 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Posterior Networks for Approximately Bayesian Epistemic Uncertainty Estimation
Dec 29, 2023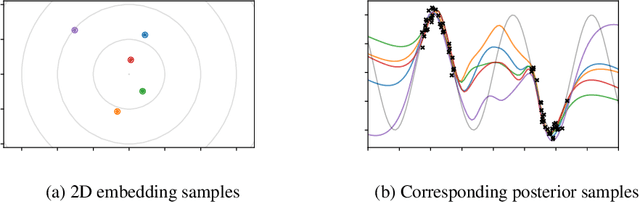
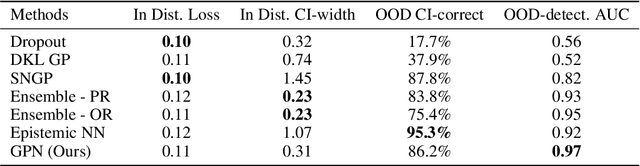
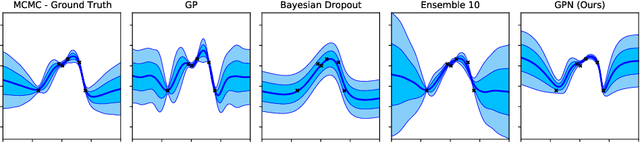
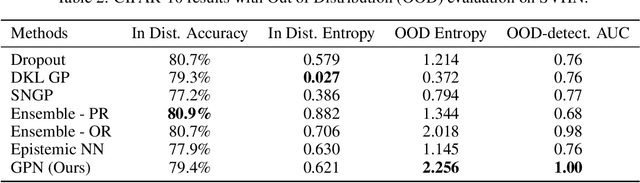
In many real-world problems, there is a limited set of training data, but an abundance of unlabeled data. We propose a new method, Generative Posterior Networks (GPNs), that uses unlabeled data to estimate epistemic uncertainty in high-dimensional problems. A GPN is a generative model that, given a prior distribution over functions, approximates the posterior distribution directly by regularizing the network towards samples from the prior. We prove theoretically that our method indeed approximates the Bayesian posterior and show empirically that it improves epistemic uncertainty estimation and scalability over competing methods.
Data Augmentation for Improving Tail-traffic Robustness in Skill-routing for Dialogue Systems
Jun 07, 2023Large-scale conversational systems typically rely on a skill-routing component to route a user request to an appropriate skill and interpretation to serve the request. In such system, the agent is responsible for serving thousands of skills and interpretations which create a long-tail distribution due to the natural frequency of requests. For example, the samples related to play music might be a thousand times more frequent than those asking for theatre show times. Moreover, inputs used for ML-based skill routing are often a heterogeneous mix of strings, embedding vectors, categorical and scalar features which makes employing augmentation-based long-tail learning approaches challenging. To improve the skill-routing robustness, we propose an augmentation of heterogeneous skill-routing data and training targeted for robust operation in long-tail data regimes. We explore a variety of conditional encoder-decoder generative frameworks to perturb original data fields and create synthetic training data. To demonstrate the effectiveness of the proposed method, we conduct extensive experiments using real-world data from a commercial conversational system. Based on the experiment results, the proposed approach improves more than 80% (51 out of 63) of intents with less than 10K of traffic instances in the skill-routing replication task.
