 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKazEmoTTS: A Dataset for Kazakh Emotional Text-to-Speech Synthesis
Apr 09, 2024This study focuses on the creation of the KazEmoTTS dataset, designed for emotional Kazakh text-to-speech (TTS) applications. KazEmoTTS is a collection of 54,760 audio-text pairs, with a total duration of 74.85 hours, featuring 34.23 hours delivered by a female narrator and 40.62 hours by two male narrators. The list of the emotions considered include "neutral", "angry", "happy", "sad", "scared", and "surprised". We also developed a TTS model trained on the KazEmoTTS dataset. Objective and subjective evaluations were employed to assess the quality of synthesized speech, yielding an MCD score within the range of 6.02 to 7.67, alongside a MOS that spanned from 3.51 to 3.57. To facilitate reproducibility and inspire further research, we have made our code, pre-trained model, and dataset accessible in our GitHub repository.
Multilingual Text-to-Speech Synthesis for Turkic Languages Using Transliteration
May 25, 2023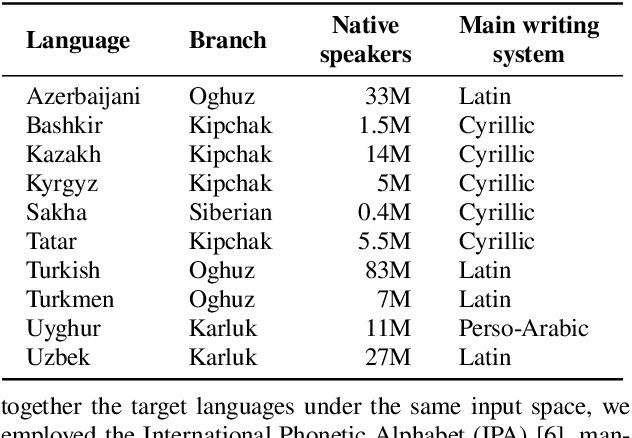
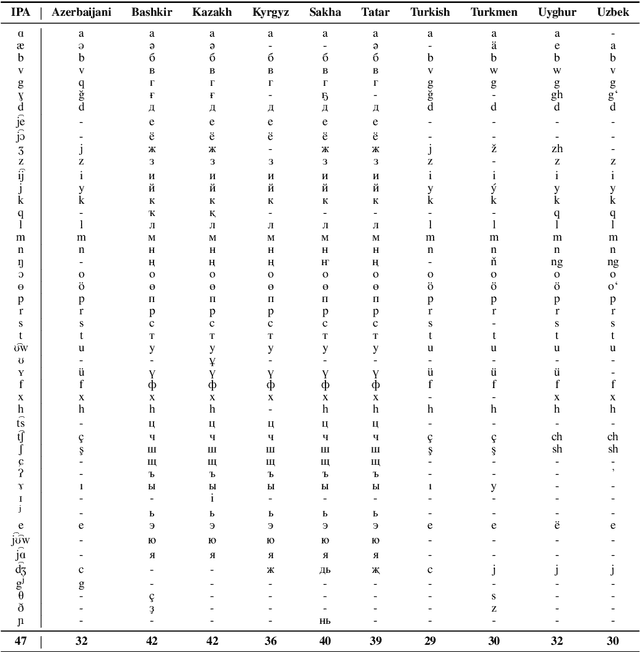
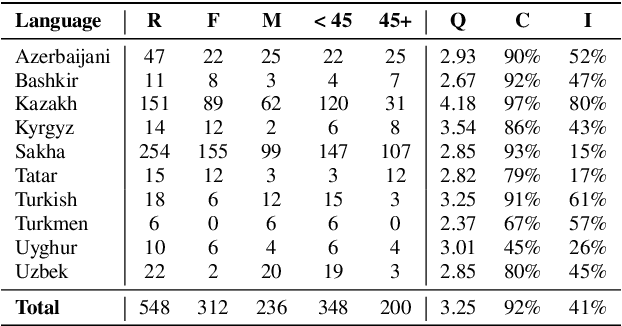
This work aims to build a multilingual text-to-speech (TTS) synthesis system for ten lower-resourced Turkic languages: Azerbaijani, Bashkir, Kazakh, Kyrgyz, Sakha, Tatar, Turkish, Turkmen, Uyghur, and Uzbek. We specifically target the zero-shot learning scenario, where a TTS model trained using the data of one language is applied to synthesise speech for other, unseen languages. An end-to-end TTS system based on the Tacotron 2 architecture was trained using only the available data of the Kazakh language. To generate speech for the other Turkic languages, we first mapped the letters of the Turkic alphabets onto the symbols of the International Phonetic Alphabet (IPA), which were then converted to the Kazakh alphabet letters. To demonstrate the feasibility of the proposed approach, we evaluated the multilingual Turkic TTS model subjectively and obtained promising results. To enable replication of the experiments, we make our code and dataset publicly available in our GitHub repository.
