 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQA: Diagnostic Question Answering for IT Support
Apr 07, 2026Enterprise IT support interactions are fundamentally diagnostic: effective resolution requires iterative evidence gathering from ambiguous user reports to identify an underlying root cause. While retrieval-augmented generation (RAG) provides grounding through historical cases, standard multi-turn RAG systems lack explicit diagnostic state and therefore struggle to accumulate evidence and resolve competing hypotheses across turns. We introduce DQA, a diagnostic question-answering framework that maintains persistent diagnostic state and aggregates retrieved cases at the level of root causes rather than individual documents. DQA combines conversational query rewriting, retrieval aggregation, and state-conditioned response generation to support systematic troubleshooting under enterprise latency and context constraints. We evaluate DQA on 150 anonymized enterprise IT support scenarios using a replay-based protocol. Averaged over three independent runs, DQA achieves a 78.7% success rate under a trajectory-level success criterion, compared to 41.3% for a multi-turn RAG baseline, while reducing average turns from 8.4 to 3.9.
VIGIL: Towards Edge-Extended Agentic AI for Enterprise IT Support
Mar 17, 2026Enterprise IT support is constrained by heterogeneous devices, evolving policies, and long-tail failure modes that are difficult to resolve centrally. We present VIGIL, an edge-extended agentic AI system that deploys desktop-resident agents to perform situated diagnosis, retrieval over enterprise knowledge, and policy-governed remediation directly on user devices with explicit consent and end-to-end observability. In a 10-week pilot of VIGIL's operational loop on 100 resource-constrained endpoints, VIGIL reduces interaction rounds by 39%, achieves at least 4 times faster diagnosis, and supports self-service resolution in 82% of matched cases. Users report excellent usability, high trust, and low cognitive workload across four validated instruments, with qualitative feedback highlighting transparency as critical for trust. Notably, users rated the system higher when no historical matches were available, suggesting on-device diagnosis provides value independent of knowledge base coverage. This pilot establishes safety and observability foundations for fleet-wide continuous improvement.
Scalable and Safe Remediation of Defective Actions in Self-Learning Conversational Systems
May 17, 2023



Off-Policy reinforcement learning has been a driving force for the state-of-the-art conversational AIs leading to more natural humanagent interactions and improving the user satisfaction for goal-oriented agents. However, in large-scale commercial settings, it is often challenging to balance between policy improvements and experience continuity on the broad spectrum of applications handled by such system. In the literature, off-policy evaluation and guard-railing on aggregate statistics has been commonly used to address this problem. In this paper, we propose a method for curating and leveraging high-precision samples sourced from historical regression incident reports to validate, safe-guard, and improve policies prior to the online deployment. We conducted extensive experiments using data from a real-world conversational system and actual regression incidents. The proposed method is currently deployed in our production system to protect customers against broken experiences and enable long-term policy improvements.
