 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Curious Case of Remarkable Resilience to Gradient Attacks via Fully Convolutional and Differentiable Front End with a Skip Connection
Feb 26, 2024We tested front-end enhanced neural models where a frozen classifier was prepended by a differentiable and fully convolutional model with a skip connection. By training them using a small learning rate for about one epoch, we obtained models that retained the accuracy of the backbone classifier while being unusually resistant to gradient attacks including APGD and FAB-T attacks from the AutoAttack package, which we attributed to gradient masking. The gradient masking phenomenon is not new, but the degree of masking was quite remarkable for fully differentiable models that did not have gradient-shattering components such as JPEG compression or components that are expected to cause diminishing gradients. Though black box attacks can be partially effective against gradient masking, they are easily defeated by combining models into randomized ensembles. We estimate that such ensembles achieve near-SOTA AutoAttack accuracy on CIFAR10, CIFAR100, and ImageNet despite having virtually zero accuracy under adaptive attacks. Adversarial training of the backbone classifier can further increase resistance of the front-end enhanced model to gradient attacks. On CIFAR10, the respective randomized ensemble achieved 90.8$\pm 2.5$% (99% CI) accuracy under AutoAttack while having only 18.2$\pm 3.6$% accuracy under the adaptive attack. We do not establish SOTA in adversarial robustness. Instead, we make methodological contributions and further supports the thesis that adaptive attacks designed with the complete knowledge of model architecture are crucial in demonstrating model robustness and that even the so-called white-box gradient attacks can have limited applicability. Although gradient attacks can be complemented with black-box attack such as the SQUARE attack or the zero-order PGD, black-box attacks can be weak against randomized ensembles, e.g., when ensemble models mask gradients.
Leveraging Foundation Models to Improve Lightweight Clients in Federated Learning
Nov 14, 2023Federated Learning (FL) is a distributed training paradigm that enables clients scattered across the world to cooperatively learn a global model without divulging confidential data. However, FL faces a significant challenge in the form of heterogeneous data distributions among clients, which leads to a reduction in performance and robustness. A recent approach to mitigating the impact of heterogeneous data distributions is through the use of foundation models, which offer better performance at the cost of larger computational overheads and slower inference speeds. We introduce foundation model distillation to assist in the federated training of lightweight client models and increase their performance under heterogeneous data settings while keeping inference costs low. Our results show improvement in the global model performance on a balanced testing set, which contains rarely observed samples, even under extreme non-IID client data distributions. We conduct a thorough evaluation of our framework with different foundation model backbones on CIFAR10, with varying degrees of heterogeneous data distributions ranging from class-specific data partitions across clients to dirichlet data sampling, parameterized by values between 0.01 and 1.0.
Defending Multimodal Fusion Models against Single-Source Adversaries
Jun 25, 2022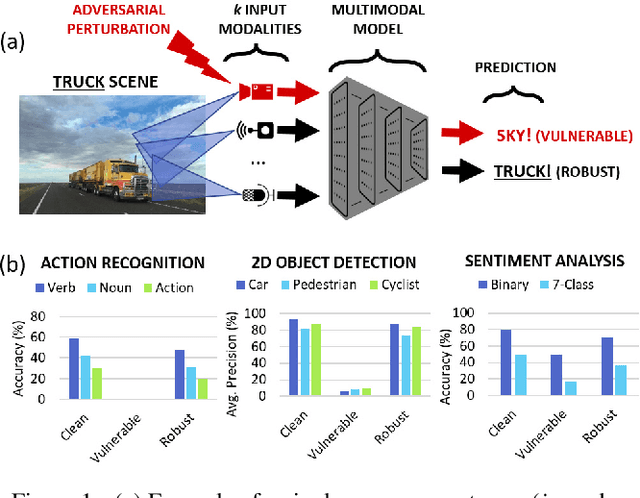

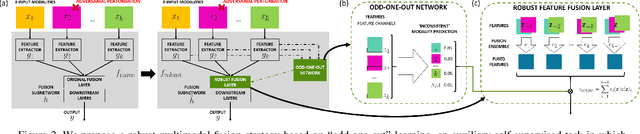
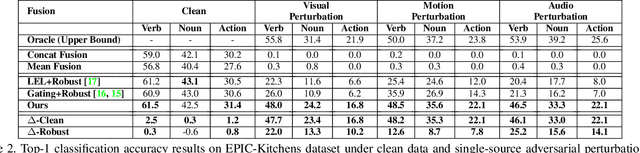
Beyond achieving high performance across many vision tasks, multimodal models are expected to be robust to single-source faults due to the availability of redundant information between modalities. In this paper, we investigate the robustness of multimodal neural networks against worst-case (i.e., adversarial) perturbations on a single modality. We first show that standard multimodal fusion models are vulnerable to single-source adversaries: an attack on any single modality can overcome the correct information from multiple unperturbed modalities and cause the model to fail. This surprising vulnerability holds across diverse multimodal tasks and necessitates a solution. Motivated by this finding, we propose an adversarially robust fusion strategy that trains the model to compare information coming from all the input sources, detect inconsistencies in the perturbed modality compared to the other modalities, and only allow information from the unperturbed modalities to pass through. Our approach significantly improves on state-of-the-art methods in single-source robustness, achieving gains of 7.8-25.2% on action recognition, 19.7-48.2% on object detection, and 1.6-6.7% on sentiment analysis, without degrading performance on unperturbed (i.e., clean) data.
