 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLaID++: A Preference Aligned Language Model for Targeted Inorganic Materials Design
Sep 08, 2025Discovering novel materials is critical for technological advancements such as solar cells, batteries, and carbon capture. However, the development of new materials is constrained by a slow and expensive trial-and-error process. To accelerate this pipeline, we introduce PLaID++, a Large Language Model (LLM) fine-tuned for stable and property-guided crystal generation. We fine-tune Qwen-2.5 7B to generate crystal structures using a novel Wyckoff-based text representation. We show that generation can be effectively guided with a reinforcement learning technique based on Direct Preference Optimization (DPO), with sampled structures categorized by their stability, novelty, and space group. By encoding symmetry constraints directly into text and guiding model outputs towards desirable chemical space, PLaID++ generates structures that are thermodynamically stable, unique, and novel at a $\sim$50\% greater rate than prior methods and conditionally generates structures with desired space group properties. Our experiments highlight the effectiveness of iterative DPO, achieving $\sim$115\% and $\sim$50\% improvements in unconditional and space group conditioned generation, respectively, compared to fine-tuning alone. Our work demonstrates the potential of adapting post-training techniques from natural language processing to materials design, paving the way for targeted and efficient discovery of novel materials.
Unbiased Learning of Deep Generative Models with Structured Discrete Representations
Jun 14, 2023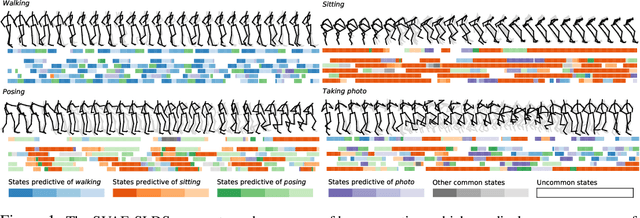
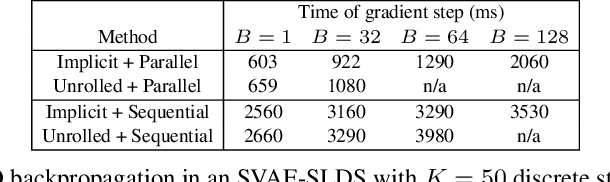
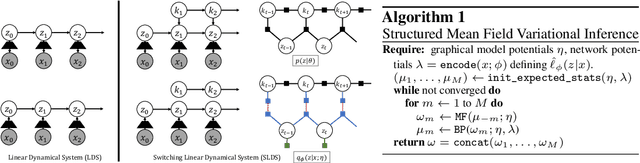
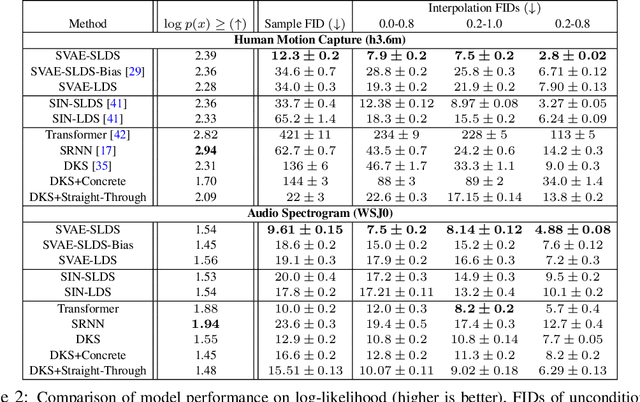
By composing graphical models with deep learning architectures, we learn generative models with the strengths of both frameworks. The structured variational autoencoder (SVAE) inherits structure and interpretability from graphical models, and flexible likelihoods for high-dimensional data from deep learning, but poses substantial optimization challenges. We propose novel algorithms for learning SVAEs, and are the first to demonstrate the SVAE's ability to handle multimodal uncertainty when data is missing by incorporating discrete latent variables. Our memory-efficient implicit differentiation scheme makes the SVAE tractable to learn via gradient descent, while demonstrating robustness to incomplete optimization. To more rapidly learn accurate graphical model parameters, we derive a method for computing natural gradients without manual derivations, which avoids biases found in prior work. These optimization innovations enable the first comparisons of the SVAE to state-of-the-art time series models, where the SVAE performs competitively while learning interpretable and structured discrete data representations.
Learning Consistent Deep Generative Models from Sparse Data via Prediction Constraints
Dec 12, 2020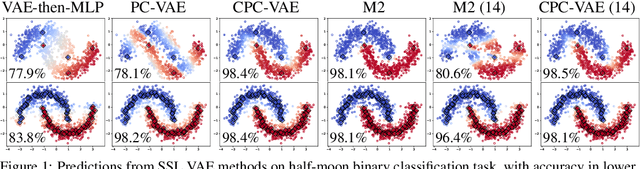
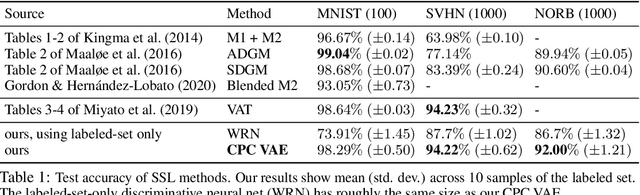


We develop a new framework for learning variational autoencoders and other deep generative models that balances generative and discriminative goals. Our framework optimizes model parameters to maximize a variational lower bound on the likelihood of observed data, subject to a task-specific prediction constraint that prevents model misspecification from leading to inaccurate predictions. We further enforce a consistency constraint, derived naturally from the generative model, that requires predictions on reconstructed data to match those on the original data. We show that these two contributions -- prediction constraints and consistency constraints -- lead to promising image classification performance, especially in the semi-supervised scenario where category labels are sparse but unlabeled data is plentiful. Our approach enables advances in generative modeling to directly boost semi-supervised classification performance, an ability we demonstrate by augmenting deep generative models with latent variables capturing spatial transformations.
