 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGamayun's Path to Multilingual Mastery: Cost-Efficient Training of a 1.5B-Parameter LLM
Dec 25, 2025We present Gamayun, a 1.5B-parameter multilingual language model trained entirely from scratch on 2.5T tokens. Designed for efficiency and deployment in resource-constrained environments, Gamayun addresses the lack of research on small non-English-centric LLMs by adopting a novel two-stage pre-training strategy: balanced multilingual training for cross-lingual alignment, followed by high-quality English enrichment to transfer performance gains across languages. Our model supports 12 languages, with special focus on Russian. Despite a significantly smaller training budget than comparable models, Gamayun outperforms LLaMA3.2-1B (9T tokens) on all considered benchmarks, and surpasses Qwen2.5-1.5B (18T tokens) on a wide range of English and multilingual tasks. It matches or exceeds Qwen3 (36T tokens) on most tasks outside advanced STEM, achieving state-of-the-art results in Russian, including the MERA benchmark, among the models of comparable size (1-2B parameters).
KazQAD: Kazakh Open-Domain Question Answering Dataset
Apr 06, 2024



We introduce KazQAD -- a Kazakh open-domain question answering (ODQA) dataset -- that can be used in both reading comprehension and full ODQA settings, as well as for information retrieval experiments. KazQAD contains just under 6,000 unique questions with extracted short answers and nearly 12,000 passage-level relevance judgements. We use a combination of machine translation, Wikipedia search, and in-house manual annotation to ensure annotation efficiency and data quality. The questions come from two sources: translated items from the Natural Questions (NQ) dataset (only for training) and the original Kazakh Unified National Testing (UNT) exam (for development and testing). The accompanying text corpus contains more than 800,000 passages from the Kazakh Wikipedia. As a supplementary dataset, we release around 61,000 question-passage-answer triples from the NQ dataset that have been machine-translated into Kazakh. We develop baseline retrievers and readers that achieve reasonable scores in retrieval (NDCG@10 = 0.389 MRR = 0.382), reading comprehension (EM = 38.5 F1 = 54.2), and full ODQA (EM = 17.8 F1 = 28.7) settings. Nevertheless, these results are substantially lower than state-of-the-art results for English QA collections, and we think that there should still be ample room for improvement. We also show that the current OpenAI's ChatGPTv3.5 is not able to answer KazQAD test questions in the closed-book setting with acceptable quality. The dataset is freely available under the Creative Commons licence (CC BY-SA) at https://github.com/IS2AI/KazQAD.
The Impact of Cross-Lingual Adjustment of Contextual Word Representations on Zero-Shot Transfer
Apr 13, 2022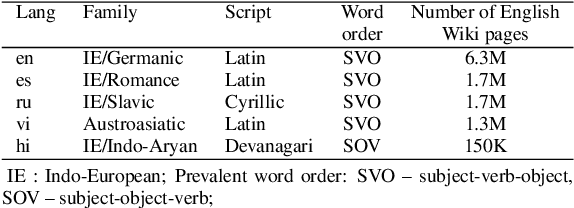
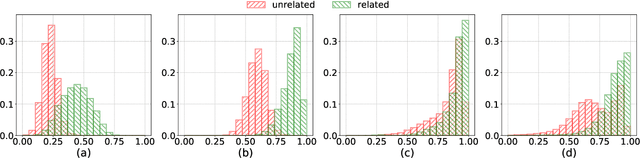

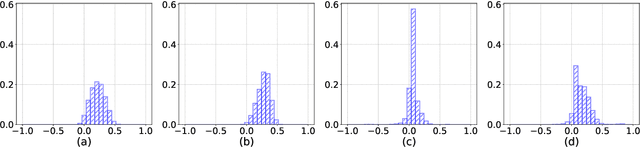
Large pre-trained multilingual models such as mBERT and XLM-R enabled effective cross-lingual zero-shot transfer in many NLP tasks. A cross-lingual adjustment of these models using a small parallel corpus can potentially further improve results. This is a more data efficient method compared to training a machine-translation system or a multi-lingual model from scratch using only parallel data. In this study, we experiment with zero-shot transfer of English models to four typologically different languages (Spanish, Russian, Vietnamese, and Hindi) and three NLP tasks (QA, NLI, and NER). We carry out a cross-lingual adjustment of an off-the-shelf mBERT model. We confirm prior finding that this adjustment makes embeddings of semantically similar words from different languages closer to each other, while keeping unrelated words apart. However, from the paired-differences histograms introduced in our work we can see that the adjustment only modestly affects the relative distances between related and unrelated words. In contrast, fine-tuning of mBERT on English data (for a specific task such as NER) draws embeddings of both related and unrelated words closer to each other. The cross-lingual adjustment of mBERT improves NLI in four languages and NER in two languages, while QA performance never improves and sometimes degrades. When we fine-tune a cross-lingual adjusted mBERT for a specific task (e.g., NLI), the cross-lingual adjustment of mBERT may still improve the separation between related and related words, but this works consistently only for the XNLI task. Our study contributes to a better understanding of cross-lingual transfer capabilities of large multilingual language models and of effectiveness of their cross-lingual adjustment in various NLP tasks.
SberQuAD -- Russian Reading Comprehension Dataset: Description and Analysis
Dec 23, 2019



SberQuAD -- a large scale analog of Stanford SQuAD in the Russian language - is a valuable resource that has not been properly presented to the scientific community. We fill this gap by providing a description, a thorough analysis, and baseline experimental results.