Smooth-Reduce: Leveraging Patches for Improved Certified Robustness
May 12, 2022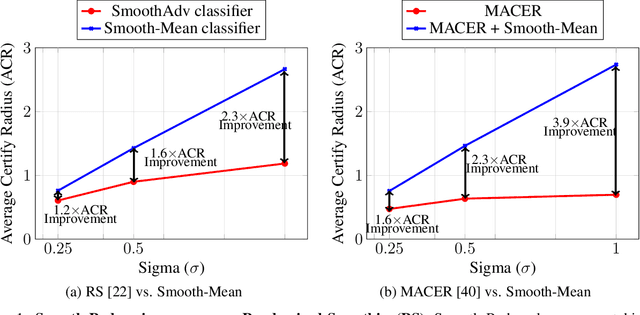
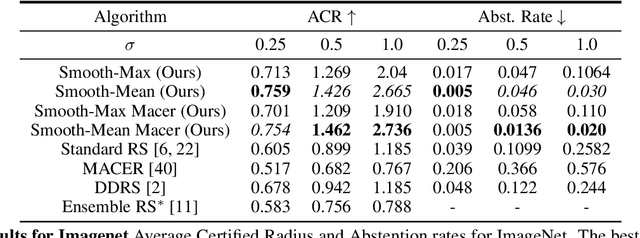
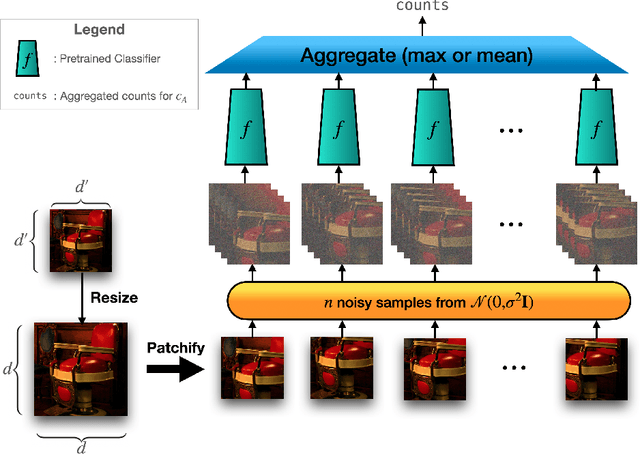
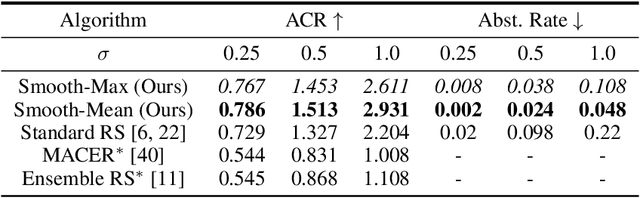
Randomized smoothing (RS) has been shown to be a fast, scalable technique for certifying the robustness of deep neural network classifiers. However, methods based on RS require augmenting data with large amounts of noise, which leads to significant drops in accuracy. We propose a training-free, modified smoothing approach, Smooth-Reduce, that leverages patching and aggregation to provide improved classifier certificates. Our algorithm classifies overlapping patches extracted from an input image, and aggregates the predicted logits to certify a larger radius around the input. We study two aggregation schemes -- max and mean -- and show that both approaches provide better certificates in terms of certified accuracy, average certified radii and abstention rates as compared to concurrent approaches. We also provide theoretical guarantees for such certificates, and empirically show significant improvements over other randomized smoothing methods that require expensive retraining. Further, we extend our approach to videos and provide meaningful certificates for video classifiers. A project page can be found at https://nyu-dice-lab.github.io/SmoothReduce/
You Only Query Once: Effective Black Box Adversarial Attacks with Minimal Repeated Queries
Jan 29, 2021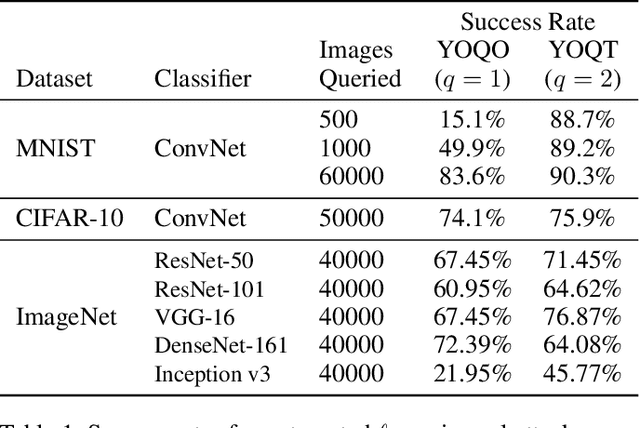



Researchers have repeatedly shown that it is possible to craft adversarial attacks on deep classifiers (small perturbations that significantly change the class label), even in the "black-box" setting where one only has query access to the classifier. However, all prior work in the black-box setting attacks the classifier by repeatedly querying the same image with minor modifications, usually thousands of times or