Improving Adversarial Robustness via Joint Classification and Multiple Explicit Detection Classes
Oct 26, 2022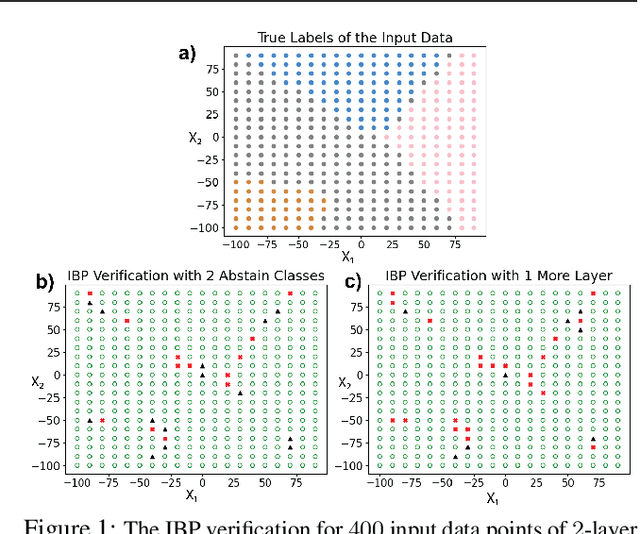
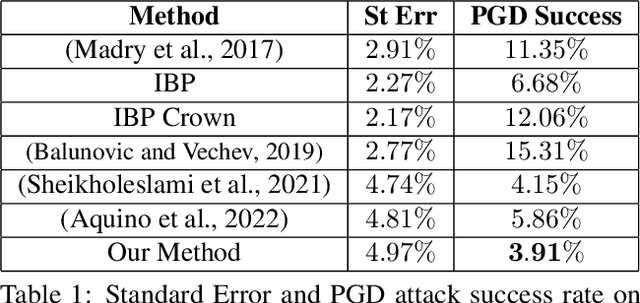
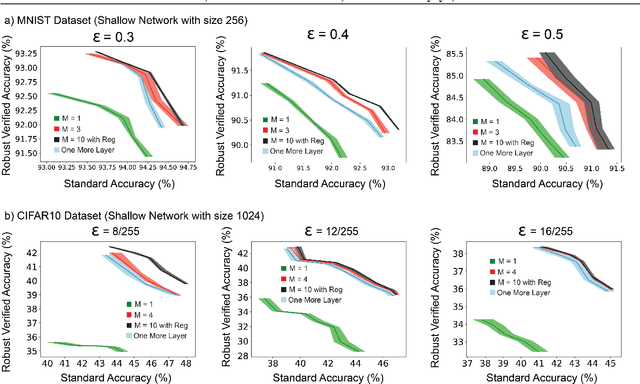
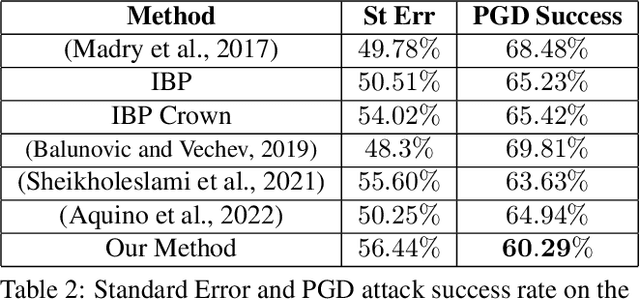
This work concerns the development of deep networks that are certifiably robust to adversarial attacks. Joint robust classification-detection was recently introduced as a certified defense mechanism, where adversarial examples are either correctly classified or assigned to the "abstain" class. In this work, we show that such a provable framework can benefit by extension to networks with multiple explicit abstain classes, where the adversarial examples are adaptively assigned to those. We show that naively adding multiple abstain classes can lead to "model degeneracy", then we propose a regularization approach and a training method to counter this degeneracy by promoting full use of the multiple abstain classes. Our experiments demonstrate that the proposed approach consistently achieves favorable standard vs. robust verified accuracy tradeoffs, outperforming state-of-the-art algorithms for various choices of number of abstain classes.
