 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Caching for LLM Serving Systems: Beyond Traditional Heuristics
Aug 26, 2025Serving Large Language Models (LLMs) at scale requires meeting strict Service Level Objectives (SLOs) under severe computational and memory constraints. Nevertheless, traditional caching strategies fall short: exact-matching and prefix caches neglect query semantics, while state-of-the-art semantic caches remain confined to traditional intuitions, offering little conceptual departure. Building on this, we present SISO, a semantic caching system that redefines efficiency for LLM serving. SISO introduces centroid-based caching to maximize coverage with minimal memory, locality-aware replacement to preserve high-value entries, and dynamic thresholding to balance accuracy and latency under varying workloads. Across diverse datasets, SISO delivers up to 1.71$\times$ higher hit ratios and consistently stronger SLO attainment compared to state-of-the-art systems.
InfoFusion Controller: Informed TRRT Star with Mutual Information based on Fusion of Pure Pursuit and MPC for Enhanced Path Planning
Mar 08, 2025In this paper, we propose the InfoFusion Controller, an advanced path planning algorithm that integrates both global and local planning strategies to enhance autonomous driving in complex urban environments. The global planner utilizes the informed Theta-Rapidly-exploring Random Tree Star (Informed-TRRT*) algorithm to generate an optimal reference path, while the local planner combines Model Predictive Control (MPC) and Pure Pursuit algorithms. Mutual Information (MI) is employed to fuse the outputs of the MPC and Pure Pursuit controllers, effectively balancing their strengths and compensating for their weaknesses. The proposed method addresses the challenges of navigating in dynamic environments with unpredictable obstacles by reducing uncertainty in local path planning and improving dynamic obstacle avoidance capabilities. Experimental results demonstrate that the InfoFusion Controller outperforms traditional methods in terms of safety, stability, and efficiency across various scenarios, including complex maps generated using SLAM techniques. The code for the InfoFusion Controller is available at https: //github.com/DrawingProcess/InfoFusionController.
SeDi-Instruct: Enhancing Alignment of Language Models through Self-Directed Instruction Generation
Feb 07, 2025The rapid evolution of Large Language Models (LLMs) has enabled the industry to develop various AI-based services. Instruction tuning is considered essential in adapting foundation models for target domains to provide high-quality services to customers. A key challenge in instruction tuning is obtaining high-quality instruction data. Self-Instruct, which automatically generates instruction data using ChatGPT APIs, alleviates the data scarcity problem. To improve the quality of instruction data, Self-Instruct discards many of the instructions generated from ChatGPT, even though it is inefficient in terms of cost owing to many useless API calls. To generate high-quality instruction data at a low cost, we propose a novel data generation framework, Self-Direct Instruction generation (SeDi-Instruct), which employs diversity-based filtering and iterative feedback task generation. Diversity-based filtering maintains model accuracy without excessively discarding low-quality generated instructions by enhancing the diversity of instructions in a batch. This reduces the cost of synthesizing instruction data. The iterative feedback task generation integrates instruction generation and training tasks and utilizes information obtained during the training to create high-quality instruction sets. Our results show that SeDi-Instruct enhances the accuracy of AI models by 5.2%, compared with traditional methods, while reducing data generation costs by 36%.
Data-Efficient Alignment of Large Language Models with Human Feedback Through Natural Language
Nov 24, 2023



Learning from human feedback is a prominent technique to align the output of large language models (LLMs) with human expectations. Reinforcement learning from human feedback (RLHF) leverages human preference signals that are in the form of ranking of response pairs to perform this alignment. However, human preference on LLM outputs can come in much richer forms including natural language, which may provide detailed feedback on strengths and weaknesses of a given response. In this work we investigate data efficiency of modeling human feedback that is in natural language. Specifically, we fine-tune an open-source LLM, e.g., Falcon-40B-Instruct, on a relatively small amount (1000 records or even less) of human feedback in natural language in the form of critiques and revisions of responses. We show that this model is able to improve the quality of responses from even some of the strongest LLMs such as ChatGPT, BARD, and Vicuna, through critique and revision of those responses. For instance, through one iteration of revision of ChatGPT responses, the revised responses have 56.6% win rate over the original ones, and this win rate can be further improved to 65.9% after applying the revision for five iterations.