KazakhTTS2: Extending the Open-Source Kazakh TTS Corpus With More Data, Speakers, and Topics
Jan 15, 2022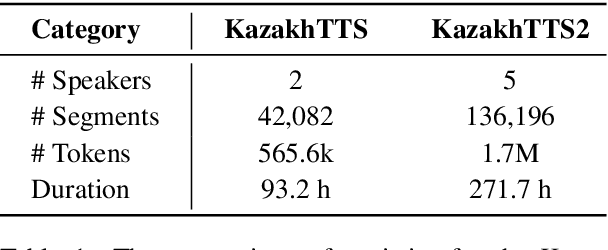
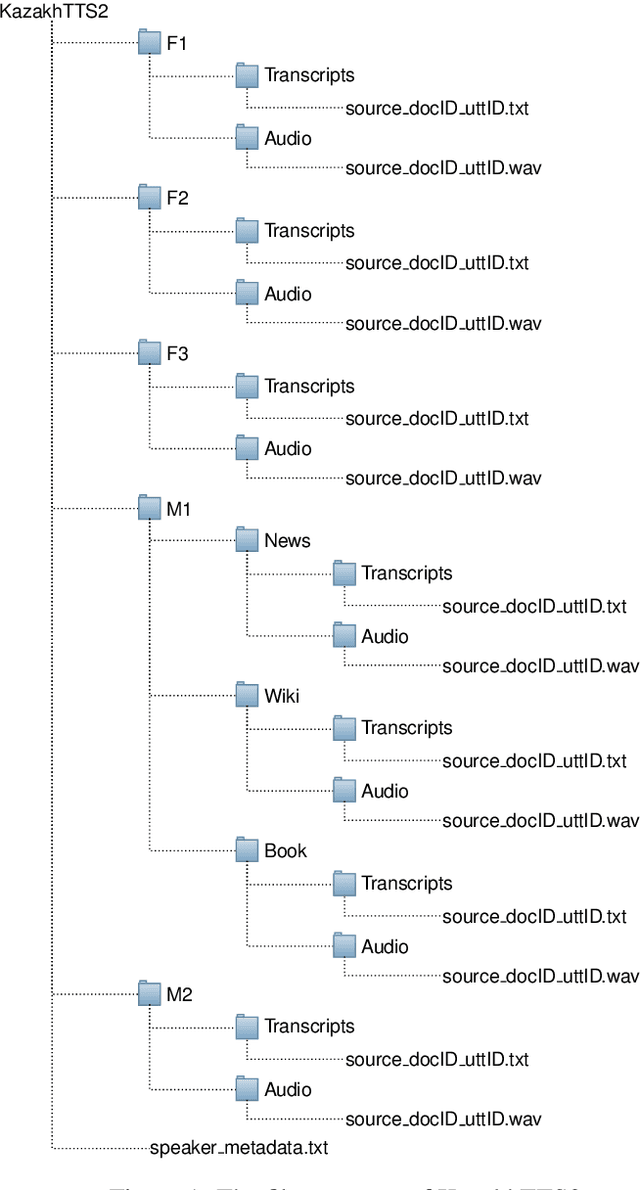
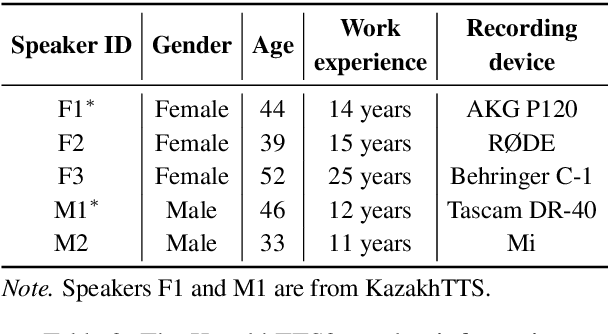
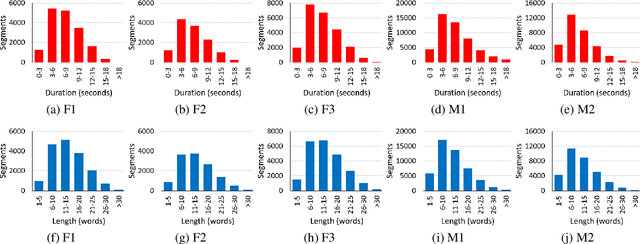
We present an expanded version of our previously released Kazakh text-to-speech (KazakhTTS) synthesis corpus. In the new KazakhTTS2 corpus, the overall size is increased from 93 hours to 271 hours, the number of speakers has risen from two to five (three females and two males), and the topic coverage is diversified with the help of new sources, including a book and Wikipedia articles. This corpus is necessary for building high-quality TTS systems for Kazakh, a Central Asian agglutinative language from the Turkic family, which presents several linguistic challenges. We describe the corpus construction process and provide the details of the training and evaluation procedures for the TTS system. Our experimental results indicate that the constructed corpus is sufficient to build robust TTS models for real-world applications, with a subjective mean opinion score of above 4.0 for all the five speakers. We believe that our corpus will facilitate speech and language research for Kazakh and other Turkic languages, which are widely considered to be low-resource due to the limited availability of free linguistic data. The constructed corpus, code, and pretrained models are publicly available in our GitHub repository.