You Only Query Once: Effective Black Box Adversarial Attacks with Minimal Repeated Queries
Jan 29, 2021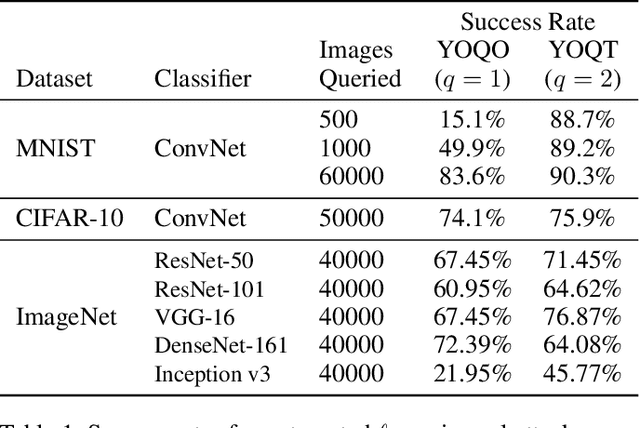



Researchers have repeatedly shown that it is possible to craft adversarial attacks on deep classifiers (small perturbations that significantly change the class label), even in the "black-box" setting where one only has query access to the classifier. However, all prior work in the black-box setting attacks the classifier by repeatedly querying the same image with minor modifications, usually thousands of times or more, making it easy for defenders to detect an ensuing attack. In this work, we instead show that it is possible to craft (universal) adversarial perturbations in the black-box setting by querying a sequence of different images only once. This attack prevents detection from high number of similar queries and produces a perturbation that causes misclassification when applied to any input to the classifier. In experiments, we show that attacks that adhere to this restriction can produce untargeted adversarial perturbations that fool the vast majority of MNIST and CIFAR-10 classifier inputs, as well as in excess of $60-70\%$ of inputs on ImageNet classifiers. In the targeted setting, we exhibit targeted black-box universal attacks on ImageNet classifiers with success rates above $20\%$ when only allowed one query per image, and $66\%$ when allowed two queries per image.
Reinforcement Learning for Caching with Space-Time Popularity Dynamics
