 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Multimodal Person Verification Using Audio-Visual-Thermal Data
Oct 23, 2021
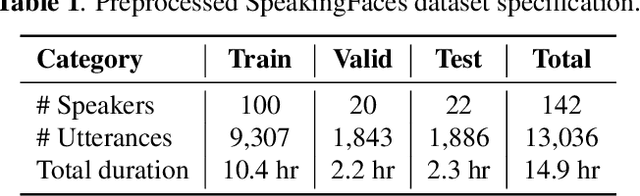
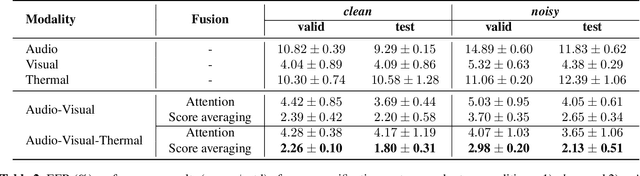
In this paper, we study an approach to multimodal person verification using audio, visual, and thermal modalities. The combination of audio and visual modalities has already been shown to be effective for robust person verification. From this perspective, we investigate the impact of further increasing the number of modalities by supplementing thermal images. In particular, we implemented unimodal, bimodal, and trimodal verification systems using the state-of-the-art deep learning architectures and compared their performance under clean and noisy conditions. We also compared two popular fusion approaches based on simple score averaging and soft attention mechanism. The experiment conducted on the SpeakingFaces dataset demonstrates the superiority of the trimodal verification system over both unimodal and bimodal systems. To enable the reproducibility of the experiment and facilitate research into multimodal person verification, we make our code, pretrained models and preprocessed dataset freely available in our GitHub repository.
SpeakingFaces: A Large-Scale Multimodal Dataset of Voice Commands with Visual and Thermal Video Streams
Dec 18, 2020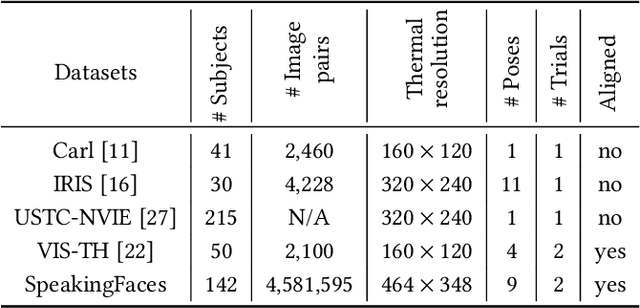


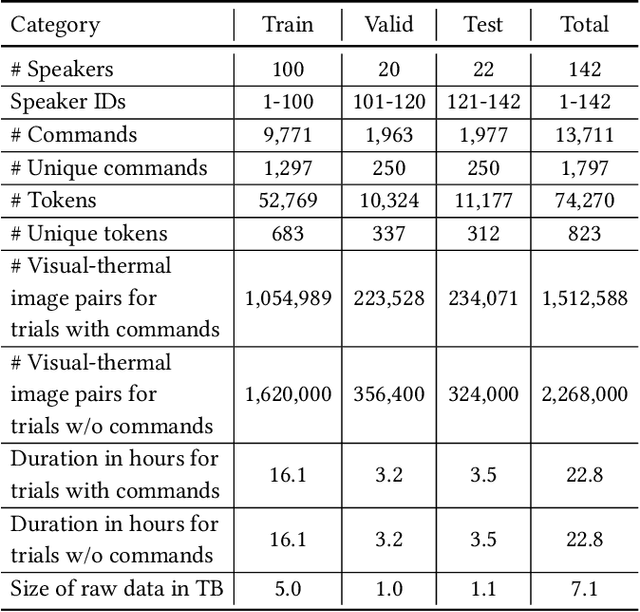
We present SpeakingFaces as a publicly-available large-scale dataset developed to support multimodal machine learning research in contexts that utilize a combination of thermal, visual, and audio data streams; examples include human-computer interaction (HCI), biometric authentication, recognition systems, domain transfer, and speech recognition. SpeakingFaces is comprised of well-aligned high-resolution thermal and visual spectra image streams of fully-framed faces synchronized with audio recordings of each subject speaking approximately 100 imperative phrases. Data were collected from 142 subjects, yielding over 13,000 instances of synchronized data (~3.8 TB). For technical validation, we demonstrate two baseline examples. The first baseline shows classification by gender, utilizing different combinations of the three data streams in both clean and noisy environments. The second example consists of thermal-to-visual facial image translation, as an instance of domain transfer.
Learning Consistent Deep Generative Models from Sparse Data via Prediction Constraints
Dec 12, 2020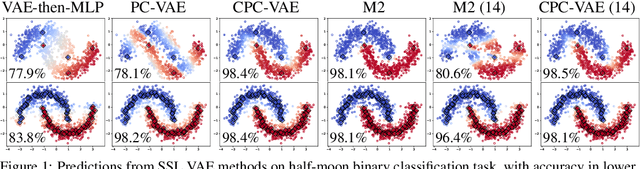
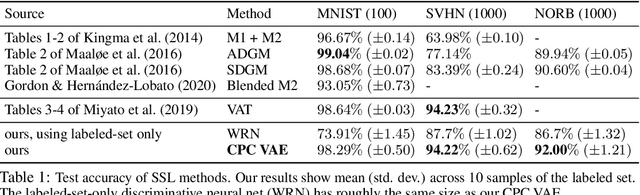


We develop a new framework for learning variational autoencoders and other deep generative models that balances generative and discriminative goals. Our framework optimizes model parameters to maximize a variational lower bound on the likelihood of observed data, subject to a task-specific prediction constraint that prevents model misspecification from leading to inaccurate predictions. We further enforce a consistency constraint, derived naturally from the generative model, that requires predictions on reconstructed data to match those on the original data. We show that these two contributions -- prediction constraints and consistency constraints -- lead to promising image classification performance, especially in the semi-supervised scenario where category labels are sparse but unlabeled data is plentiful. Our approach enables advances in generative modeling to directly boost semi-supervised classification performance, an ability we demonstrate by augmenting deep generative models with latent variables capturing spatial transformations.