 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Hate Speech Detection with HateXplain and BERT
Paper and Code
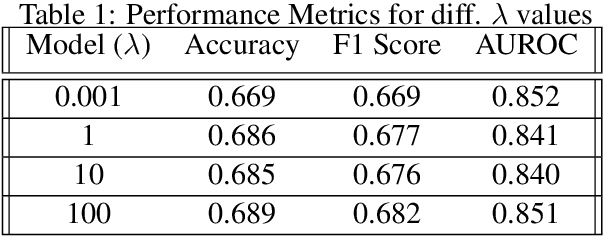
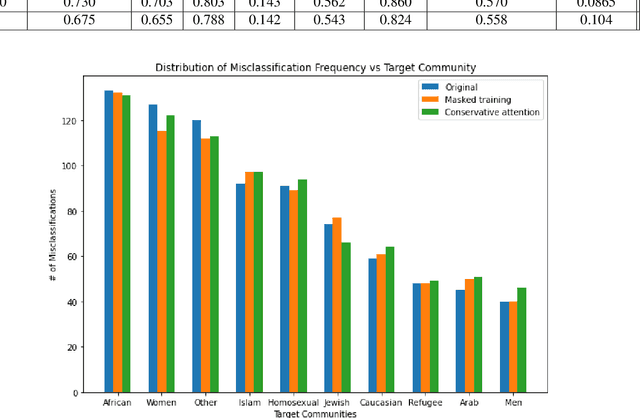
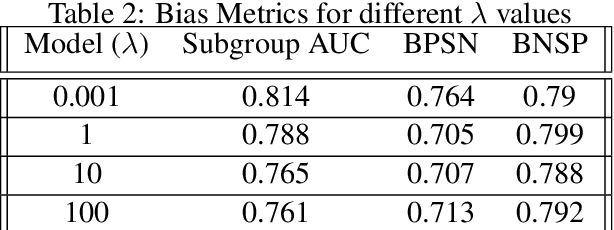
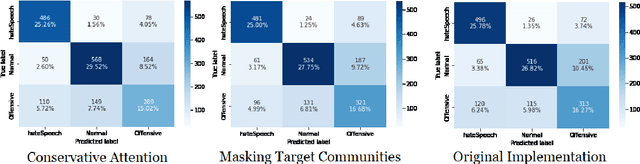
Hate Speech takes many forms to target communities with derogatory comments, and takes humanity a step back in societal progress. HateXplain is a recently published and first dataset to use annotated spans in the form of rationales, along with speech classification categories and targeted communities to make the classification more humanlike, explainable, accurate and less biased. We tune BERT to perform this task in the form of rationales and class prediction, and compare our performance on different metrics spanning across accuracy, explainability and bias. Our novelty is threefold. Firstly, we experiment with the amalgamated rationale class loss with different importance values. Secondly, we experiment extensively with the ground truth attention values for the rationales. With the introduction of conservative and lenient attentions, we compare performance of the model on HateXplain and test our hypothesis. Thirdly, in order to improve the unintended bias in our models, we use masking of the target community words and note the improvement in bias and explainability metrics. Overall, we are successful in achieving model explanability, bias removal and several incremental improvements on the original BERT implementation.