May 19, 2020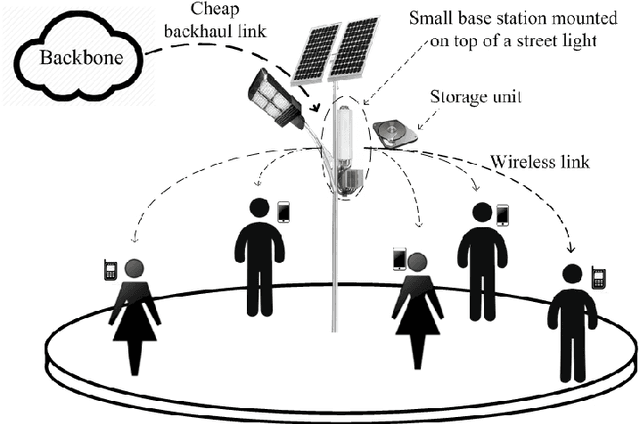
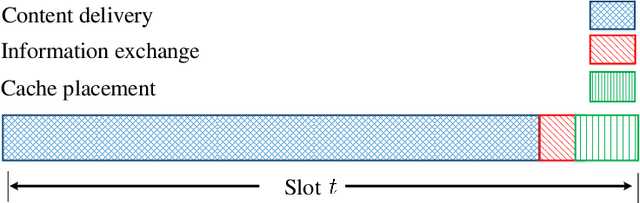
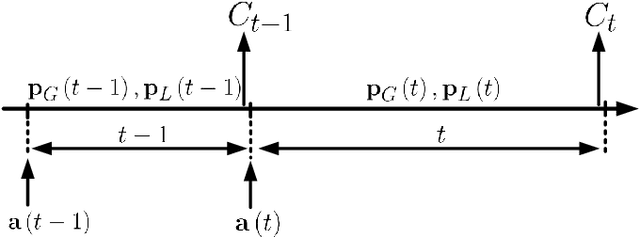
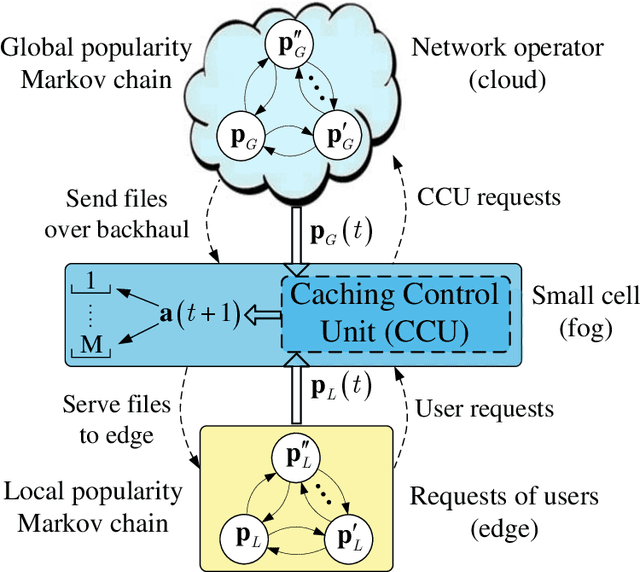
With the tremendous growth of data traffic over wired and wireless networks along with the increasing number of rich-media applications, caching is envisioned to play a critical role in next-generation networks. To intelligently prefetch and store contents, a cache node should be able to learn what and when to cache. Considering the geographical and temporal content popularity dynamics, the limited available storage at cache nodes, as well as the interactive in uence of caching decisions in networked caching settings, developing effective caching policies is practically challenging. In response to these challenges, this chapter presents a versatile reinforcement learning based approach for near-optimal caching policy design, in both single-node and network caching settings under dynamic space-time popularities. The herein presented policies are complemented using a set of numerical tests, which showcase the merits of the presented approach relative to several standard caching policies.
Minimum Uncertainty Based Detection of Adversaries in Deep Neural Networks
Apr 05, 2019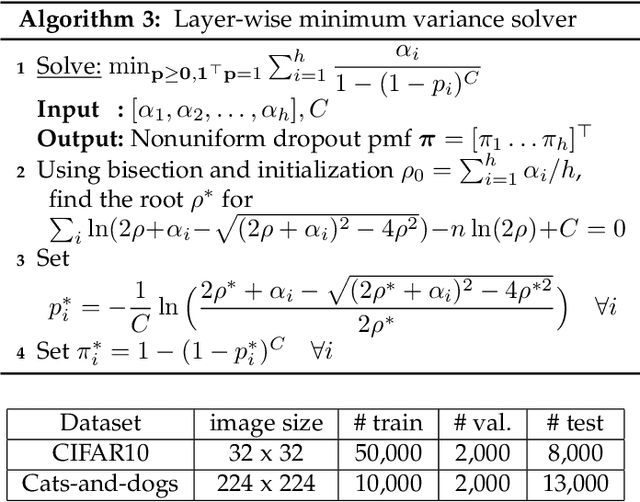
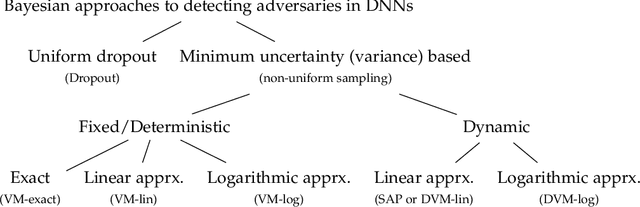
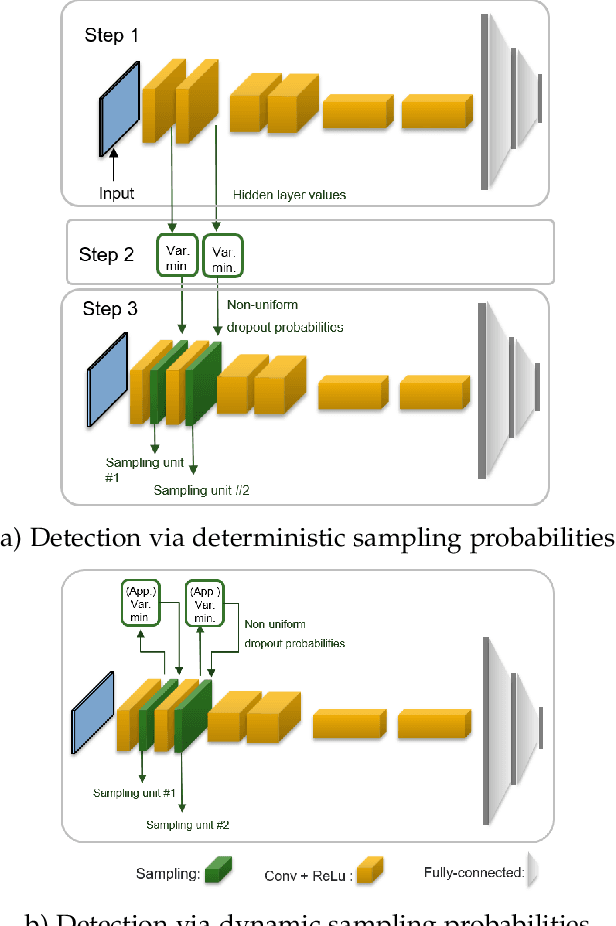
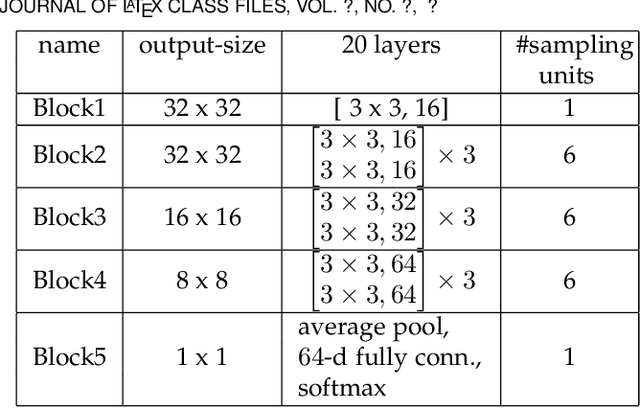
Despite their unprecedented performance in various domains, utilization of Deep Neural Networks (DNNs) in safety-critical environments is severely limited in the presence of even small adversarial perturbations. The present work develops a randomized approach to detecting such perturbations based on minimum uncertainty metrics that rely on sampling at the hidden layers during the DNN inference stage. The sampling probabilities are designed for effective detection of the adversarially corrupted inputs. Being modular, the novel detector of adversaries can be conveniently employed by any pre-trained DNN at no extra training overhead. Selecting which units to sample per hidden layer entails quantifying the amount of DNN output uncertainty from the viewpoint of Bayesian neural networks, where the overall uncertainty is expressed in terms of its layer-wise components - what also promotes scalability. Sampling probabilities are then sought by minimizing uncertainty measures layer-by-layer, leading to a novel convex optimization problem that admits an exact solver with superlinear convergence rate. By simplifying the objective function, low-complexity approximate solvers are also developed. In addition to valuable insights, these approximations link the novel approach with state-of-the-art randomized adversarial detectors. The effectiveness of the novel detectors in the context of competing alternatives is highlighted through extensive tests for various types of adversarial attacks with variable levels of strength.