Data Augmentation for Improving Tail-traffic Robustness in Skill-routing for Dialogue Systems
Jun 07, 2023Large-scale conversational systems typically rely on a skill-routing component to route a user request to an appropriate skill and interpretation to serve the request. In such system, the agent is responsible for serving thousands of skills and interpretations which create a long-tail distribution due to the natural frequency of requests. For example, the samples related to play music might be a thousand times more frequent than those asking for theatre show times. Moreover, inputs used for ML-based skill routing are often a heterogeneous mix of strings, embedding vectors, categorical and scalar features which makes employing augmentation-based long-tail learning approaches challenging. To improve the skill-routing robustness, we propose an augmentation of heterogeneous skill-routing data and training targeted for robust operation in long-tail data regimes. We explore a variety of conditional encoder-decoder generative frameworks to perturb original data fields and create synthetic training data. To demonstrate the effectiveness of the proposed method, we conduct extensive experiments using real-world data from a commercial conversational system. Based on the experiment results, the proposed approach improves more than 80% (51 out of 63) of intents with less than 10K of traffic instances in the skill-routing replication task.
Open World Classification with Adaptive Negative Samples
Mar 09, 2023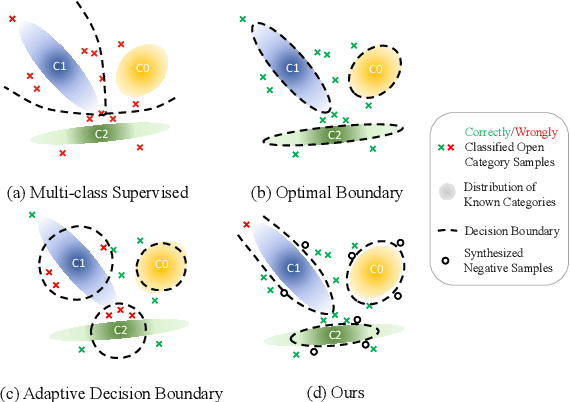
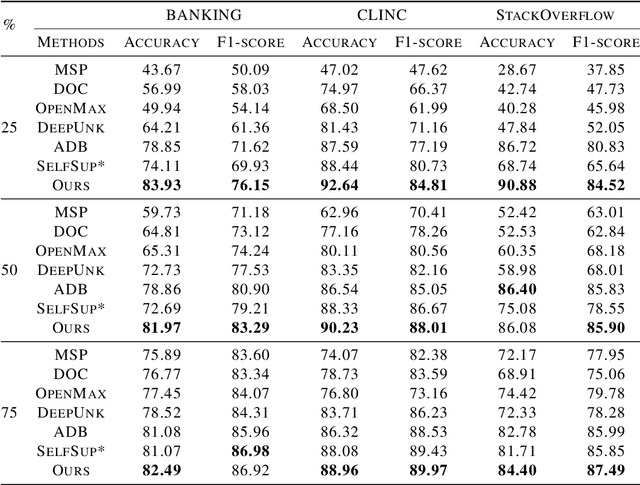
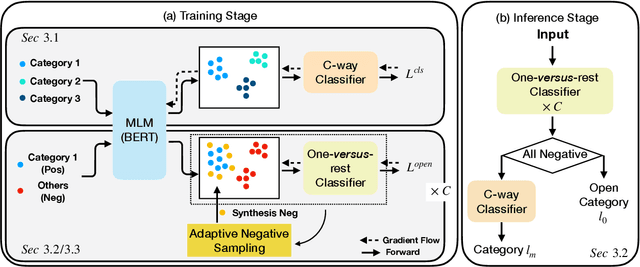
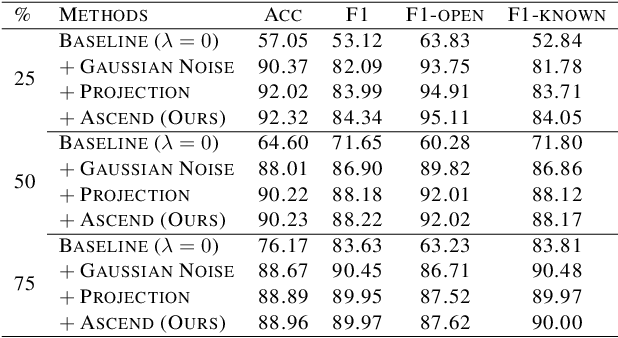
Open world classification is a task in natural language processing with key practical relevance and impact. Since the open or {\em unknown} category data only manifests in the inference phase, finding a model with a suitable decision boundary accommodating for the identification of known classes and discrimination of the open category is challenging. The performance of existing models is limited by the lack of effective open category data during the training stage or the lack of a good mechanism to learn appropriate decision boundaries. We propose an approach based on \underline{a}daptive \underline{n}egative \underline{s}amples (ANS) designed to generate effective synthetic open category samples in the training stage and without requiring any prior knowledge or external datasets. Empirically, we find a significant advantage in using auxiliary one-versus-rest binary classifiers, which effectively utilize the generated negative samples and avoid the complex threshold-seeking stage in previous works. Extensive experiments on three benchmark datasets show that ANS achieves significant improvements over state-of-the-art methods.
