 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreferential Mixture-of-Experts: Interpretable Models that Rely on Human Expertise as much as Possible
Jan 13, 2021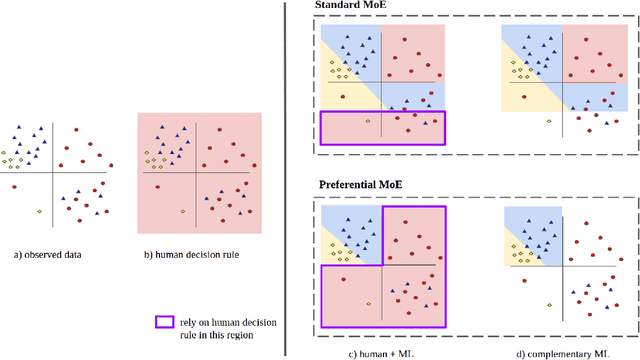
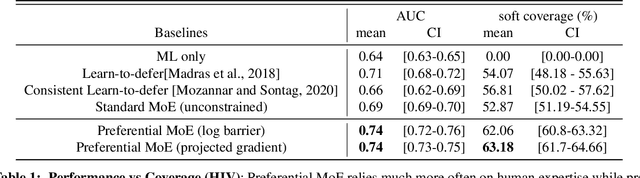
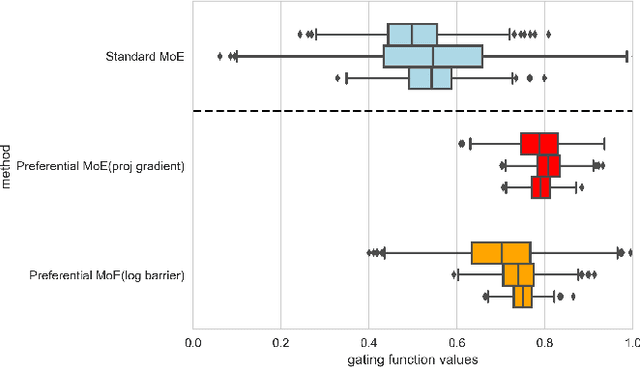
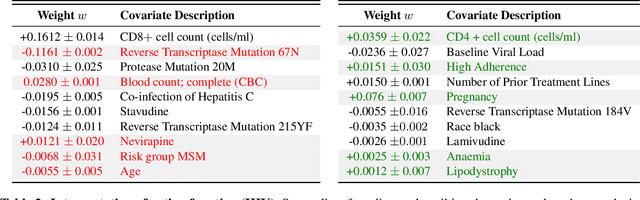
We propose Preferential MoE, a novel human-ML mixture-of-experts model that augments human expertise in decision making with a data-based classifier only when necessary for predictive performance. Our model exhibits an interpretable gating function that provides information on when human rules should be followed or avoided. The gating function is maximized for using human-based rules, and classification errors are minimized. We propose solving a coupled multi-objective problem with convex subproblems. We develop approximate algorithms and study their performance and convergence. Finally, we demonstrate the utility of Preferential MoE on two clinical applications for the treatment of Human Immunodeficiency Virus (HIV) and management of Major Depressive Disorder (MDD).
Prediction-Constrained Topic Models for Antidepressant Recommendation
Dec 01, 2017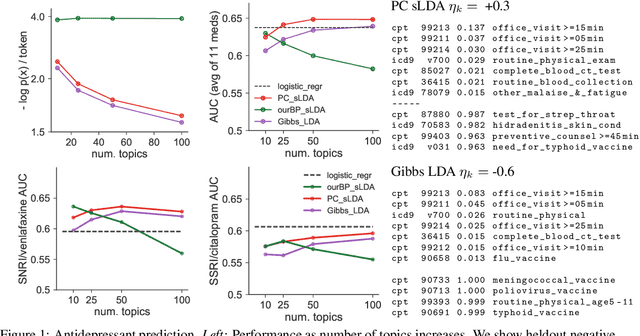
Supervisory signals can help topic models discover low-dimensional data representations that are more interpretable for clinical tasks. We propose a framework for training supervised latent Dirichlet allocation that balances two goals: faithful generative explanations of high-dimensional data and accurate prediction of associated class labels. Existing approaches fail to balance these goals by not properly handling a fundamental asymmetry: the intended task is always predicting labels from data, not data from labels. Our new prediction-constrained objective trains models that predict labels from heldout data well while also producing good generative likelihoods and interpretable topic-word parameters. In a case study on predicting depression medications from electronic health records, we demonstrate improved recommendations compared to previous supervised topic models and high- dimensional logistic regression from words alone.