Reinforcement Learning for Adaptive Caching with Dynamic Storage Pricing
Dec 21, 2018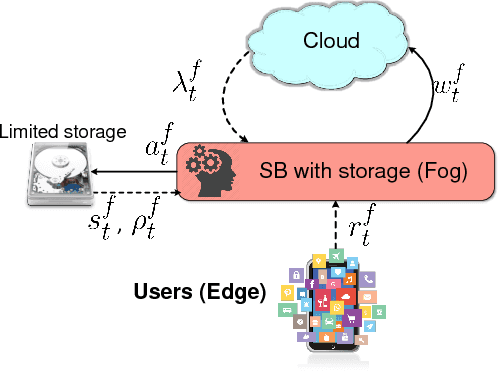
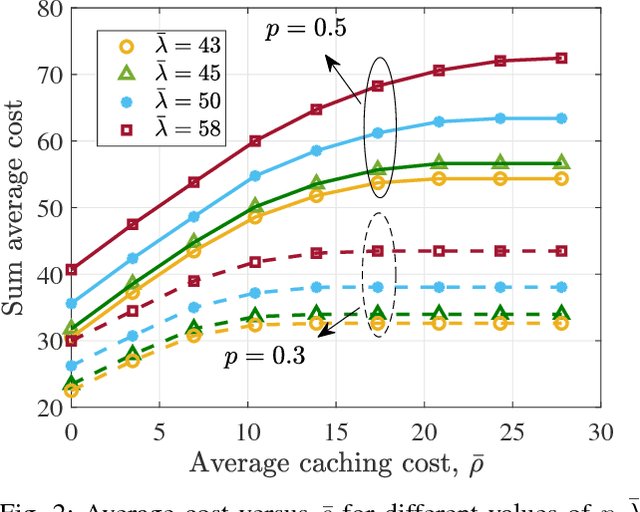
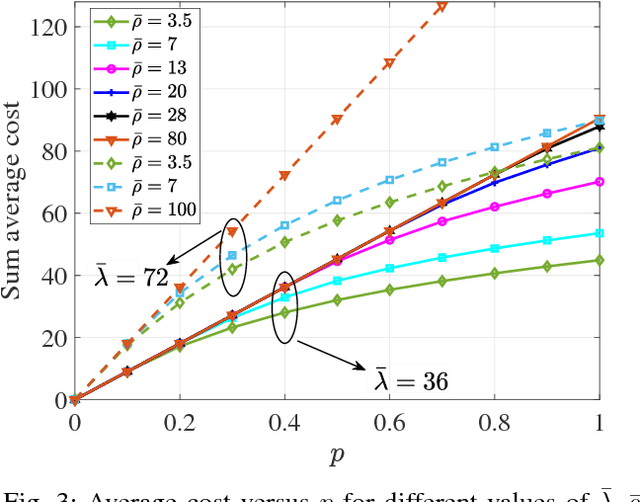
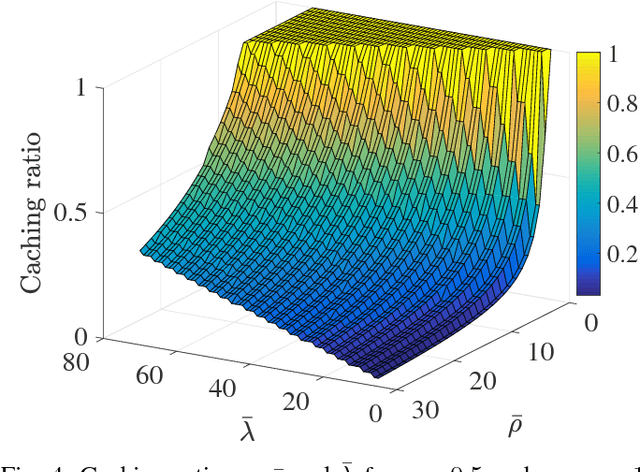
Small base stations (SBs) of fifth-generation (5G) cellular networks are envisioned to have storage devices to locally serve requests for reusable and popular contents by \emph{caching} them at the edge of the network, close to the end users. The ultimate goal is to shift part of the predictable load on the back-haul links, from on-peak to off-peak periods, contributing to a better overall network performance and service experience. To enable the SBs with efficient \textit{fetch-cache} decision-making schemes operating in dynamic settings, this paper introduces simple but flexible generic time-varying fetching and caching costs, which are then used to formulate a constrained minimization of the aggregate cost across files and time. Since caching decisions per time slot influence the content availability in future slots, the novel formulation for optimal fetch-cache decisions falls into the class of dynamic programming. Under this generic formulation, first by considering stationary distributions for the costs and file popularities, an efficient reinforcement learning-based solver known as value iteration algorithm can be used to solve the emerging optimization problem. Later, it is shown that practical limitations on cache capacity can be handled using a particular instance of the generic dynamic pricing formulation. Under this setting, to provide a light-weight online solver for the corresponding optimization, the well-known reinforcement learning algorithm, $Q$-learning, is employed to find optimal fetch-cache decisions. Numerical tests corroborating the merits of the proposed approach wrap up the paper.
