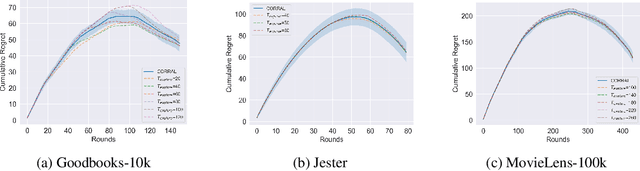
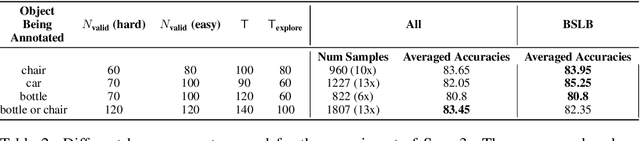
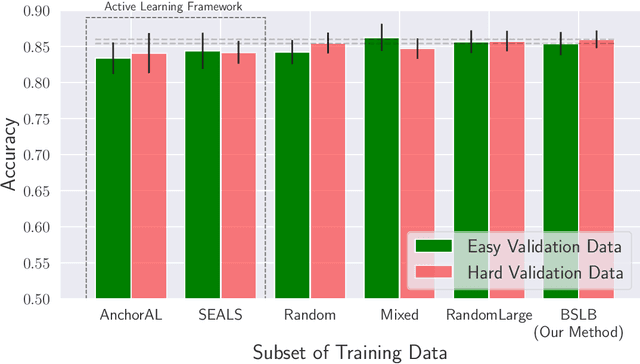
This paper considers the problem of annotating datapoints using an expert with only a few annotation rounds in a label-scarce setting. We propose soliciting reliable feedback on difficulty in annotating a datapoint from the expert in addition to ground truth label. Existing literature in active learning or coreset selection turns out to be less relevant to our setting since they presume the existence of a reliable trained model, which is absent in the label-scarce regime. However, the literature on coreset selection emphasizes the presence of difficult data points in the training set to perform supervised learning in downstream tasks (Mindermann et al., 2022). Therefore, for a given fixed annotation budget of $\mathsf{T}$ rounds, we model the sequential decision-making problem of which (difficult) datapoints to choose for annotation in a sparse linear bandits framework with the constraint that no arm can be pulled more than once (blocking constraint). With mild assumptions on the datapoints, our (computationally efficient) Explore-Then-Commit algorithm BSLB achieves a regret guarantee of $\widetilde{\mathsf{O}}(k^{\frac{1}{3}} \mathsf{T}^{\frac{2}{3}} +k^{-\frac{1}{2}} \beta_k + k^{-\frac{1}{12}} \beta_k^{\frac{1}{2}}\mathsf{T}^{\frac{5}{6}})$ where the unknown parameter vector has tail magnitude $\beta_k$ at sparsity level $k$. To this end, we show offline statistical guarantees of Lasso estimator with mild Restricted Eigenvalue (RE) condition that is also robust to sparsity. Finally, we propose a meta-algorithm C-BSLB that does not need knowledge of the optimal sparsity parameters at a no-regret cost. We demonstrate the efficacy of our BSLB algorithm for annotation in the label-scarce setting for an image classification task on the PASCAL-VOC dataset, where we use real-world annotation difficulty scores.
CAFIN: Centrality Aware Fairness inducing IN-processing for Unsupervised Representation Learning on Graphs
Apr 10, 2023Unsupervised representation learning on (large) graphs has received significant attention in the research community due to the compactness and richness of the learned embeddings and the abundance of unlabelled graph data. When deployed, these node representations must be generated with appropriate fairness constraints to minimize bias induced by them on downstream tasks. Consequently, group and individual fairness notions for graph learning algorithms have been investigated for specific downstream tasks. One major limitation of these fairness notions is that they do not consider the connectivity patterns in the graph leading to varied node influence (or centrality power). In this paper, we design a centrality-aware fairness framework for inductive graph representation learning algorithms. We propose CAFIN (Centrality Aware Fairness inducing IN-processing), an in-processing technique that leverages graph structure to improve GraphSAGE's representations - a popular framework in the unsupervised inductive setting. We demonstrate the efficacy of CAFIN in the inductive setting on two popular downstream tasks - Link prediction and Node Classification. Empirically, they consistently minimize the disparity in fairness between groups across datasets (varying from 18 to 80% reduction in imparity, a measure of group fairness) from different domains while incurring only a minimal performance cost.