more, making it easy for defenders to detect an ensuing attack. In this work, we instead show that it is possible to craft (universal) adversarial perturbations in the black-box setting by querying a sequence of different images only once. This attack prevents detection from high number of similar queries and produces a perturbation that causes misclassification when applied to any input to the classifier. In experiments, we show that attacks that adhere to this restriction can produce untargeted adversarial perturbations that fool the vast majority of MNIST and CIFAR-10 classifier inputs, as well as in excess of $60-70\%$ of inputs on ImageNet classifiers. In the targeted setting, we exhibit targeted black-box universal attacks on ImageNet classifiers with success rates above $20\%$ when only allowed one query per image, and $66\%$ when allowed two queries per image.
Provably robust deep generative models
Apr 22, 2020
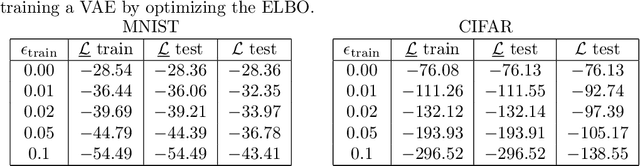

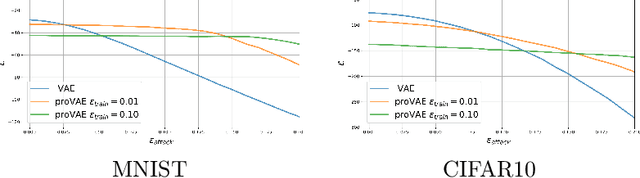
Recent work in adversarial attacks has developed provably robust methods for training deep neural network classifiers. However, although they are often mentioned in the context of robustness, deep generative models themselves have received relatively little attention in terms of formally analyzing their robustness properties. In this paper, we propose a method for training provably robust generative models, specifically a provably robust version of the variational auto-encoder (VAE). To do so, we first formally define a (certifiably) robust lower bound on the variational lower bound of the likelihood, and then show how this bound can be optimized during training to produce a robust VAE. We evaluate the method on simple examples, and show that it is able to produce generative models that are substantially more robust to adversarial attacks (i.e., an adversary trying to perturb inputs so as to drastically lower their likelihood under the model).
