 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKazEmoTTS: A Dataset for Kazakh Emotional Text-to-Speech Synthesis
Apr 09, 2024This study focuses on the creation of the KazEmoTTS dataset, designed for emotional Kazakh text-to-speech (TTS) applications. KazEmoTTS is a collection of 54,760 audio-text pairs, with a total duration of 74.85 hours, featuring 34.23 hours delivered by a female narrator and 40.62 hours by two male narrators. The list of the emotions considered include "neutral", "angry", "happy", "sad", "scared", and "surprised". We also developed a TTS model trained on the KazEmoTTS dataset. Objective and subjective evaluations were employed to assess the quality of synthesized speech, yielding an MCD score within the range of 6.02 to 7.67, alongside a MOS that spanned from 3.51 to 3.57. To facilitate reproducibility and inspire further research, we have made our code, pre-trained model, and dataset accessible in our GitHub repository.
KazSAnDRA: Kazakh Sentiment Analysis Dataset of Reviews and Attitudes
Apr 09, 2024



This paper presents KazSAnDRA, a dataset developed for Kazakh sentiment analysis that is the first and largest publicly available dataset of its kind. KazSAnDRA comprises an extensive collection of 180,064 reviews obtained from various sources and includes numerical ratings ranging from 1 to 5, providing a quantitative representation of customer attitudes. The study also pursued the automation of Kazakh sentiment classification through the development and evaluation of four machine learning models trained for both polarity classification and score classification. Experimental analysis included evaluation of the results considering both balanced and imbalanced scenarios. The most successful model attained an F1-score of 0.81 for polarity classification and 0.39 for score classification on the test sets. The dataset and fine-tuned models are open access and available for download under the Creative Commons Attribution 4.0 International License (CC BY 4.0) through our GitHub repository.
KazParC: Kazakh Parallel Corpus for Machine Translation
Apr 09, 2024We introduce KazParC, a parallel corpus designed for machine translation across Kazakh, English, Russian, and Turkish. The first and largest publicly available corpus of its kind, KazParC contains a collection of 371,902 parallel sentences covering different domains and developed with the assistance of human translators. Our research efforts also extend to the development of a neural machine translation model nicknamed Tilmash. Remarkably, the performance of Tilmash is on par with, and in certain instances, surpasses that of industry giants, such as Google Translate and Yandex Translate, as measured by standard evaluation metrics, such as BLEU and chrF. Both KazParC and Tilmash are openly available for download under the Creative Commons Attribution 4.0 International License (CC BY 4.0) through our GitHub repository.
KazQAD: Kazakh Open-Domain Question Answering Dataset
Apr 06, 2024



