 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Multilingual End-to-End Speech Recognition for Kazakh, Russian, and English
Paper and Code
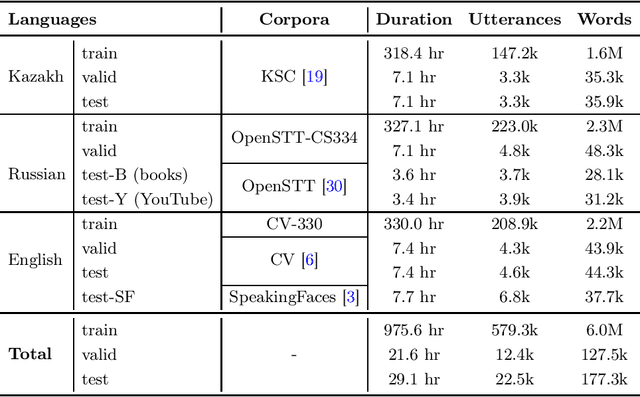
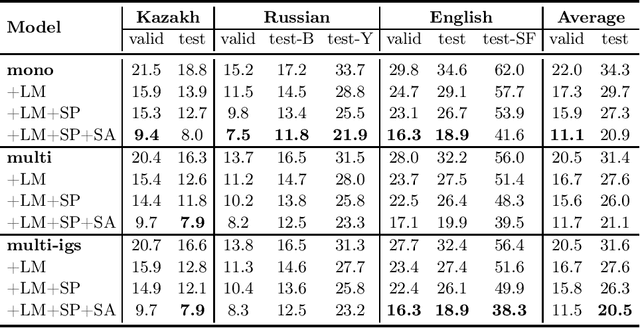

We study training a single end-to-end (E2E) automatic speech recognition (ASR) model for three languages used in Kazakhstan: Kazakh, Russian, and English. We first describe the development of multilingual E2E ASR based on Transformer networks and then perform an extensive assessment on the aforementioned languages. We also compare two variants of output grapheme set construction: combined and independent. Furthermore, we evaluate the impact of LMs and data augmentation techniques on the recognition performance of the multilingual E2E ASR. In addition, we present several datasets for training and evaluation purposes. Experiment results show that the multilingual models achieve comparable performances to the monolingual baselines with a similar number of parameters. Our best monolingual and multilingual models achieved 20.9% and 20.5% average word error rates on the combined test set, respectively. To ensure the reproducibility of our experiments and results, we share our training recipes, datasets, and pre-trained models.