Game of Gradients: Mitigating Irrelevant Clients in Federated Learning
Oct 23, 2021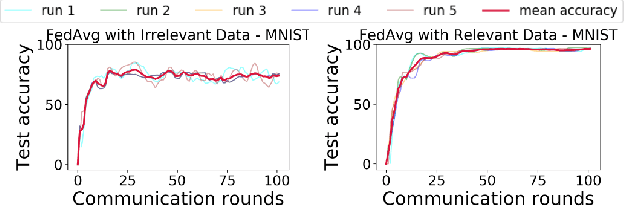
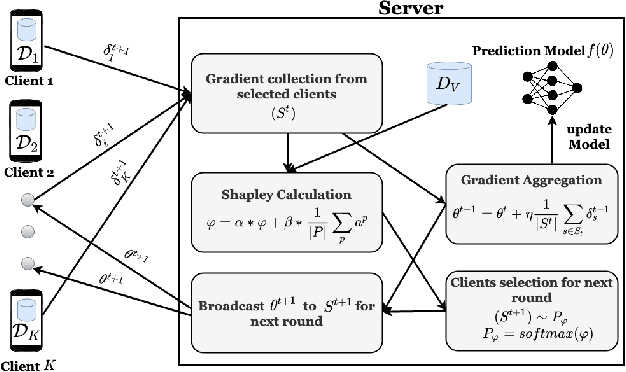
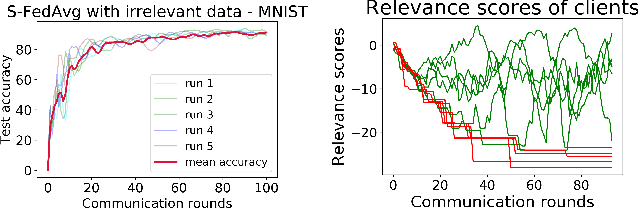
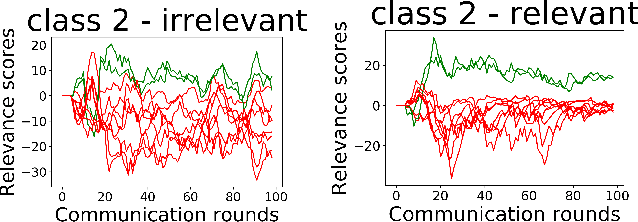
The paradigm of Federated learning (FL) deals with multiple clients participating in collaborative training of a machine learning model under the orchestration of a central server. In this setup, each client's data is private to itself and is not transferable to other clients or the server. Though FL paradigm has received significant interest recently from the research community, the problem of selecting the relevant clients w.r.t. the central server's learning objective is under-explored. We refer to these problems as Federated Relevant Client Selection (FRCS). Because the server doesn't have explicit control over the nature of data possessed by each client, the problem of selecting relevant clients is significantly complex in FL settings. In this paper, we resolve important and related FRCS problems viz., selecting clients with relevant data, detecting clients that possess data relevant to a particular target label, and rectifying corrupted data samples of individual clients. We follow a principled approach to address the above FRCS problems and develop a new federated learning method using the Shapley value concept from cooperative game theory. Towards this end, we propose a cooperative game involving the gradients shared by the clients. Using this game, we compute Shapley values of clients and then present Shapley value based Federated Averaging (S-FedAvg) algorithm that empowers the server to select relevant clients with high probability. S-FedAvg turns out to be critical in designing specific algorithms to address the FRCS problems. We finally conduct a thorough empirical analysis on image classification and speech recognition tasks to show the superior performance of S-FedAvg than the baselines in the context of supervised federated learning settings.
Beyond Node Embedding: A Direct Unsupervised Edge Representation Framework for Homogeneous Networks
Dec 11, 2019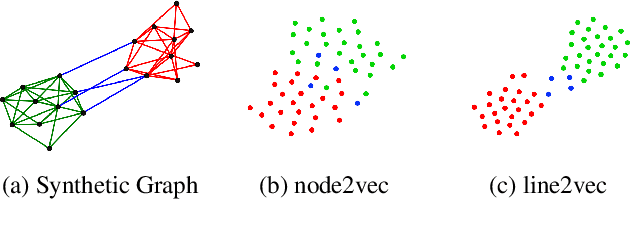
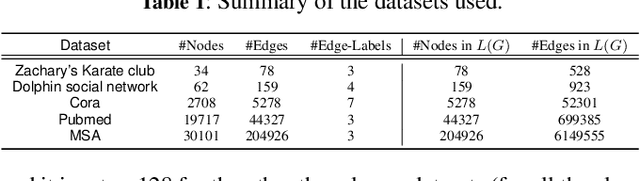
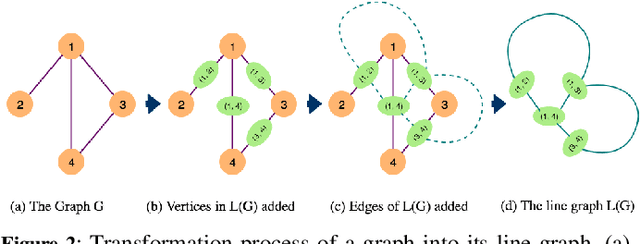
Network representation learning has traditionally been used to find lower dimensional vector representations of the nodes in a network. However, there are very important edge driven mining tasks of interest to the classical network analysis community, which have mostly been unexplored in the network embedding space. For applications such as link prediction in homogeneous networks, vector representation (i.e., embedding) of an edge is derived heuristically just by using simple aggregations of the embeddings of the end vertices of the edge. Clearly, this method of deriving edge embedding is suboptimal and there is a need for a dedicated unsupervised approach for embedding edges by leveraging edge properties of the network. Towards this end, we propose a novel concept of converting a network to its weighted line graph which is ideally suited to find the embedding of edges of the original network. We further derive a novel algorithm to embed the line graph, by introducing the concept of collective homophily. To the best of our knowledge, this is the first direct unsupervised approach for edge embedding in homogeneous information networks, without relying on the node embeddings. We validate the edge embeddings on three downstream edge mining tasks. Our proposed optimization framework for edge embedding also generates a set of node embeddings, which are not just the aggregation of edges. Further experimental analysis shows the connection of our framework to the concept of node centrality.
