 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Decoding with Speculative Lookaheads
Dec 09, 2024Constrained decoding with lookahead heuristics (CDLH) is a highly effective method for aligning LLM generations to human preferences. However, the extensive lookahead roll-out operations for each generated token makes CDLH prohibitively expensive, resulting in low adoption in practice. In contrast, common decoding strategies such as greedy decoding are extremely efficient, but achieve very low constraint satisfaction. We propose constrained decoding with speculative lookaheads (CDSL), a technique that significantly improves upon the inference efficiency of CDLH without experiencing the drastic performance reduction seen with greedy decoding. CDSL is motivated by the recently proposed idea of speculative decoding that uses a much smaller draft LLM for generation and a larger target LLM for verification. In CDSL, the draft model is used to generate lookaheads which is verified by a combination of target LLM and task-specific reward functions. This process accelerates decoding by reducing the computational burden while maintaining strong performance. We evaluate CDSL in two constraint decoding tasks with three LLM families and achieve 2.2x to 12.15x speedup over CDLH without significant performance reduction.
KazQAD: Kazakh Open-Domain Question Answering Dataset
Apr 06, 2024



We introduce KazQAD -- a Kazakh open-domain question answering (ODQA) dataset -- that can be used in both reading comprehension and full ODQA settings, as well as for information retrieval experiments. KazQAD contains just under 6,000 unique questions with extracted short answers and nearly 12,000 passage-level relevance judgements. We use a combination of machine translation, Wikipedia search, and in-house manual annotation to ensure annotation efficiency and data quality. The questions come from two sources: translated items from the Natural Questions (NQ) dataset (only for training) and the original Kazakh Unified National Testing (UNT) exam (for development and testing). The accompanying text corpus contains more than 800,000 passages from the Kazakh Wikipedia. As a supplementary dataset, we release around 61,000 question-passage-answer triples from the NQ dataset that have been machine-translated into Kazakh. We develop baseline retrievers and readers that achieve reasonable scores in retrieval (NDCG@10 = 0.389 MRR = 0.382), reading comprehension (EM = 38.5 F1 = 54.2), and full ODQA (EM = 17.8 F1 = 28.7) settings. Nevertheless, these results are substantially lower than state-of-the-art results for English QA collections, and we think that there should still be ample room for improvement. We also show that the current OpenAI's ChatGPTv3.5 is not able to answer KazQAD test questions in the closed-book setting with acceptable quality. The dataset is freely available under the Creative Commons licence (CC BY-SA) at https://github.com/IS2AI/KazQAD.
A Curious Case of Remarkable Resilience to Gradient Attacks via Fully Convolutional and Differentiable Front End with a Skip Connection
Feb 26, 2024We tested front-end enhanced neural models where a frozen classifier was prepended by a differentiable and fully convolutional model with a skip connection. By training them using a small learning rate for about one epoch, we obtained models that retained the accuracy of the backbone classifier while being unusually resistant to gradient attacks including APGD and FAB-T attacks from the AutoAttack package, which we attributed to gradient masking. The gradient masking phenomenon is not new, but the degree of masking was quite remarkable for fully differentiable models that did not have gradient-shattering components such as JPEG compression or components that are expected to cause diminishing gradients. Though black box attacks can be partially effective against gradient masking, they are easily defeated by combining models into randomized ensembles. We estimate that such ensembles achieve near-SOTA AutoAttack accuracy on CIFAR10, CIFAR100, and ImageNet despite having virtually zero accuracy under adaptive attacks. Adversarial training of the backbone classifier can further increase resistance of the front-end enhanced model to gradient attacks. On CIFAR10, the respective randomized ensemble achieved 90.8$\pm 2.5$% (99% CI) accuracy under AutoAttack while having only 18.2$\pm 3.6$% accuracy under the adaptive attack. We do not establish SOTA in adversarial robustness. Instead, we make methodological contributions and further supports the thesis that adaptive attacks designed with the complete knowledge of model architecture are crucial in demonstrating model robustness and that even the so-called white-box gradient attacks can have limited applicability. Although gradient attacks can be complemented with black-box attack such as the SQUARE attack or the zero-order PGD, black-box attacks can be weak against randomized ensembles, e.g., when ensemble models mask gradients.
InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers
Jan 08, 2023We carried out a reproducibility study of InPars recipe for unsupervised training of neural rankers. As a by-product of this study, we developed a simple-yet-effective modification of InPars, which we called InPars-light. Unlike InPars, InPars-light uses only a freely available language model BLOOM and 7x-100x smaller ranking models. On all five English retrieval collections (used in the original InPars study) we obtained substantial (7-30%) and statistically significant improvements over BM25 in nDCG or MRR using only a 30M parameter six-layer MiniLM ranker. In contrast, in the InPars study only a 100x larger MonoT5-3B model consistently outperformed BM25, whereas their smaller MonoT5-220M model (which is still 7x larger than our MiniLM ranker), outperformed BM25 only on MS MARCO and TREC DL 2020. In a purely unsupervised setting, our 435M parameter DeBERTA v3 ranker was roughly at par with the 7x larger MonoT5-3B: In fact, on three out of five datasets, it slightly outperformed MonoT5-3B. Finally, these good results were achieved by re-ranking only 100 candidate documents compared to 1000 used in InPars. We believe that InPars-light is the first truly cost-effective prompt-based unsupervised recipe to train and deploy neural ranking models that outperform BM25.
Understanding Performance of Long-Document Ranking Models through Comprehensive Evaluation and Leaderboarding
Jul 04, 2022
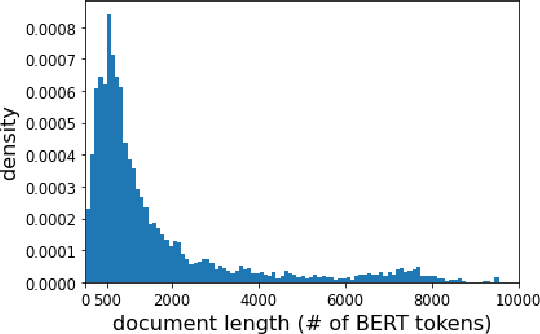
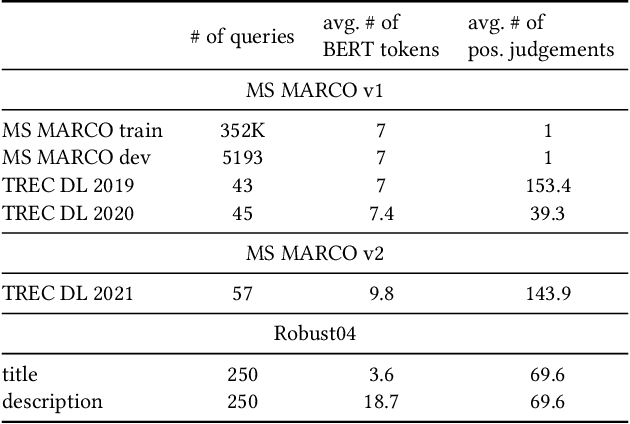
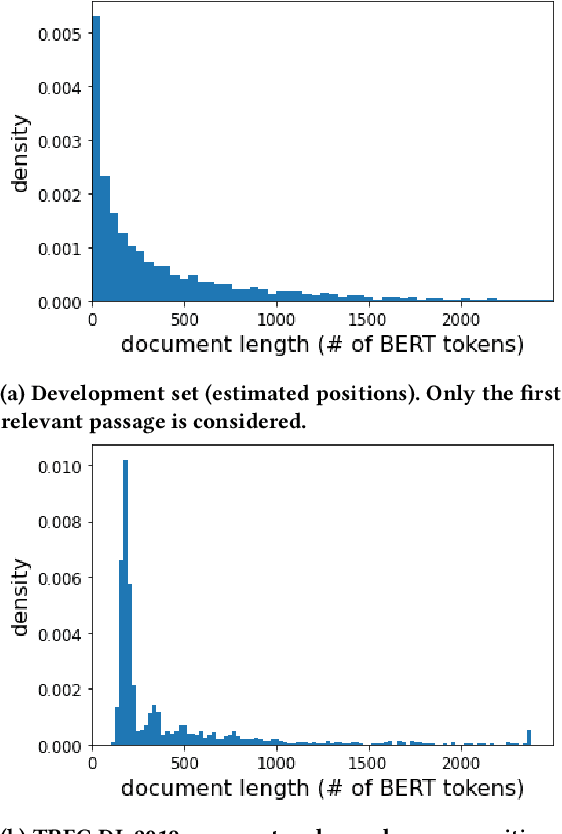
We carry out a comprehensive evaluation of 13 recent models for ranking of long documents using two popular collections (MS MARCO documents and Robust04). Our model zoo includes two specialized Transformer models (such as Longformer) that can process long documents without the need to split them. Along the way, we document several difficulties