 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Crowdsourced Open-Source Kazakh Speech Corpus and Initial Speech Recognition Baseline
Paper and Code
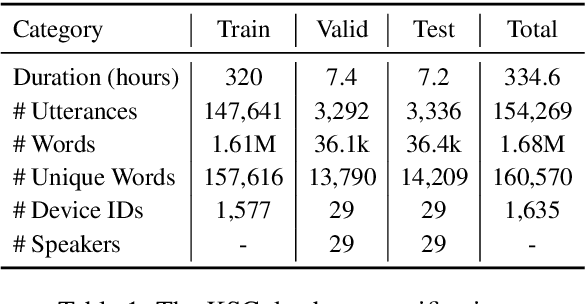
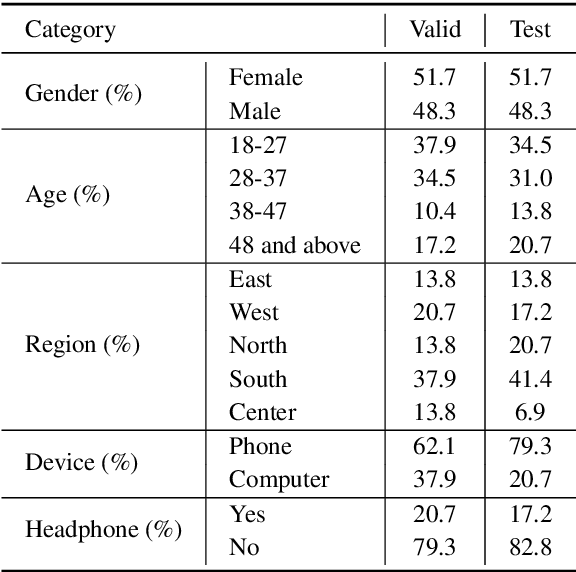
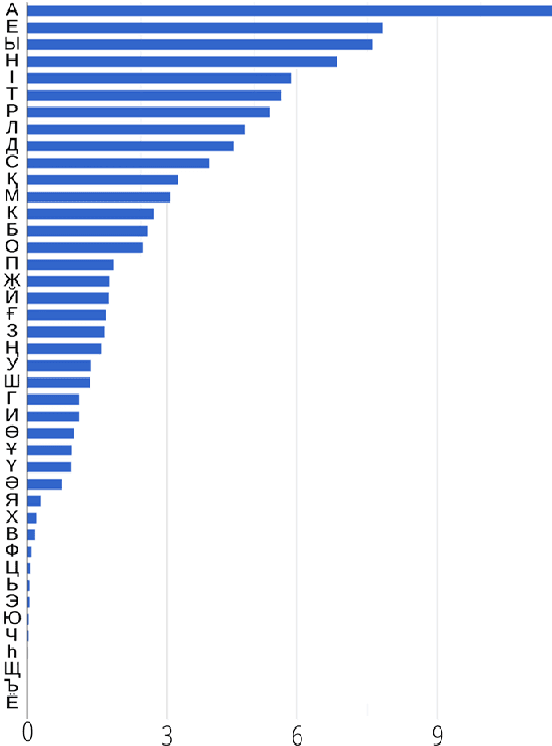
We present an open-source speech corpus for the Kazakh language. The Kazakh speech corpus (KSC) contains around 335 hours of transcribed audio comprising over 154,000 utterances spoken by participants from different regions, age groups, and gender. It was carefully inspected by native Kazakh speakers to ensure high quality. The KSC is the largest publicly available database developed to advance various Kazakh speech and language processing applications. In this paper, we first describe the data collection and prepossessing procedures followed by the description of the database specifications. We also share our experience and challenges faced during database construction. To demonstrate the reliability of the database, we performed the preliminary speech recognition experiments. The experimental results imply that the quality of audio and transcripts are promising. To enable experiment reproducibility and ease the corpus usage, we also released the ESPnet recipe.