Cogniculture: Towards a Better Human-Machine Co-evolution
Dec 11, 2017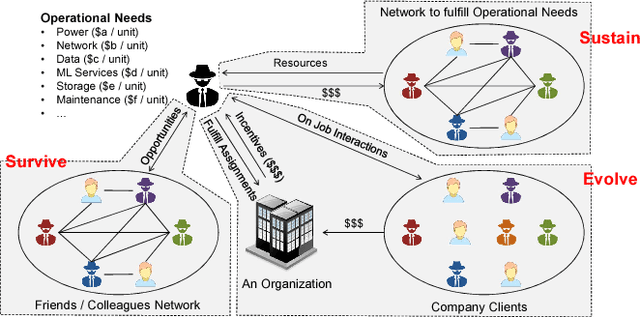
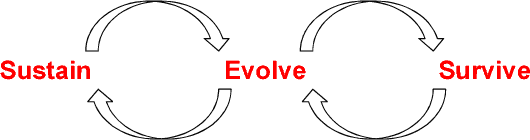
Research in Artificial Intelligence is breaking technology barriers every day. New algorithms and high performance computing are making things possible which we could only have imagined earlier. Though the enhancements in AI are making life easier for human beings day by day, there is constant fear that AI based systems will pose a threat to humanity. People in AI community have diverse set of opinions regarding the pros and cons of AI mimicking human behavior. Instead of worrying about AI advancements, we propose a novel idea of cognitive agents, including both human and machines, living together in a complex adaptive ecosystem, collaborating on human computation for producing essential social goods while promoting sustenance, survival and evolution of the agents' life cycle. We highlight several research challenges and technology barriers in achieving this goal. We propose a governance mechanism around this ecosystem to ensure ethical behaviors of all cognitive agents. Along with a novel set of use-cases of Cogniculture, we discuss the road map ahead for this journey.
All Fingers are not Equal: Intensity of References in Scientific Articles
Sep 01, 2016



Research accomplishment is usually measured by considering all citations with equal importance, thus ignoring the wide variety of purposes an article is being cited for. Here, we posit that measuring the intensity of a reference is crucial not only to perceive better understanding of research endeavor, but also to improve the quality of citation-based applications. To this end, we collect a rich annotated dataset with references labeled by the intensity, and propose a novel graph-based semi-supervised model, GraLap to label the intensity of references. Experiments with AAN datasets show a significant improvement compared to the baselines to achieve the true labels of the references (46% better correlation). Finally, we provide four applications to demonstrate how the knowledge of reference intensity leads to design better real-world applications.
Design of an Optimal Bayesian Incentive Compatible Broadcast Protocol for Ad hoc Networks with Rational Nodes
Jul 06, 2009
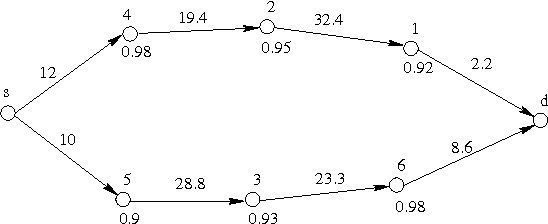
Nodes in an ad hoc wireless network incur certain costs for forwarding packets since packet forwarding consumes the resources of the nodes. If the nodes are rational, free packet forwarding by the nodes cannot be taken for granted and incentive based protocols are required to stimulate cooperation among the nodes. Existing incentive based approaches are based on the VCG (Vickrey-Clarke-Groves) mechanism which leads to high levels of incentive budgets and restricted applicability to only certain topologies of networks. Moreover, the existing approaches have only focused on unicast and multicast. Motivated by this, we propose an incentive based broadcast protocol that satisfies Bayesian incentive compatibility and minimizes the incentive budgets required by the individual nodes. The proposed protocol, which we call {\em BIC-B} (Bayesian incentive compatible broadcast) protocol, also satisfies budget balance. We also derive a necessary and sufficient condition for the ex-post individual rationality of the BIC-B protocol. The {\em BIC-B} protocol exhibits superior performance in comparison to a dominant strategy incentive compatible broadcast protocol.