regarding training and comparing such models. Somewhat surprisingly, we find the simple FirstP baseline (truncating documents to satisfy the input-sequence constraint of a typical Transformer model) to be quite effective. We analyze the distribution of relevant passages (inside documents) to explain this phenomenon. We further argue that, despite their widespread use, Robust04 and MS MARCO documents are not particularly useful for benchmarking of long-document models.
Smooth-Reduce: Leveraging Patches for Improved Certified Robustness
May 12, 2022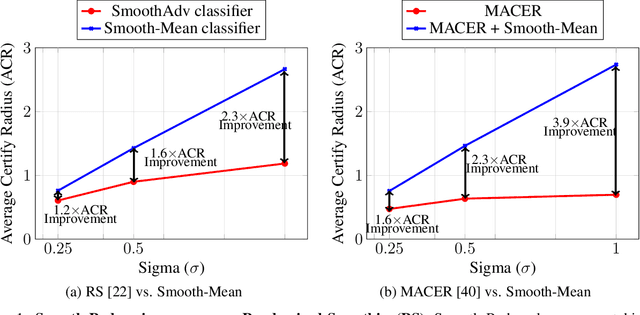
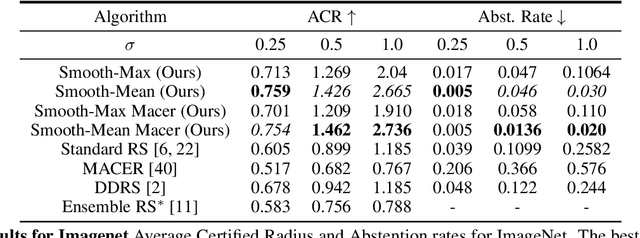
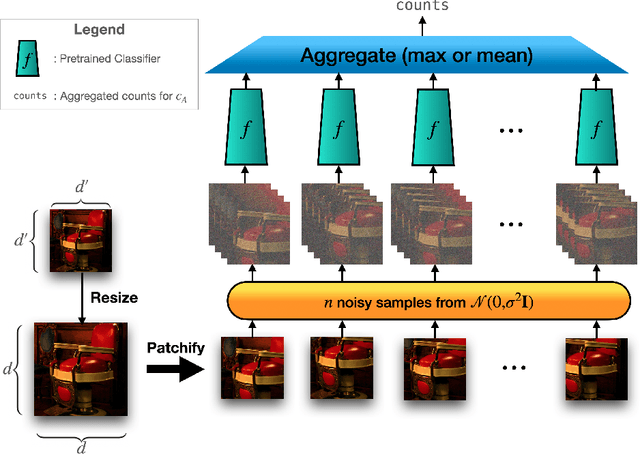
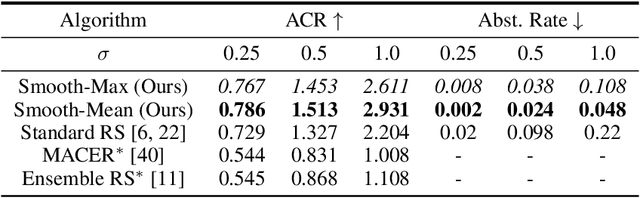
Randomized smoothing (RS) has been shown to be a fast, scalable technique for certifying the robustness of deep neural network classifiers. However, methods based on RS require augmenting data with large amounts of noise, which leads to significant drops in accuracy. We propose a training-free, modified smoothing approach, Smooth-Reduce, that leverages patching and aggregation to provide improved classifier certificates. Our algorithm classifies overlapping patches extracted from an input image, and aggregates the predicted logits to certify a larger radius around the input. We study two aggregation schemes -- max and mean -- and show that both approaches provide better certificates in terms of certified accuracy, average certified radii and abstention rates as compared to concurrent approaches. We also provide theoretical guarantees for such certificates, and empirically show significant improvements over other randomized smoothing methods that require expensive retraining. Further, we extend our approach to videos and provide meaningful certificates for video classifiers. A project page can be found at https://nyu-dice-lab.github.io/SmoothReduce/
The Impact of Cross-Lingual Adjustment of Contextual Word Representations on Zero-Shot Transfer