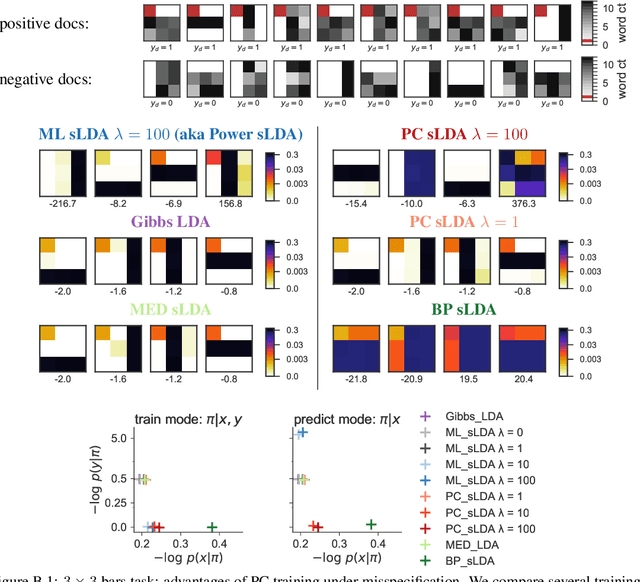
Prediction-Constrained Training for Semi-Supervised Mixture and Topic Models
Jul 23, 2017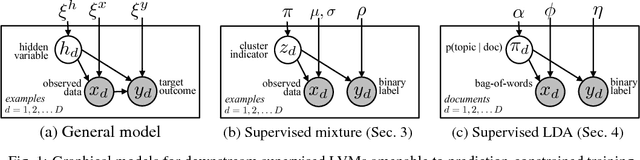
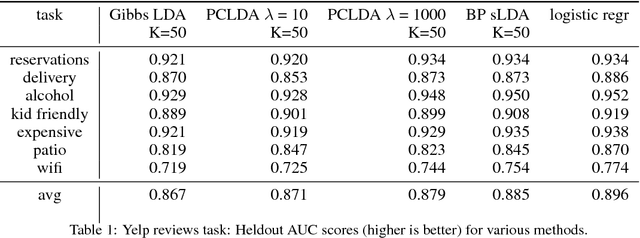
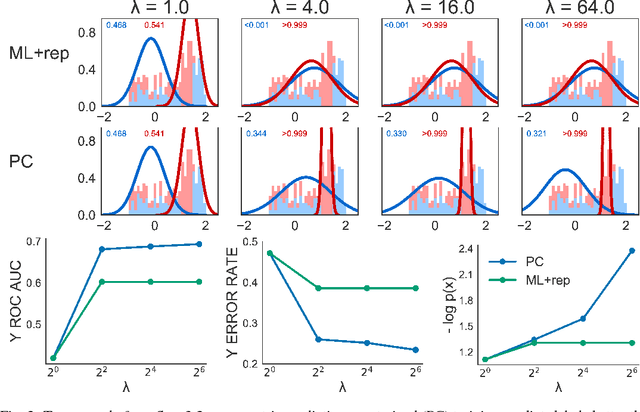
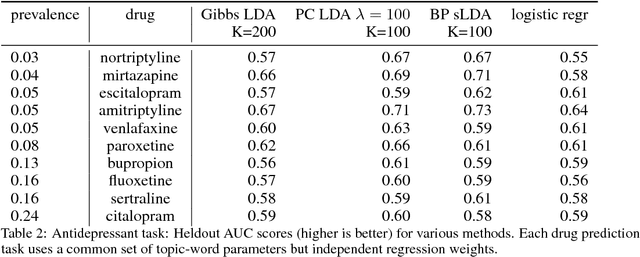
Supervisory signals have the potential to make low-dimensional data representations, like those learned by mixture and topic models, more interpretable and useful. We propose a framework for training latent variable models that explicitly balances two goals: recovery of faithful generative explanations of high-dimensional data, and accurate prediction of associated semantic labels. Existing approaches fail to achieve these goals due to an incomplete treatment of a fundamental asymmetry: the intended application is always predicting labels from data, not data from labels. Our prediction-constrained objective for training generative models coherently integrates loss-based supervisory signals while enabling effective semi-supervised learning from partially labeled data. We derive learning algorithms for semi-supervised mixture and topic models using stochastic gradient descent with automatic differentiation. We demonstrate improved prediction quality compared to several previous supervised topic models, achieving predictions competitive with high-dimensional logistic regression on text sentiment analysis and electronic health records tasks while simultaneously learning interpretable topics.