Scalable and Robust Self-Learning for Skill Routing in Large-Scale Conversational AI Systems
Apr 14, 2022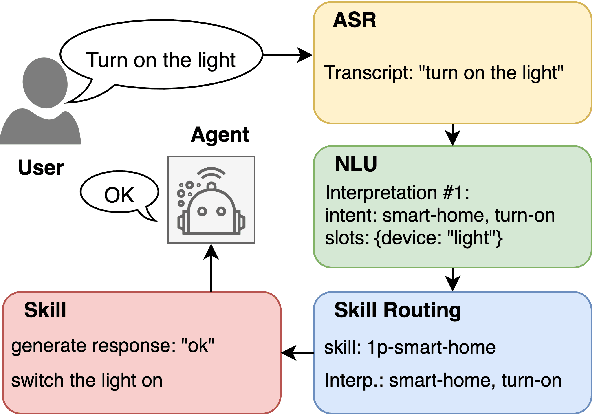
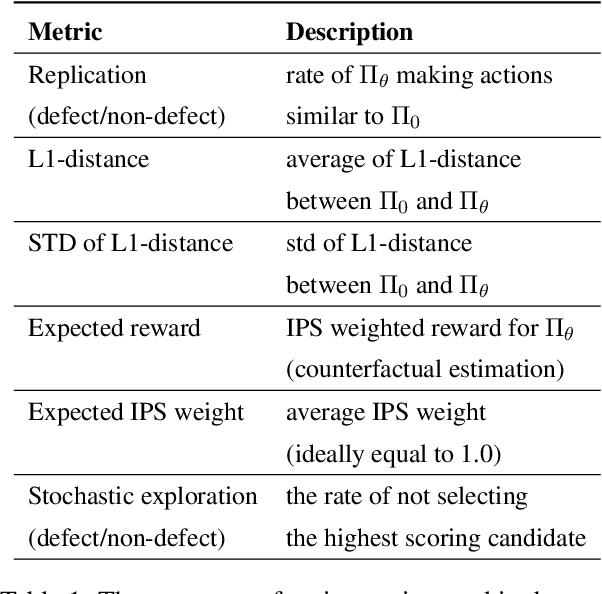
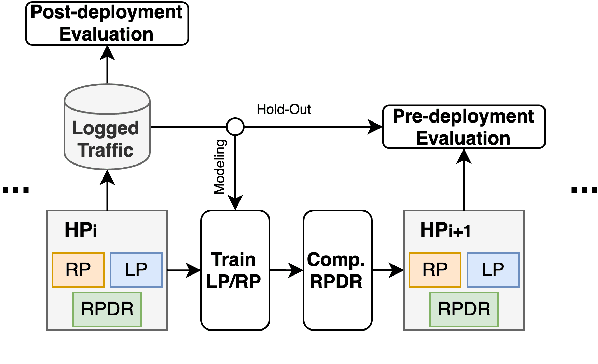

Skill routing is an important component in large-scale conversational systems. In contrast to traditional rule-based skill routing, state-of-the-art systems use a model-based approach to enable natural conversations. To provide supervision signal required to train such models, ideas such as human annotation, replication of a rule-based system, relabeling based on user paraphrases, and bandit-based learning were suggested. However, these approaches: (a) do not scale in terms of the number of skills and skill on-boarding, (b) require a very costly expert annotation/rule-design, (c) introduce risks in the user experience with each model update. In this paper, we present a scalable self-learning approach to explore routing alternatives without causing abrupt policy changes that break the user experience, learn from the user interaction, and incrementally improve the routing via frequent model refreshes. To enable such robust frequent model updates, we suggest a simple and effective approach that ensures controlled policy updates for individual domains, followed by an off-policy evaluation for making deployment decisions without any need for lengthy A/B experimentation. We conduct various offline and online A/B experiments on a commercial large-scale conversational system to demonstrate the effectiveness of the proposed method in real-world production settings.
Cogniculture: Towards a Better Human-Machine Co-evolution
Dec 11, 2017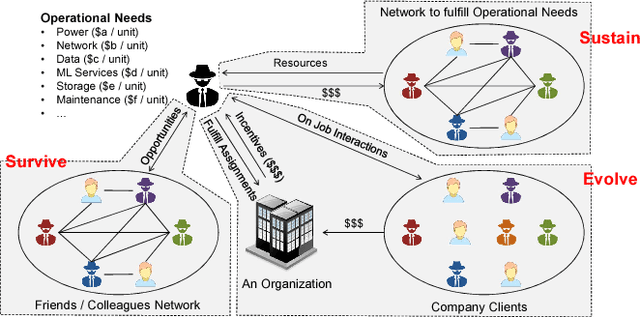
Research in Artificial Intelligence is breaking technology barriers every day. New algorithms and high performance computing are making things possible which we could only have imagined earlier. Though the enhancements in AI are making life easier for human beings day by day, there is constant fear that AI based systems will pose a threat to humanity. People in AI community have diverse set of opinions regarding the pros and cons of AI mimicking human behavior. Instead of worrying about AI advancements, we propose a novel idea of cognitive agents, including both human and machines, living together in a complex adaptive ecosystem, collaborating on human computation for producing essential social goods while promoting sustenance, survival and evolution of the agents' life cycle. We highlight several research challenges and technology barriers in achieving this goal. We propose a governance mechanism around this ecosystem to ensure ethical behaviors of all cognitive agents. Along with a novel set of use-cases of Cogniculture, we discuss the road map ahead for this journey.