 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKazSAnDRA: Kazakh Sentiment Analysis Dataset of Reviews and Attitudes
Apr 09, 2024



This paper presents KazSAnDRA, a dataset developed for Kazakh sentiment analysis that is the first and largest publicly available dataset of its kind. KazSAnDRA comprises an extensive collection of 180,064 reviews obtained from various sources and includes numerical ratings ranging from 1 to 5, providing a quantitative representation of customer attitudes. The study also pursued the automation of Kazakh sentiment classification through the development and evaluation of four machine learning models trained for both polarity classification and score classification. Experimental analysis included evaluation of the results considering both balanced and imbalanced scenarios. The most successful model attained an F1-score of 0.81 for polarity classification and 0.39 for score classification on the test sets. The dataset and fine-tuned models are open access and available for download under the Creative Commons Attribution 4.0 International License (CC BY 4.0) through our GitHub repository.
KazEmoTTS: A Dataset for Kazakh Emotional Text-to-Speech Synthesis
Apr 09, 2024This study focuses on the creation of the KazEmoTTS dataset, designed for emotional Kazakh text-to-speech (TTS) applications. KazEmoTTS is a collection of 54,760 audio-text pairs, with a total duration of 74.85 hours, featuring 34.23 hours delivered by a female narrator and 40.62 hours by two male narrators. The list of the emotions considered include "neutral", "angry", "happy", "sad", "scared", and "surprised". We also developed a TTS model trained on the KazEmoTTS dataset. Objective and subjective evaluations were employed to assess the quality of synthesized speech, yielding an MCD score within the range of 6.02 to 7.67, alongside a MOS that spanned from 3.51 to 3.57. To facilitate reproducibility and inspire further research, we have made our code, pre-trained model, and dataset accessible in our GitHub repository.
KazParC: Kazakh Parallel Corpus for Machine Translation
Apr 09, 2024We introduce KazParC, a parallel corpus designed for machine translation across Kazakh, English, Russian, and Turkish. The first and largest publicly available corpus of its kind, KazParC contains a collection of 371,902 parallel sentences covering different domains and developed with the assistance of human translators. Our research efforts also extend to the development of a neural machine translation model nicknamed Tilmash. Remarkably, the performance of Tilmash is on par with, and in certain instances, surpasses that of industry giants, such as Google Translate and Yandex Translate, as measured by standard evaluation metrics, such as BLEU and chrF. Both KazParC and Tilmash are openly available for download under the Creative Commons Attribution 4.0 International License (CC BY 4.0) through our GitHub repository.
A Central Asian Food Dataset for Personalized Dietary Interventions, Extended Abstract
May 12, 2023



Nowadays, it is common for people to take photographs of every beverage, snack, or meal they eat and then post these photographs on social media platforms. Leveraging these social trends, real-time food recognition and reliable classification of these captured food images can potentially help replace some of the tedious recording and coding of food diaries to enable personalized dietary interventions. Although Central Asian cuisine is culturally and historically distinct, there has been little published data on the food and dietary habits of people in this region. To fill this gap, we aim to create a reliable dataset of regional foods that is easily accessible to both public consumers and researchers. To the best of our knowledge, this is the first work on creating a Central Asian Food Dataset (CAFD). The final dataset contains 42 food categories and over 16,000 images of national dishes unique to this region. We achieved a classification accuracy of 88.70\% (42 classes) on the CAFD using the ResNet152 neural network model. The food recognition models trained on the CAFD demonstrate computer vision's effectiveness and high accuracy for dietary assessment.