Performance measures for classification systems with rejection
Jan 27, 2016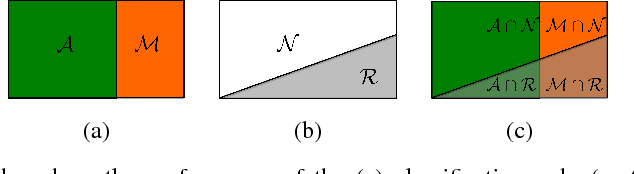
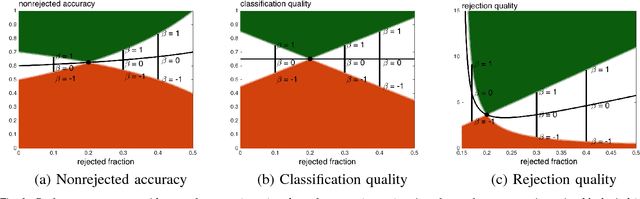
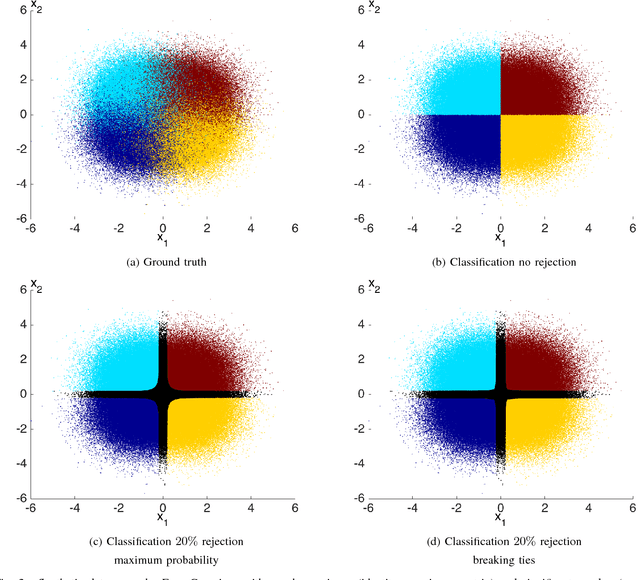
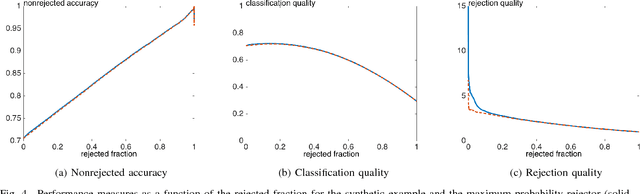
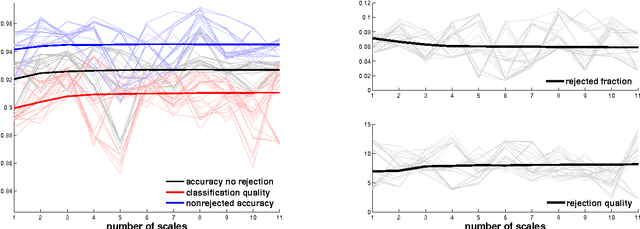
Classifiers with rejection are essential in real-world applications where misclassifications and their effects are critical. However, if no problem specific cost function is defined, there are no established measures to assess the performance of such classifiers. We introduce a set of desired properties for performance measures for classifiers with rejection, based on which we propose a set of three performance measures for the evaluation of the performance of classifiers with rejection that satisfy the desired properties. The nonrejected accuracy measures the ability of the classifier to accurately classify nonrejected samples; the classification quality measures the correct decision making of the classifier with rejector; and the rejection quality measures the ability to concentrate all misclassified samples onto the set of rejected samples. From the measures, we derive the concept of relative optimality that allows us to connect the measures to a family of cost functions that take into account the trade-off between rejection and misclassification. We illustrate the use of the proposed performance measures on classifiers with rejection applied to synthetic and real-world data.
Image Classification with Rejection using Contextual Information
Sep 03, 2015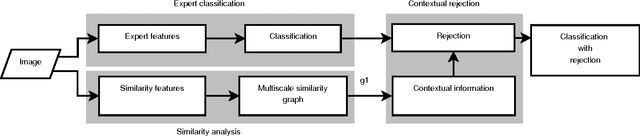
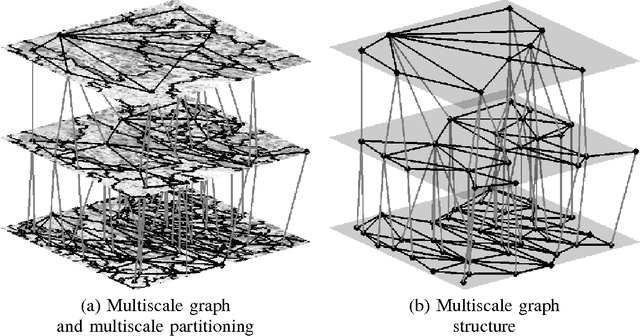
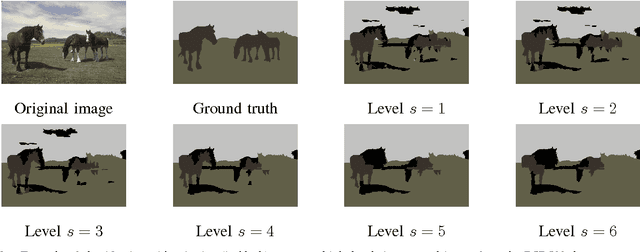
We introduce a new supervised algorithm for image classification with rejection using multiscale contextual information. Rejection is desired in image-classification applications that require a robust classifier but not the classification of the entire image. The proposed algorithm combines local and multiscale contextual information with rejection, improving the classification performance. As a probabilistic model for classification, we adopt a multinomial logistic regression. The concept of rejection with contextual information is implemented by modeling the classification problem as an energy minimization problem over a graph representing local and multiscale similarities of the image. The rejection is introduced through an energy data term associated with the classification risk and the contextual information through an energy smoothness term associated with the local and multiscale similarities within the image. We illustrate the proposed method on the classification of images of H&E-stained teratoma tissues.
