 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Federated Fraud Detection in Payment Transactions with NVIDIA FLARE
Mar 13, 2026Fraud-related financial losses continue to rise, while regulatory, privacy, and data-sovereignty constraints increasingly limit the feasibility of centralized fraud detection systems. Federated Learning (FL) has emerged as a promising paradigm for enabling collaborative model training across institutions without sharing raw transaction data. Yet, its practical effectiveness under realistic, non-IID financial data distributions remains insufficiently validated. In this work, we present a multi-institution, industry-oriented proof-of-concept study evaluating federated anomaly detection for payment transactions using the NVIDIA FLARE framework. We simulate a realistic federation of heterogeneous financial institutions, each observing distinct fraud typologies and operating under strict data isolation. Using a deep neural network trained via federated averaging (FedAvg), we demonstrate that federated models achieve a mean F1-score of 0.903 - substantially outperforming locally trained models (0.643) and closely approaching centralized training performance (0.925), while preserving full data sovereignty. We further analyze convergence behavior, showing that strong performance is achieved within 10 federated communication rounds, highlighting the operational viability of FL in latency- and cost-sensitive financial environments. To support deployment in regulated settings, we evaluate model interpretability using Shapley-based feature attribution and confirm that federated models rely on semantically coherent, domain-relevant decision signals. Finally, we incorporate sample-level differential privacy via DP-SGD and demonstrate favorable privacy-utility trade-offs...
Scaling Speech Technology to 1,000+ Languages
May 22, 2023Expanding the language coverage of speech technology has the potential to improve access to information for many more people. However, current speech technology is restricted to about one hundred languages which is a small fraction of the over 7,000 languages spoken around the world. The Massively Multilingual Speech (MMS) project increases the number of supported languages by 10-40x, depending on the task. The main ingredients are a new dataset based on readings of publicly available religious texts and effectively leveraging self-supervised learning. We built pre-trained wav2vec 2.0 models covering 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for the same number of languages, as well as a language identification model for 4,017 languages. Experiments show that our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark while being trained on a small fraction of the labeled data.
InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers
Jan 08, 2023We carried out a reproducibility study of InPars recipe for unsupervised training of neural rankers. As a by-product of this study, we developed a simple-yet-effective modification of InPars, which we called InPars-light. Unlike InPars, InPars-light uses only a freely available language model BLOOM and 7x-100x smaller ranking models. On all five English retrieval collections (used in the original InPars study) we obtained substantial (7-30%) and statistically significant improvements over BM25 in nDCG or MRR using only a 30M parameter six-layer MiniLM ranker. In contrast, in the InPars study only a 100x larger MonoT5-3B model consistently outperformed BM25, whereas their smaller MonoT5-220M model (which is still 7x larger than our MiniLM ranker), outperformed BM25 only on MS MARCO and TREC DL 2020. In a purely unsupervised setting, our 435M parameter DeBERTA v3 ranker was roughly at par with the 7x larger MonoT5-3B: In fact, on three out of five datasets, it slightly outperformed MonoT5-3B. Finally, these good results were achieved by re-ranking only 100 candidate documents compared to 1000 used in InPars. We believe that InPars-light is the first truly cost-effective prompt-based unsupervised recipe to train and deploy neural ranking models that outperform BM25.
Exploring Hate Speech Detection with HateXplain and BERT
Aug 09, 2022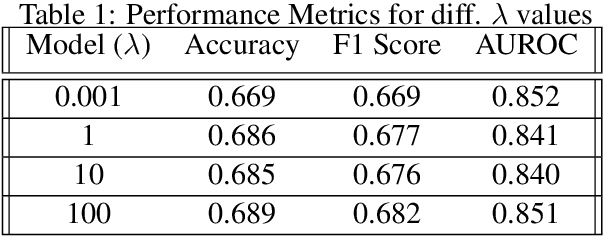
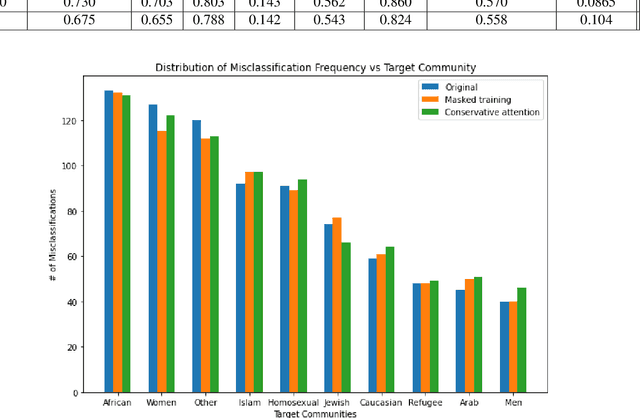
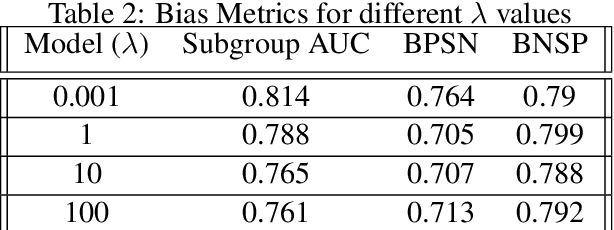
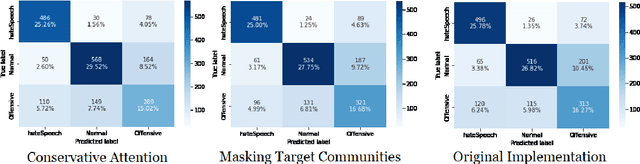
Hate Speech takes many forms to target communities with derogatory comments, and takes humanity a step back in societal progress. HateXplain is a recently published and first dataset to use annotated spans in the form of rationales, along with speech classification categories and targeted communities to make the classification more humanlike, explainable, accurate and less biased. We tune BERT to perform this task in the form of rationales and class prediction, and compare our performance on different metrics spanning across accuracy, explainability and bias. Our novelty is threefold. Firstly, we experiment with the amalgamated rationale class loss with different importance values. Secondly, we experiment extensively with the ground truth attention values for the rationales. With the introduction of conservative and lenient attentions, we compare performance of the model on HateXplain and test our hypothesis. Thirdly, in order to improve the unintended bias in our models, we use masking of the target community words and note the improvement in bias and explainability metrics. Overall, we are successful in achieving model explanability, bias removal and several incremental improvements on the original BERT implementation.