Cluster-Guided Label Generation in Extreme Multi-Label Classification
Feb 17, 2023For extreme multi-label classification (XMC), existing classification-based models poorly perform for tail labels and often ignore the semantic relations among labels, like treating "Wikipedia" and "Wiki" as independent and separate labels. In this paper, we cast XMC as a generation task (XLGen), where we benefit from pre-trained text-to-text models. However, generating labels from the extremely large label space is challenging without any constraints or guidance. We, therefore, propose to guide label generation using label cluster information to hierarchically generate lower-level labels. We also find that frequency-based label ordering and using decoding ensemble methods are critical factors for the improvements in XLGen. XLGen with cluster guidance significantly outperforms the classification and generation baselines on tail labels, and also generally improves the overall performance in four popular XMC benchmarks. In human evaluation, we also find XLGen generates unseen but plausible labels. Our code is now available at https://github.com/alexa/xlgen-eacl-2023.
Selective In-Context Data Augmentation for Intent Detection using Pointwise V-Information
Feb 10, 2023

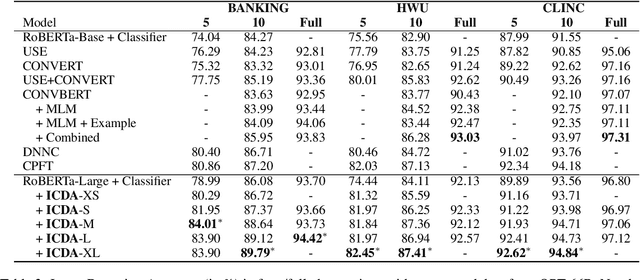
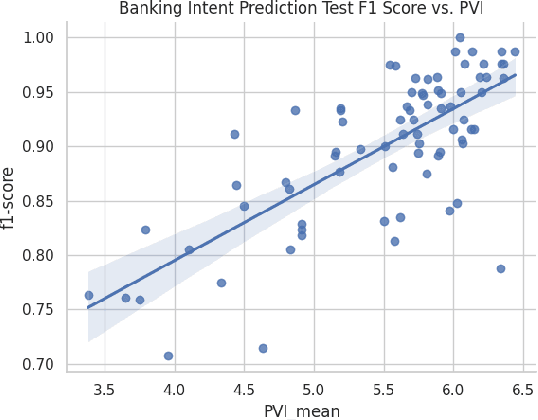
This work focuses on in-context data augmentation for intent detection. Having found that augmentation via in-context prompting of large pre-trained language models (PLMs) alone does not improve performance, we introduce a novel approach based on PLMs and pointwise V-information (PVI), a metric that can measure the usefulness of a datapoint for training a model. Our method first fine-tunes a PLM on a small seed of training data and then synthesizes new datapoints - utterances that correspond to given intents. It then employs intent-aware filtering, based on PVI, to remove datapoints that are not helpful to the downstream intent classifier. Our method is thus able to leverage the expressive power of large language models to produce diverse training data. Empirical results demonstrate that our method can produce synthetic training data that achieve state-of-the-art performance on three challenging intent detection datasets under few-shot settings (1.28% absolute improvement in 5-shot and 1.18% absolute in 10-shot, on average) and perform on par with the state-of-the-art in full-shot settings (within 0.01% absolute, on average).