Robust hyperspectral image classification with rejection fields
Apr 29, 2015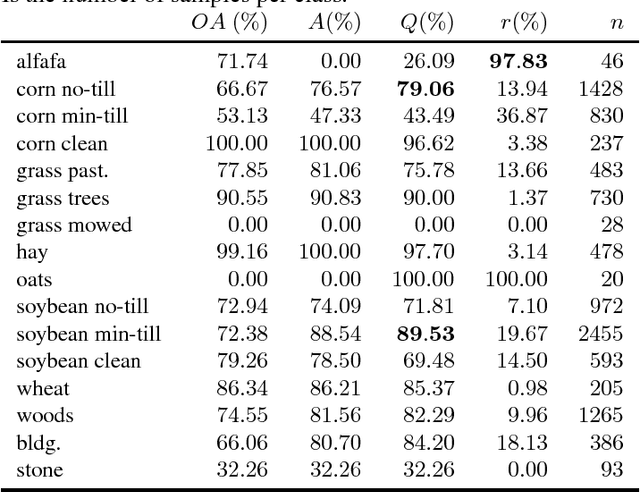
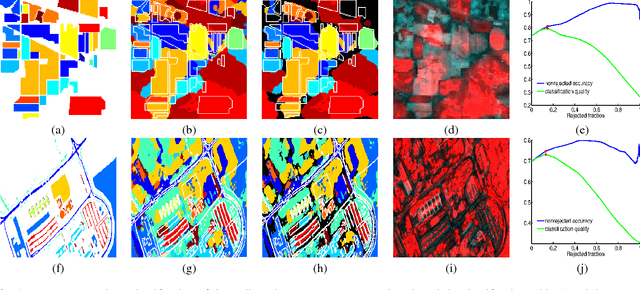

In this paper we present a novel method for robust hyperspectral image classification using context and rejection. Hyperspectral image classification is generally an ill-posed image problem where pixels may belong to unknown classes, and obtaining representative and complete training sets is costly. Furthermore, the need for high classification accuracies is frequently greater than the need to classify the entire image. We approach this problem with a robust classification method that combines classification with context with classification with rejection. A rejection field that will guide the rejection is derived from the classification with contextual information obtained by using the SegSALSA algorithm. We validate our method in real hyperspectral data and show that the performance gains obtained from the rejection fields are equivalent to an increase the dimension of the training sets.
SegSALSA-STR: A convex formulation to supervised hyperspectral image segmentation using hidden fields and structure tensor regularization
Apr 27, 2015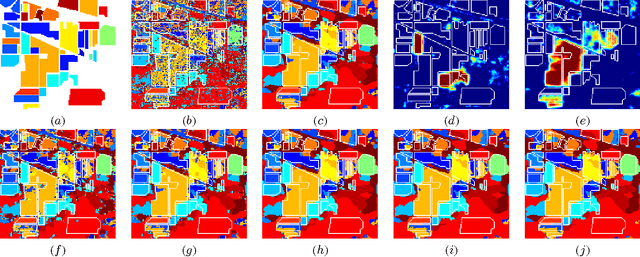
We present a supervised hyperspectral image segmentation algorithm based on a convex formulation of a marginal maximum a posteriori segmentation with hidden fields and structure tensor regularization: Segmentation via the Constraint Split Augmented Lagrangian Shrinkage by Structure Tensor Regularization (SegSALSA-STR). This formulation avoids the generally discrete nature of segmentation problems and the inherent NP-hardness of the integer optimization associated. We extend the Segmentation via the Constraint Split Augmented Lagrangian Shrinkage (SegSALSA) algorithm by generalizing the vectorial total variation prior using a structure tensor prior constructed from a patch-based Jacobian. The resulting algorithm is convex, time-efficient and highly parallelizable. This shows the potential of combining hidden fields with convex optimization through the inclusion of different regularizers. The SegSALSA-STR algorithm is validated in the segmentation of real hyperspectral images.