A Study of Multilingual End-to-End Speech Recognition for Kazakh, Russian, and English
Aug 03, 2021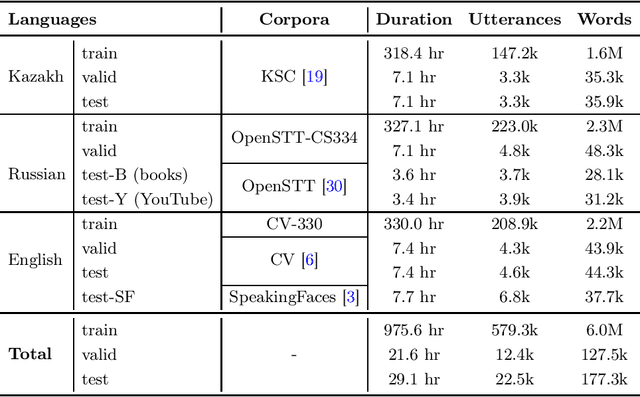
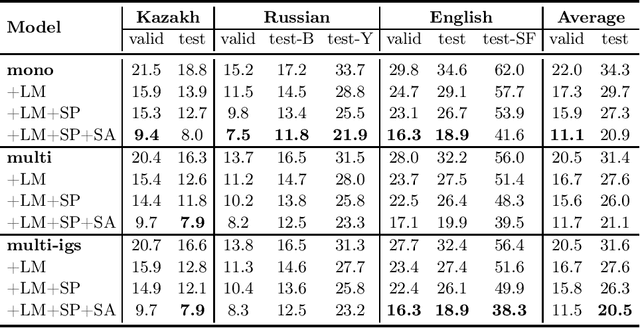

We study training a single end-to-end (E2E) automatic speech recognition (ASR) model for three languages used in Kazakhstan: Kazakh, Russian, and English. We first describe the development of multilingual E2E ASR based on Transformer networks and then perform an extensive assessment on the aforementioned languages. We also compare two variants of output grapheme set construction: combined and independent. Furthermore, we evaluate the impact of LMs and data augmentation techniques on the recognition performance of the multilingual E2E ASR. In addition, we present several datasets for training and evaluation purposes. Experiment results show that the multilingual models achieve comparable performances to the monolingual baselines with a similar number of parameters. Our best monolingual and multilingual models achieved 20.9% and 20.5% average word error rates on the combined test set, respectively. To ensure the reproducibility of our experiments and results, we share our training recipes, datasets, and pre-trained models.