KazakhTTS2: Extending the Open-Source Kazakh TTS Corpus With More Data, Speakers, and Topics
Jan 15, 2022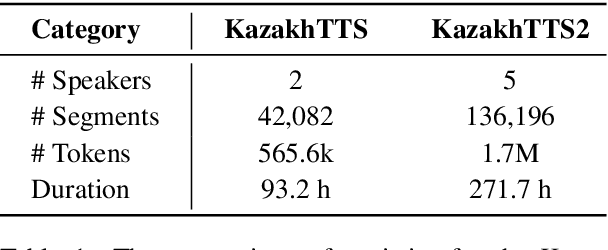
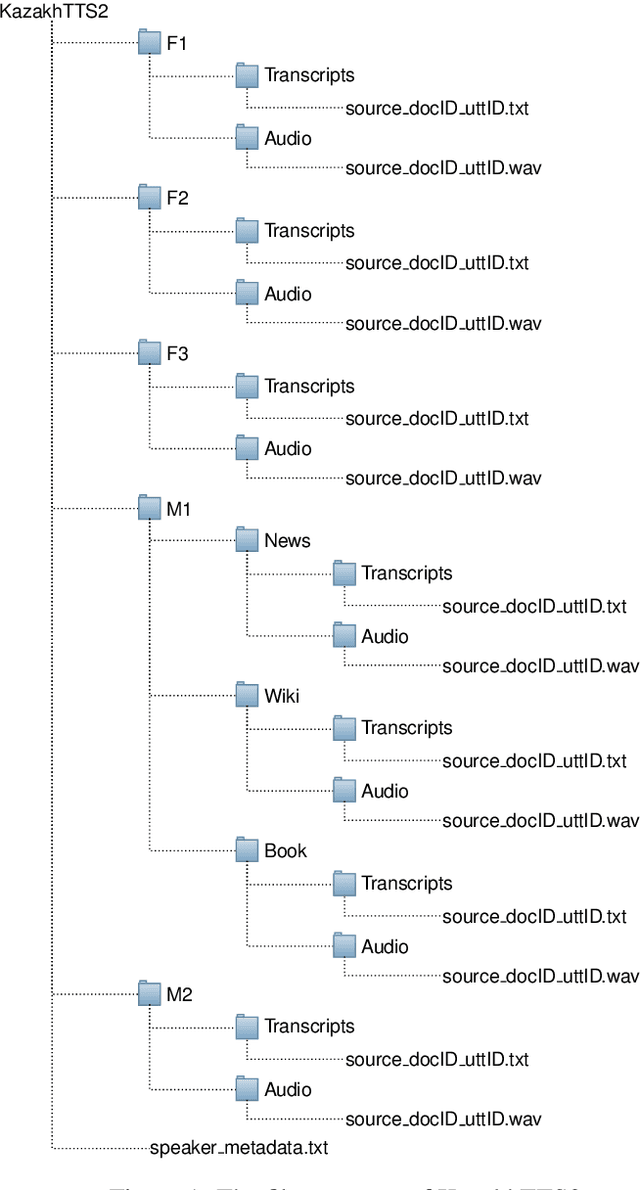
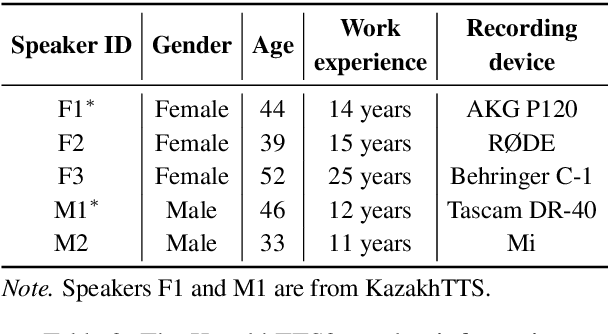
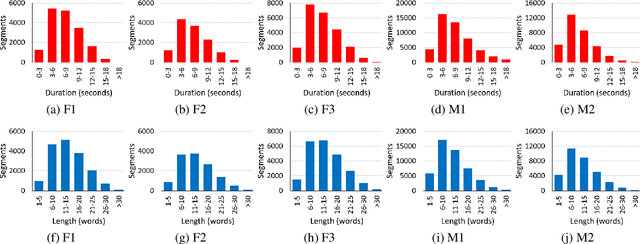
We present an expanded version of our previously released Kazakh text-to-speech (KazakhTTS) synthesis corpus. In the new KazakhTTS2 corpus, the overall size is increased from 93 hours to 271 hours, the number of speakers has risen from two to five (three females and two males), and the topic coverage is diversified with the help of new sources, including a book and Wikipedia articles. This corpus is necessary for building high-quality TTS systems for Kazakh, a Central Asian agglutinative language from the Turkic family, which presents several linguistic challenges. We describe the corpus construction process and provide the details of the training and evaluation procedures for the TTS system. Our experimental results indicate that the constructed corpus is sufficient to build robust TTS models for real-world applications, with a subjective mean opinion score of above 4.0 for all the five speakers. We believe that our corpus will facilitate speech and language research for Kazakh and other Turkic languages, which are widely considered to be low-resource due to the limited availability of free linguistic data. The constructed corpus, code, and pretrained models are publicly available in our GitHub repository.