Large-scale Kernel-based Feature Extraction via Budgeted Nonlinear Subspace Tracking
Dec 26, 2017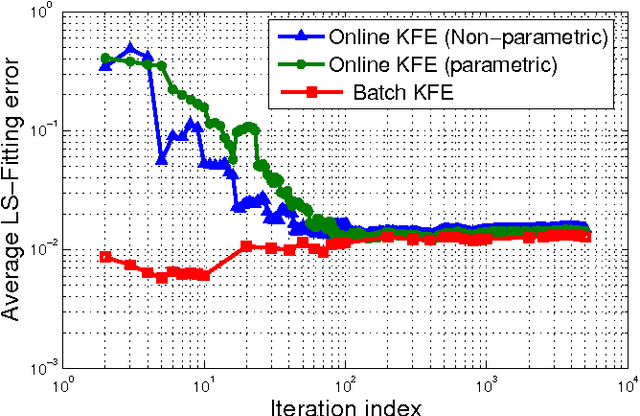
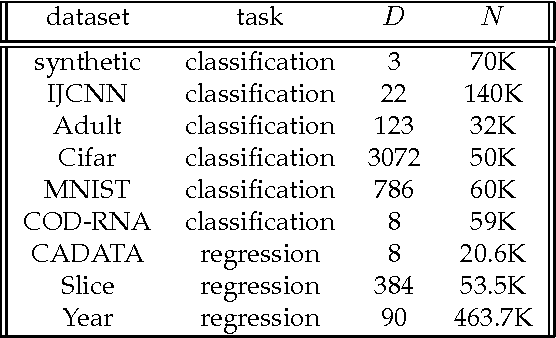
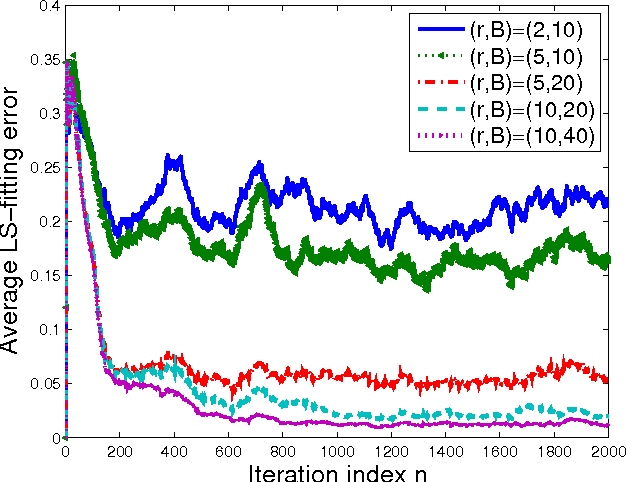
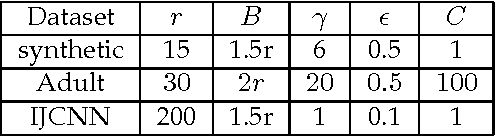
Kernel-based methods enjoy powerful generalization capabilities in handling a variety of learning tasks. When such methods are provided with sufficient training data, broadly-applicable classes of nonlinear functions can be approximated with desired accuracy. Nevertheless, inherent to the nonparametric nature of kernel-based estimators are computational and memory requirements that become prohibitive with large-scale datasets. In response to this formidable challenge, the present work puts forward a low-rank, kernel-based, feature extraction approach that is particularly tailored for online operation, where data streams need not be stored in memory. A novel generative model is introduced to approximate high-dimensional (possibly infinite) features via a low-rank nonlinear subspace, the learning of which leads to a direct kernel function approximation. Offline and online solvers are developed for the subspace learning task, along with affordable versions, in which the number of stored data vectors is confined to a predefined budget. Analytical results provide performance bounds on how well the kernel matrix as well as kernel-based classification and regression tasks can be approximated by leveraging budgeted online subspace learning and feature extraction schemes. Tests on synthetic and real datasets demonstrate and benchmark the efficiency of the proposed method when linear classification and regression is applied to the extracted features.