USC: An Open-Source Uzbek Speech Corpus and Initial Speech Recognition Experiments
Jul 30, 2021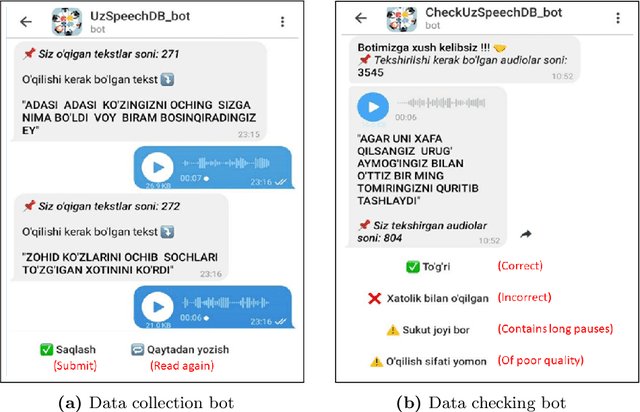
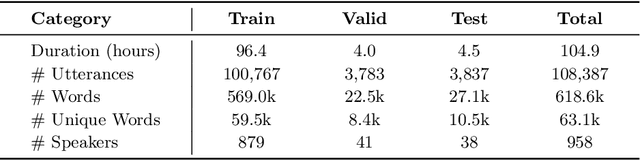
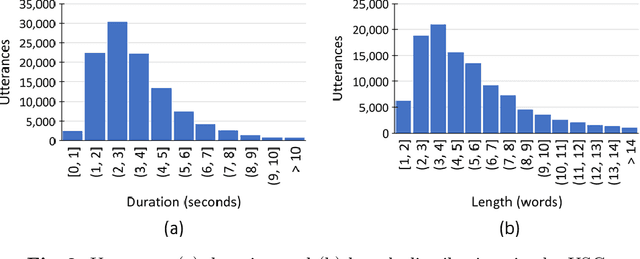
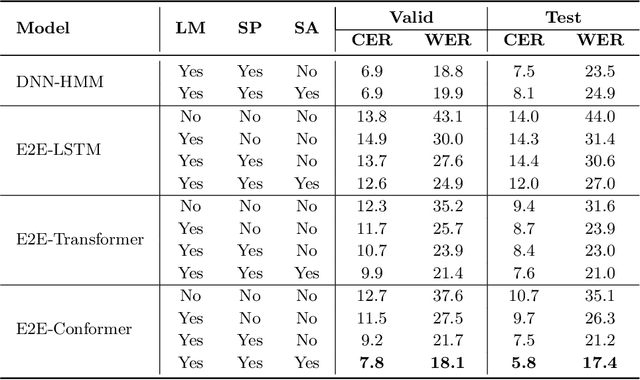
We present a freely available speech corpus for the Uzbek language and report preliminary automatic speech recognition (ASR) results using both the deep neural network hidden Markov model (DNN-HMM) and end-to-end (E2E) architectures. The Uzbek speech corpus (USC) comprises 958 different speakers with a total of 105 hours of transcribed audio recordings. To the best of our knowledge, this is the first open-source Uzbek speech corpus dedicated to the ASR task. To ensure high quality, the USC has been manually checked by native speakers. We first describe the design and development procedures of the USC, and then explain the conducted ASR experiments in detail. The experimental results demonstrate promising results for the applicability of the USC for ASR. Specifically, 18.1% and 17.4% word error rates were achieved on the validation and test sets, respectively. To enable experiment reproducibility, we share the USC dataset, pre-trained models, and training recipes in our GitHub repository.
KazakhTTS: An Open-Source Kazakh Text-to-Speech Synthesis Dataset
Apr 26, 2021
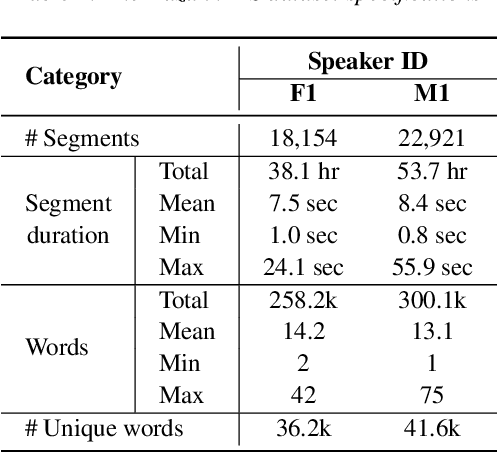
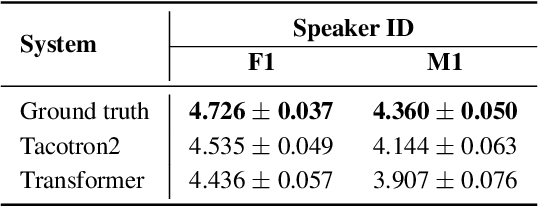
This paper introduces a high-quality open-source speech synthesis dataset for Kazakh, a low-resource language spoken by over 13 million people worldwide. The dataset consists of about 93 hours of transcribed audio recordings spoken by two professional speakers (female and male). It is the first publicly available large-scale dataset developed to promote Kazakh text-to-speech (TTS) applications in both academia and industry. In this paper, we share our experience by describing the dataset development procedures and faced challenges, and discuss important future directions. To demonstrate the reliability of our dataset, we built baseline end-to-end TTS models and evaluated them using the subjective mean opinion score (MOS) measure. Evaluation results show that the best TTS models trained on our dataset achieve MOS above 4 for both speakers, which makes them applicable for practical use. The dataset, training recipe, and pretrained TTS models are freely available.