KazNERD: Kazakh Named Entity Recognition Dataset
Nov 26, 2021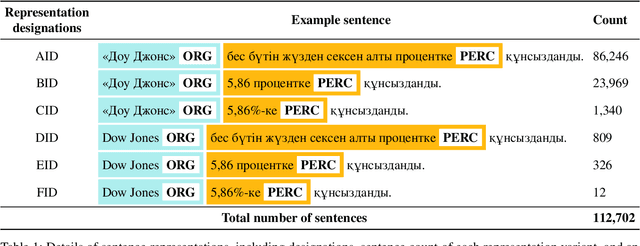


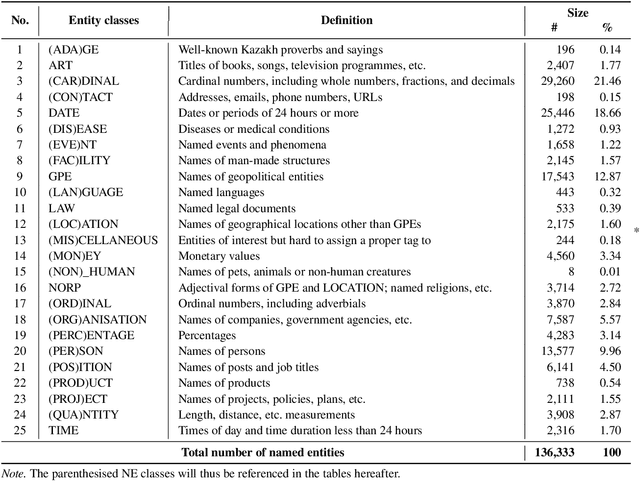
We present the development of a dataset for Kazakh named entity recognition. The dataset was built as there is a clear need for publicly available annotated corpora in Kazakh, as well as annotation guidelines containing straightforward--but rigorous--rules and examples. The dataset annotation, based on the IOB2 scheme, was carried out on television news text by two native Kazakh speakers under the supervision of the first author. The resulting dataset contains 112,702 sentences and 136,333 annotations for 25 entity classes. State-of-the-art machine learning models to automatise Kazakh named entity recognition were also built, with the best-performing model achieving an exact match F1-score of 97.22% on the test set. The annotated dataset, guidelines, and codes used to train the models are freely available for download under the CC BY 4.0 licence from https://github.com/IS2AI/KazNERD.
A Study of Multimodal Person Verification Using Audio-Visual-Thermal Data
Oct 23, 2021
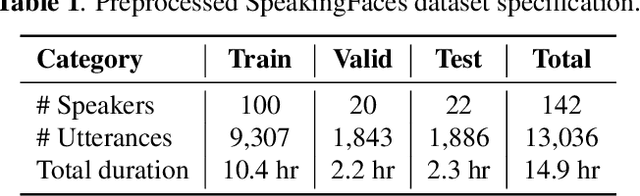
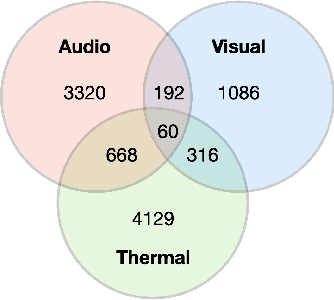
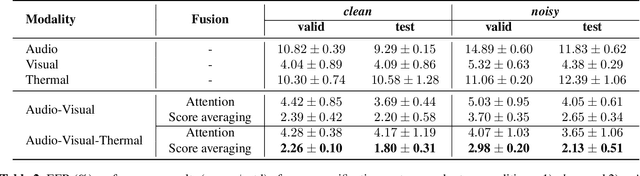
In this paper, we study an approach to multimodal person verification using audio, visual, and thermal modalities. The combination of audio and visual modalities has already been shown to be effective for robust person verification. From this perspective, we investigate the impact of further increasing the number of modalities by supplementing thermal images. In particular, we implemented unimodal, bimodal, and trimodal verification systems using the state-of-the-art deep learning architectures and compared their performance under clean and noisy conditions. We also compared two popular fusion approaches based on simple score averaging and soft attention mechanism. The experiment conducted on the SpeakingFaces dataset demonstrates the superiority of the trimodal verification system over both unimodal and bimodal systems. To enable the reproducibility of the experiment and facilitate research into multimodal person verification, we make our code, pretrained models and preprocessed dataset freely available in our GitHub repository.