Prediction-Constrained Topic Models for Antidepressant Recommendation
Dec 01, 2017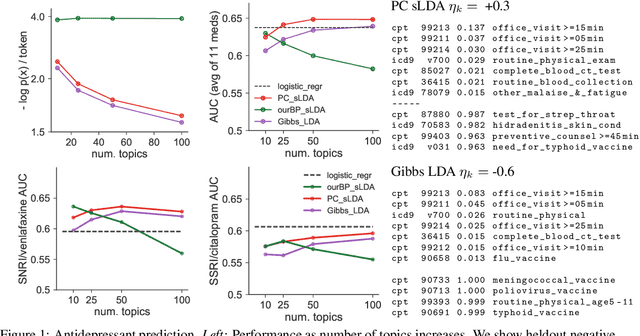
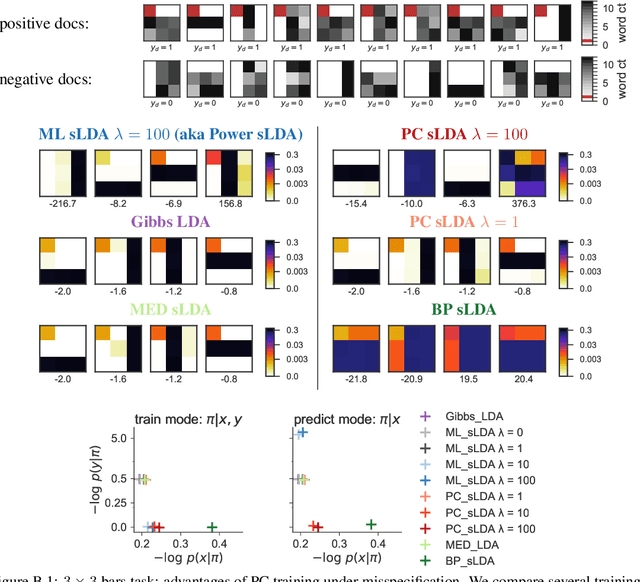
Supervisory signals can help topic models discover low-dimensional data representations that are more interpretable for clinical tasks. We propose a framework for training supervised latent Dirichlet allocation that balances two goals: faithful generative explanations of high-dimensional data and accurate prediction of associated class labels. Existing approaches fail to balance these goals by not properly handling a fundamental asymmetry: the intended task is always predicting labels from data, not data from labels. Our new prediction-constrained objective trains models that predict labels from heldout data well while also producing good generative likelihoods and interpretable topic-word parameters. In a case study on predicting depression medications from electronic health records, we demonstrate improved recommendations compared to previous supervised topic models and high- dimensional logistic regression from words alone.
Prediction-Constrained Training for Semi-Supervised Mixture and Topic Models
Jul 23, 2017
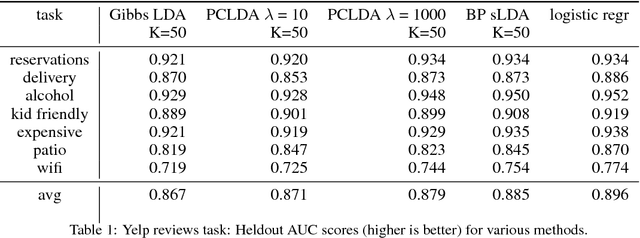
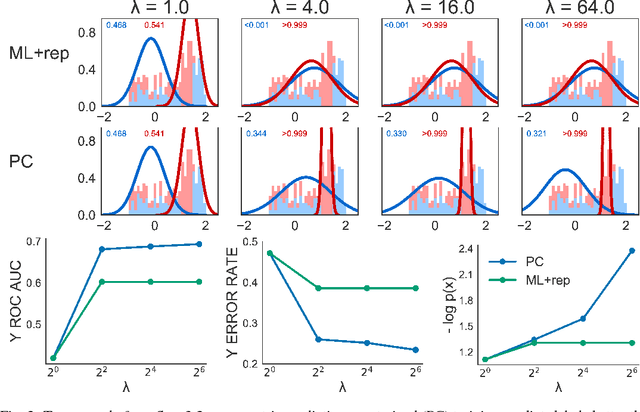
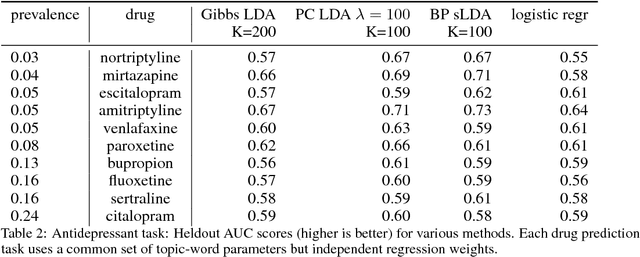
Supervisory signals have the potential to make low-dimensional data representations, like those learned by mixture and topic models, more interpretable and useful. We propose a framework for training latent variable models that explicitly balances two goals: recovery of faithful generative explanations of high-dimensional data, and accurate prediction of associated semantic labels. Existing approaches fail to achieve these goals due to an incomplete treatment of a fundamental asymmetry: the intended application is always predicting labels from data, not data from labels. Our prediction-constrained objective for training generative models coherently integrates loss-based supervisory signals while enabling effective semi-supervised learning from partially labeled data. We derive learning algorithms for semi-supervised mixture and topic models using stochastic gradient descent with automatic differentiation. We demonstrate improved prediction quality compared to several previous supervised topic models, achieving predictions competitive with high-dimensional logistic regression on text sentiment analysis and electronic health records tasks while simultaneously learning interpretable topics.