We introduce KazQAD -- a Kazakh open-domain question answering (ODQA) dataset -- that can be used in both reading comprehension and full ODQA settings, as well as for information retrieval experiments. KazQAD contains just under 6,000 unique questions with extracted short answers and nearly 12,000 passage-level relevance judgements. We use a combination of machine translation, Wikipedia search, and in-house manual annotation to ensure annotation efficiency and data quality. The questions come from two sources: translated items from the Natural Questions (NQ) dataset (only for training) and the original Kazakh Unified National Testing (UNT) exam (for development and testing). The accompanying text corpus contains more than 800,000 passages from the Kazakh Wikipedia. As a supplementary dataset, we release around 61,000 question-passage-answer triples from the NQ dataset that have been machine-translated into Kazakh. We develop baseline retrievers and readers that achieve reasonable scores in retrieval (NDCG@10 = 0.389 MRR = 0.382), reading comprehension (EM = 38.5 F1 = 54.2), and full ODQA (EM = 17.8 F1 = 28.7) settings. Nevertheless, these results are substantially lower than state-of-the-art results for English QA collections, and we think that there should still be ample room for improvement. We also show that the current OpenAI's ChatGPTv3.5 is not able to answer KazQAD test questions in the closed-book setting with acceptable quality. The dataset is freely available under the Creative Commons licence (CC BY-SA) at https://github.com/IS2AI/KazQAD.
Multilingual Text-to-Speech Synthesis for Turkic Languages Using Transliteration
May 25, 2023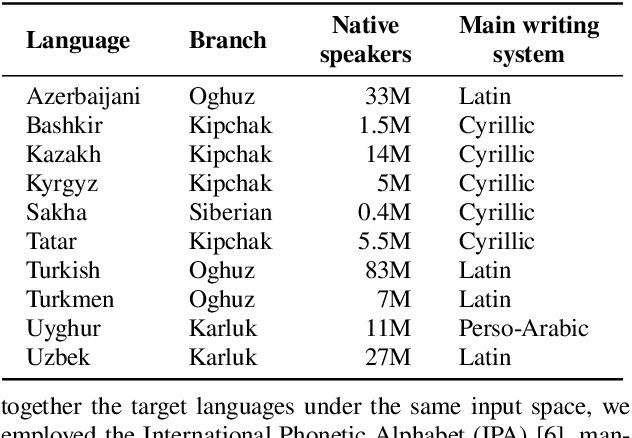
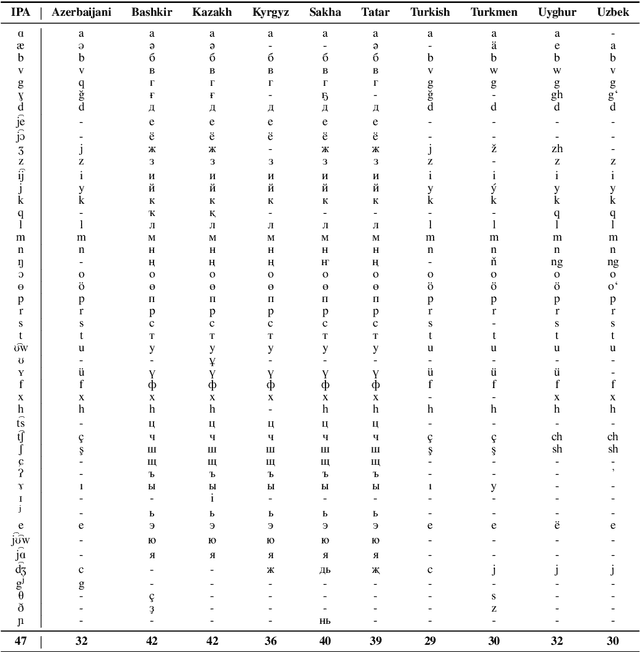
This work aims to build a multilingual text-to-speech (TTS) synthesis system for ten lower-resourced Turkic languages: Azerbaijani, Bashkir, Kazakh, Kyrgyz, Sakha, Tatar, Turkish, Turkmen, Uyghur, and Uzbek. We specifically target the zero-shot learning scenario, where a TTS model trained using the data of one language is applied to synthesise speech for other, unseen languages. An end-to-end TTS system based on the Tacotron 2 architecture was trained using only the available data of the Kazakh language. To generate speech for the other Turkic languages, we first mapped the letters of the Turkic alphabets onto the symbols of the International Phonetic Alphabet (IPA), which were then converted to the Kazakh alphabet letters. To demonstrate the feasibility of the proposed approach, we evaluated the multilingual Turkic TTS model subjectively and obtained promising results. To enable replication of the experiments, we make our code and dataset publicly available in our GitHub repository.
KazNERD: Kazakh Named Entity Recognition Dataset
Nov 26, 2021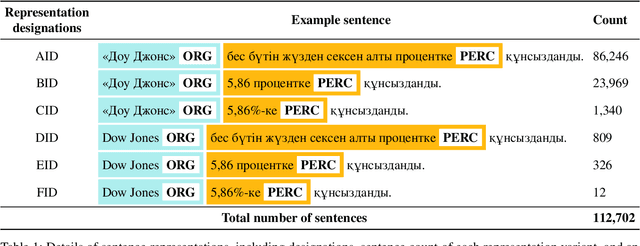


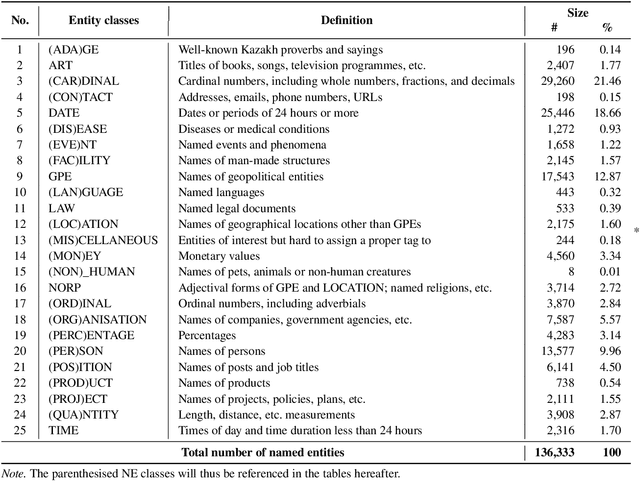
We present the development of a dataset for Kazakh named entity recognition. The dataset was built as there is a clear need for publicly available annotated corpora in Kazakh, as well as annotation guidelines containing straightforward--but rigorous--rules and examples. The dataset annotation, based on the IOB2 scheme, was carried out on television news text by two native Kazakh speakers under the supervision of the first author. The resulting dataset contains 112,702 sentences and 136,333 annotations for 25 entity classes. State-of-the-art machine learning models to automatise Kazakh named entity recognition were also built, with the best-performing model achieving an exact match F1-score of 97.22% on the test set. The annotated dataset, guidelines, and codes used to train the models are freely available for download under the CC BY 4.0 licence from https://github.com/IS2AI/KazNERD.