A Study of Multilingual End-to-End Speech Recognition for Kazakh, Russian, and English
Aug 03, 2021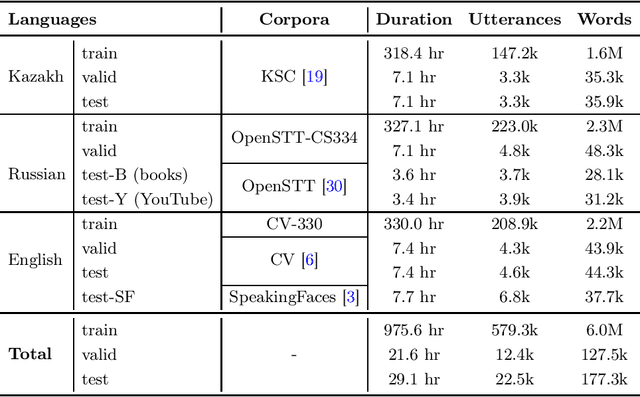
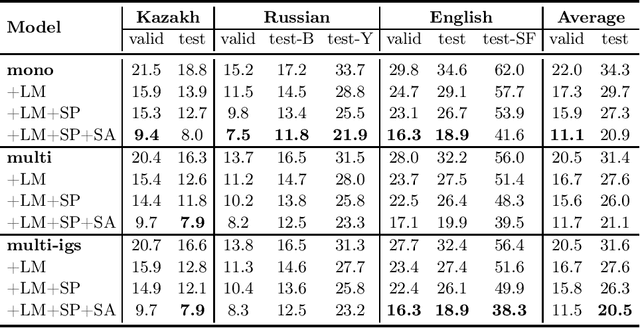

We study training a single end-to-end (E2E) automatic speech recognition (ASR) model for three languages used in Kazakhstan: Kazakh, Russian, and English. We first describe the development of multilingual E2E ASR based on Transformer networks and then perform an extensive assessment on the aforementioned languages. We also compare two variants of output grapheme set construction: combined and independent. Furthermore, we evaluate the impact of LMs and data augmentation techniques on the recognition performance of the multilingual E2E ASR. In addition, we present several datasets for training and evaluation purposes. Experiment results show that the multilingual models achieve comparable performances to the monolingual baselines with a similar number of parameters. Our best monolingual and multilingual models achieved 20.9% and 20.5% average word error rates on the combined test set, respectively. To ensure the reproducibility of our experiments and results, we share our training recipes, datasets, and pre-trained models.
USC: An Open-Source Uzbek Speech Corpus and Initial Speech Recognition Experiments
Jul 30, 2021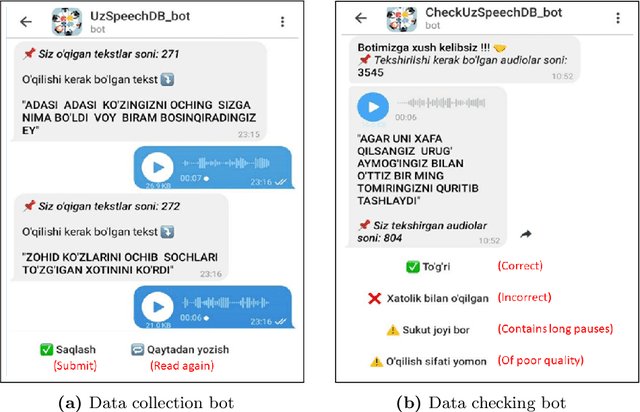
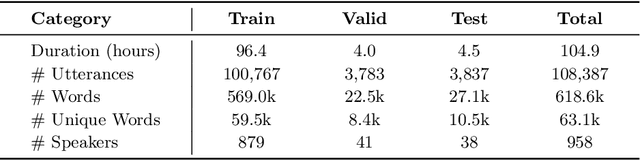
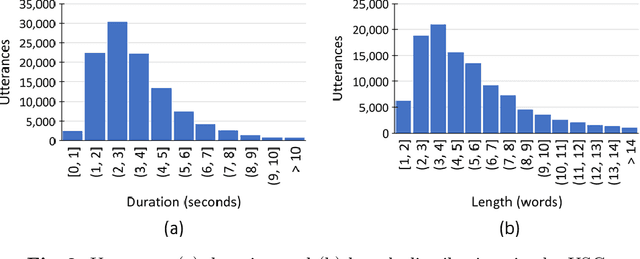
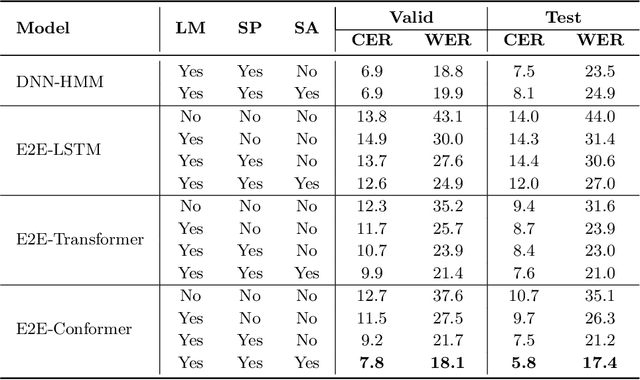
We present a freely available speech corpus for the Uzbek language and report preliminary automatic speech recognition (ASR) results using both the deep neural network hidden Markov model (DNN-HMM) and end-to-end (E2E) architectures. The Uzbek speech corpus (USC) comprises 958 different speakers with a total of 105 hours of transcribed audio recordings. To the best of our knowledge, this is the first open-source Uzbek speech corpus dedicated to the ASR task. To ensure high quality, the USC has been manually checked by native speakers. We first describe the design and development procedures of the USC, and then explain the conducted ASR experiments in detail. The experimental results demonstrate promising results for the applicability of the USC for ASR. Specifically, 18.1% and 17.4% word error rates were achieved on the validation and test sets, respectively. To enable experiment reproducibility, we share the USC dataset, pre-trained models, and training recipes in our GitHub repository.
