 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Multimodal Person Verification Using Audio-Visual-Thermal Data
Oct 23, 2021
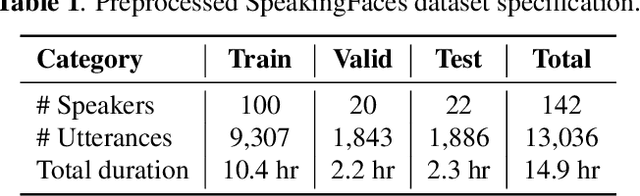
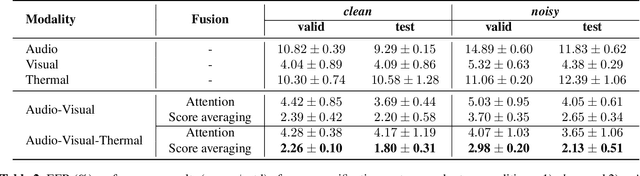
In this paper, we study an approach to multimodal person verification using audio, visual, and thermal modalities. The combination of audio and visual modalities has already been shown to be effective for robust person verification. From this perspective, we investigate the impact of further increasing the number of modalities by supplementing thermal images. In particular, we implemented unimodal, bimodal, and trimodal verification systems using the state-of-the-art deep learning architectures and compared their performance under clean and noisy conditions. We also compared two popular fusion approaches based on simple score averaging and soft attention mechanism. The experiment conducted on the SpeakingFaces dataset demonstrates the superiority of the trimodal verification system over both unimodal and bimodal systems. To enable the reproducibility of the experiment and facilitate research into multimodal person verification, we make our code, pretrained models and preprocessed dataset freely available in our GitHub repository.