A Crowdsourced Open-Source Kazakh Speech Corpus and Initial Speech Recognition Baseline
Sep 22, 2020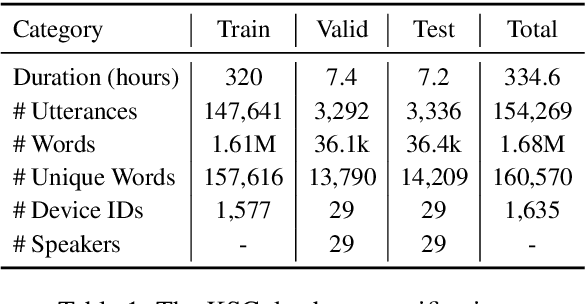
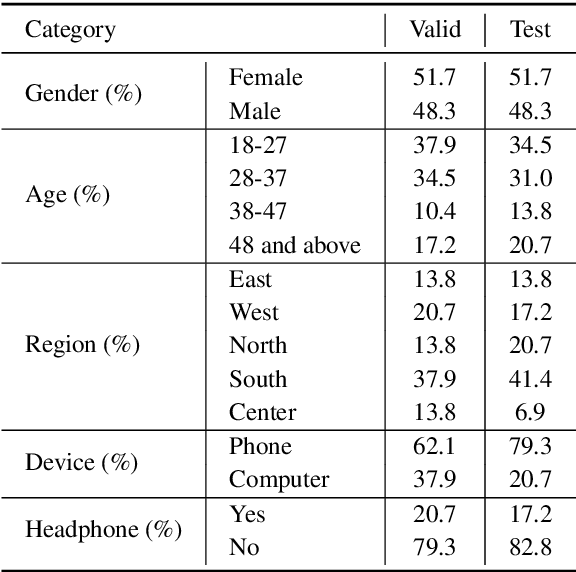
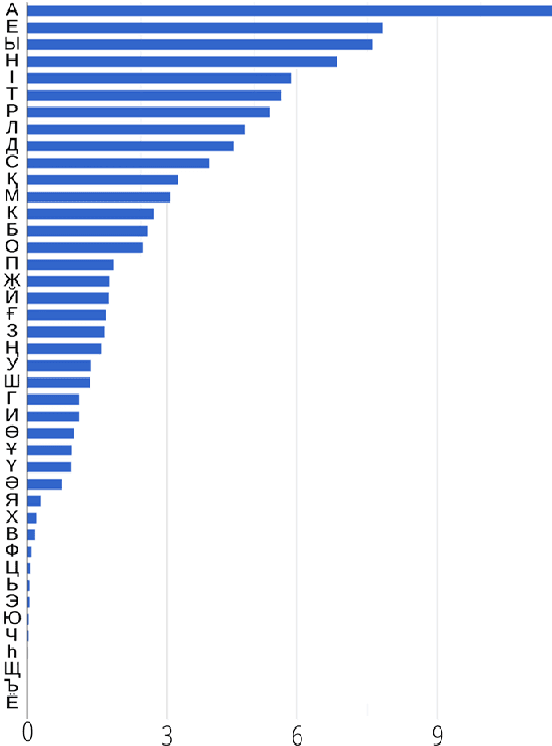
We present an open-source speech corpus for the Kazakh language. The Kazakh speech corpus (KSC) contains around 335 hours of transcribed audio comprising over 154,000 utterances spoken by participants from different regions, age groups, and gender. It was carefully inspected by native Kazakh speakers to ensure high quality. The KSC is the largest publicly available database developed to advance various Kazakh speech and language processing applications. In this paper, we first describe the data collection and prepossessing procedures followed by the description of the database specifications. We also share our experience and challenges faced during database construction. To demonstrate the reliability of the database, we performed the preliminary speech recognition experiments. The experimental results imply that the quality of audio and transcripts are promising. To enable experiment reproducibility and ease the corpus usage, we also released the ESPnet recipe.