Input Agnostic Deep Learning for Alzheimer's Disease Classification Using Multimodal MRI Images
Jul 19, 2021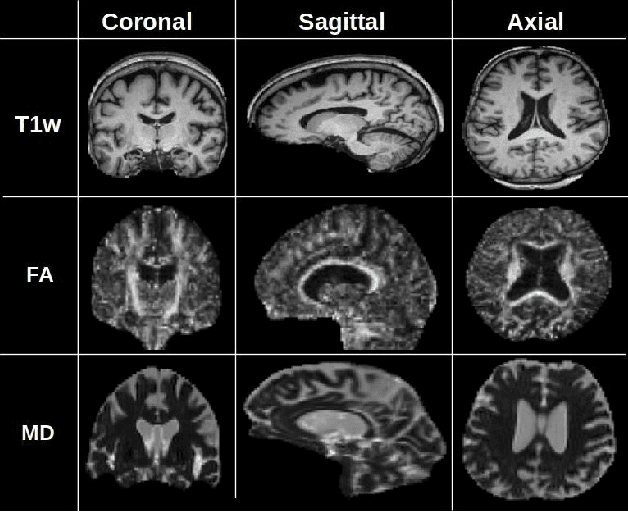
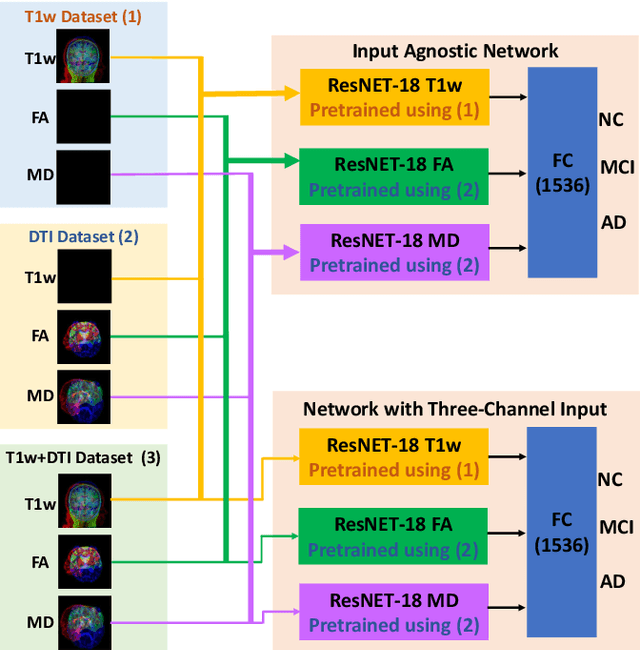


Alzheimer's disease (AD) is a progressive brain disorder that causes memory and functional impairments. The advances in machine learning and publicly available medical datasets initiated multiple studies in AD diagnosis. In this work, we utilize a multi-modal deep learning approach in classifying normal cognition, mild cognitive impairment and AD classes on the basis of structural MRI and diffusion tensor imaging (DTI) scans from the OASIS-3 dataset. In addition to a conventional multi-modal network, we also present an input agnostic architecture that allows diagnosis with either sMRI or DTI scan, which distinguishes our method from previous multi-modal machine learning-based methods. The results show that the input agnostic model achieves 0.96 accuracy when both structural MRI and DTI scans are provided as inputs.