Apr 13, 2022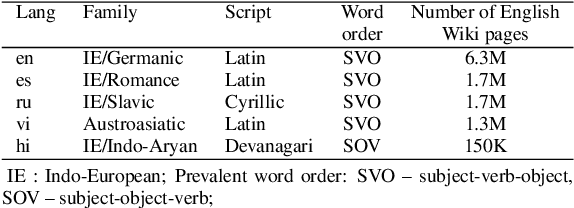
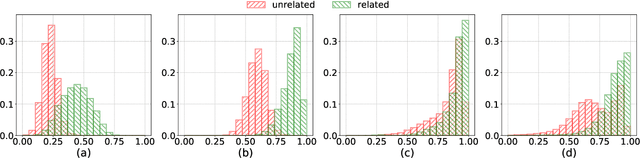

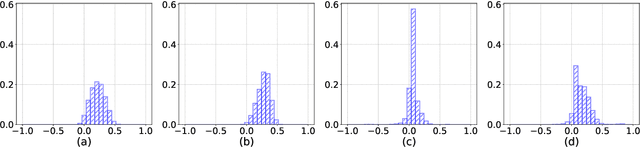
Large pre-trained multilingual models such as mBERT and XLM-R enabled effective cross-lingual zero-shot transfer in many NLP tasks. A cross-lingual adjustment of these models using a small parallel corpus can potentially further improve results. This is a more data efficient method compared to training a machine-translation system or a multi-lingual model from scratch using only parallel data. In this study, we experiment with zero-shot transfer of English models to four typologically different languages (Spanish, Russian, Vietnamese, and Hindi) and three NLP tasks (QA, NLI, and NER). We carry out a cross-lingual adjustment of an off-the-shelf mBERT model. We confirm prior finding that this adjustment makes embeddings of semantically similar words from different languages closer to each other, while keeping unrelated words apart. However, from the paired-differences histograms introduced in our work we can see that the adjustment only modestly affects the relative distances between related and unrelated words. In contrast, fine-tuning of mBERT on English data (for a specific task such as NER) draws embeddings of both related and unrelated words closer to each other. The cross-lingual adjustment of mBERT improves NLI in four languages and NER in two languages, while QA performance never improves and sometimes degrades. When we fine-tune a cross-lingual adjusted mBERT for a specific task (e.g., NLI), the cross-lingual adjustment of mBERT may still improve the separation between related and related words, but this works consistently only for the XNLI task. Our study contributes to a better understanding of cross-lingual transfer capabilities of large multilingual language models and of effectiveness of their cross-lingual adjustment in various NLP tasks.