Constrained Policy Optimization for Controlled Self-Learning in Conversational AI Systems
Sep 17, 2022
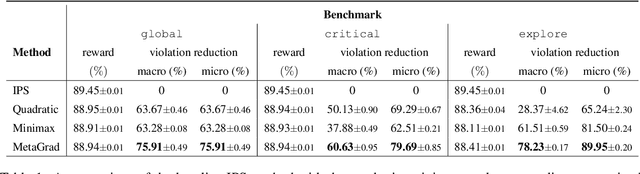

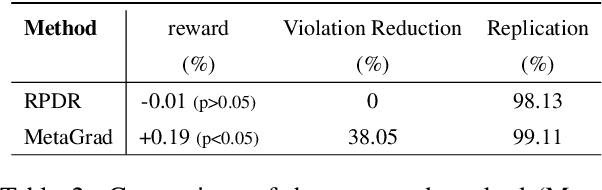
Recently, self-learning methods based on user satisfaction metrics and contextual bandits have shown promising results to enable consistent improvements in conversational AI systems. However, directly targeting such metrics by off-policy bandit learning objectives often increases the risk of making abrupt policy changes that break the current user experience. In this study, we introduce a scalable framework for supporting fine-grained exploration targets for individual domains via user-defined constraints. For example, we may want to ensure fewer policy deviations in business-critical domains such as shopping, while allocating more exploration budget to domains such as music. Furthermore, we present a novel meta-gradient learning approach that is scalable and practical to address this problem. The proposed method adjusts constraint violation penalty terms adaptively through a meta objective that encourages balanced constraint satisfaction across domains. We conduct extensive experiments using data from a real-world conversational AI on a set of realistic constraint benchmarks. Based on the experimental results, we demonstrate that the proposed approach is capable of achieving the best balance between the policy value and constraint satisfaction rate.
Debiasing Neighbor Aggregation for Graph Neural Network in Recommender Systems
Aug 18, 2022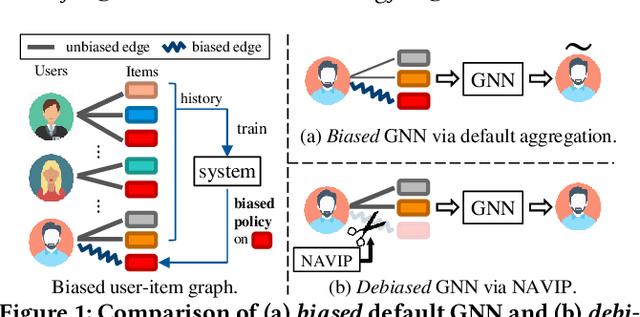

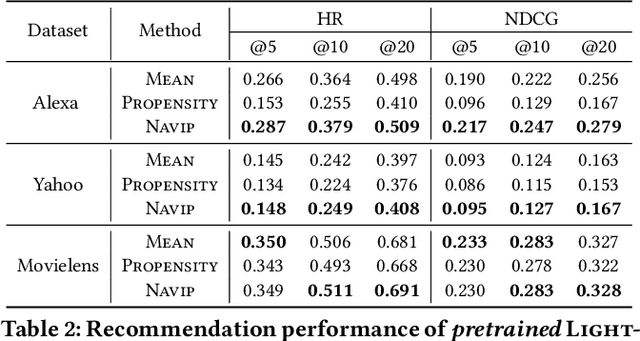
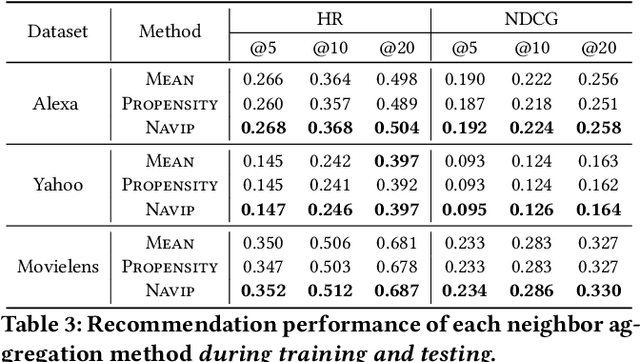
Graph neural networks (GNNs) have achieved remarkable success in recommender systems by representing users and items based on their historical interactions. However, little attention was paid to GNN's vulnerability to exposure bias: users are exposed to a limited number of items so that a system only learns a biased view of user preference to result in suboptimal recommendation quality. Although inverse propensity weighting is known to recognize and alleviate exposure bias, it usually works on the final objective with the model outputs, whereas GNN can also be biased during neighbor aggregation. In this paper, we propose a simple but effective approach, neighbor aggregation via inverse propensity (Navip) for GNNs. Specifically, given a user-item bipartite graph, we first derive propensity score of each user-item interaction in the graph. Then, inverse of the propensity score with Laplacian normalization is applied to debias neighbor aggregation from exposure bias. We validate the effectiveness of our approach through our extensive experiments on two public and Amazon Alexa datasets where the performance enhances up to 14.2%.