A Systematic Evaluation of Transfer Learning and Pseudo-labeling with BERT-based Ranking Models
Mar 11, 2021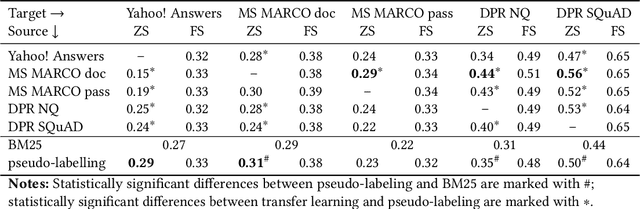

Due to high annotation costs, making the best use of existing human-created training data is an important research direction. We, therefore, carry out a systematic evaluation of transferability of BERT-based neural ranking models across five English datasets. Previous studies focused primarily on zero-shot and few-shot transfer from a large dataset to a dataset with a small number of queries. In contrast, each of our collections has a substantial number of queries, which enables a full-shot evaluation mode and improves reliability of our results. Furthermore, since source datasets licences often prohibit commercial use, we compare transfer learning to training on pseudo-labels generated by a BM25 scorer. We find that training on pseudo-labels -- possibly with subsequent fine-tuning using a modest number of annotated queries -- can produce a competitive or better model compared to transfer learning. However, there is a need to improve the stability and/or effectiveness of the few-shot training, which, in some cases, can degrade performance of a pretrained model.
Exploring Classic and Neural Lexical Translation Models for Information Retrieval: Interpretability, Effectiveness, and Efficiency Benefits
Feb 12, 2021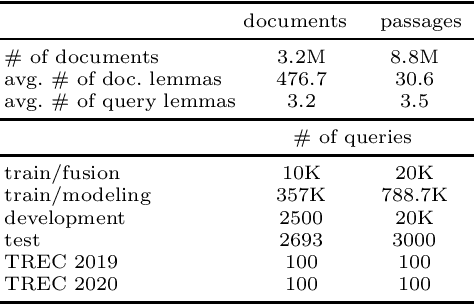
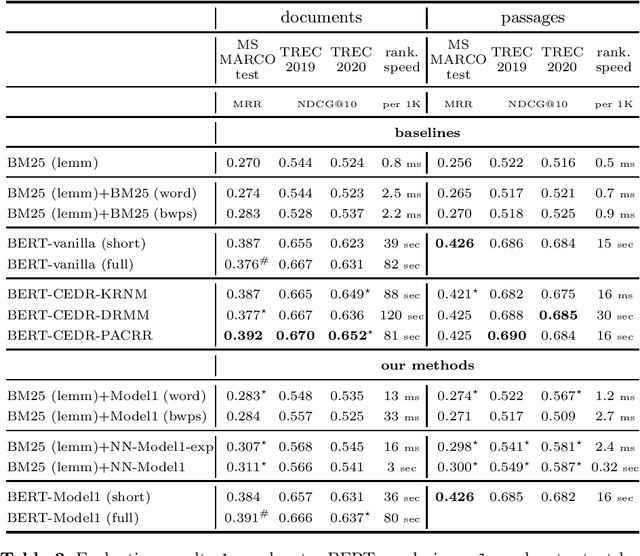
We study the utility of the lexical translation model (IBM Model 1) for English text retrieval, in particular, its neural variants that are trained end-to-end. We use the neural Model1 as an aggregator layer applied to context-free or contextualized query/document embeddings. This new approach to design a neural ranking system has benefits for effectiveness, efficiency, and interpretability. Specifically, we show that adding an interpretable neural Model 1 layer on top of BERT-based contextualized embeddings (1) does not decrease accuracy and/or efficiency; and (2) may overcome the limitation on the maximum sequence length of existing BERT models. The context-free neural Model 1 is less effective than a BERT-based ranking model, but it can run efficiently on a CPU (without expensive index-time precomputation or query-time operations on large tensors). Using Model 1 we produced best neural and non-neural runs on the MS MARCO document ranking leaderboard in late 2020.
Traditional IR rivals neural models on the MS~MARCO Document Ranking Leaderboard
Dec 19, 2020This short document describes a traditional IR system that achieved MRR@100 equal to 0.298 on the MS MARCO Document Ranking leaderboard (on 2020-12-06). Although inferior to most BERT-based models, it outperformed several neural runs (as well as all non-neural ones), including two submissions that used a large pretrained Transformer model for re-ranking. We provide software and data to reproduce our results.