 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"It's trained by non-disabled people": Evaluating How Image Quality Affects Product Captioning with VLMs
Nov 12, 2025Vision-Language Models (VLMs) are increasingly used by blind and low-vision (BLV) people to identify and understand products in their everyday lives, such as food, personal products, and household goods. Despite their prevalence, we lack an empirical understanding of how common image quality issues, like blur and misframing of items, affect the accuracy of VLM-generated captions and whether resulting captions meet BLV people's information needs. Grounded in a survey with 86 BLV people, we systematically evaluate how image quality issues affect captions generated by VLMs. We show that the best model recognizes products in images with no quality issues with 98% accuracy, but drops to 75% accuracy overall when quality issues are present, worsening considerably as issues compound. We discuss the need for model evaluations that center on disabled people's experiences throughout the process and offer concrete recommendations for HCI and ML researchers to make VLMs more reliable for BLV people.
VIPaint: Image Inpainting with Pre-Trained Diffusion Models via Variational Inference
Nov 28, 2024



Diffusion probabilistic models learn to remove noise that is artificially added to the data during training. Novel data, like images, may then be generated from Gaussian noise through a sequence of denoising operations. While this Markov process implicitly defines a joint distribution over noise-free data, it is not simple to condition the generative process on masked or partial images. A number of heuristic sampling procedures have been proposed for solving inverse problems with diffusion priors, but these approaches do not directly approximate the true conditional distribution imposed by inference queries, and are often ineffective for large masked regions. Moreover, many of these baselines cannot be applied to latent diffusion models which use image encodings for efficiency. We instead develop a hierarchical variational inference algorithm that analytically marginalizes missing features, and uses a rigorous variational bound to optimize a non-Gaussian Markov approximation of the true diffusion posterior. Through extensive experiments with both pixel-based and latent diffusion models of images, we show that our VIPaint method significantly outperforms previous approaches in both the plausibility and diversity of imputations, and is easily generalized to other inverse problems like deblurring and superresolution.
Bayesian temporal biclustering with applications to multi-subject neuroscience studies
Jun 24, 2024



We consider the problem of analyzing multivariate time series collected on multiple subjects, with the goal of identifying groups of subjects exhibiting similar trends in their recorded measurements over time as well as time-varying groups of associated measurements. To this end, we propose a Bayesian model for temporal biclustering featuring nested partitions, where a time-invariant partition of subjects induces a time-varying partition of measurements. Our approach allows for data-driven determination of the number of subject and measurement clusters as well as estimation of the number and location of changepoints in measurement partitions. To efficiently perform model fitting and posterior estimation with Markov Chain Monte Carlo, we derive a blocked update of measurements' cluster-assignment sequences. We illustrate the performance of our model in two applications to functional magnetic resonance imaging data and to an electroencephalogram dataset. The results indicate that the proposed model can combine information from potentially many subjects to discover a set of interpretable, dynamic patterns. Experiments on simulated data compare the estimation performance of the proposed model against ground-truth values and other statistical methods, showing that it performs well at identifying ground-truth subject and measurement clusters even when no subject or time dependence is present.
Unbiased Learning of Deep Generative Models with Structured Discrete Representations
Jun 14, 2023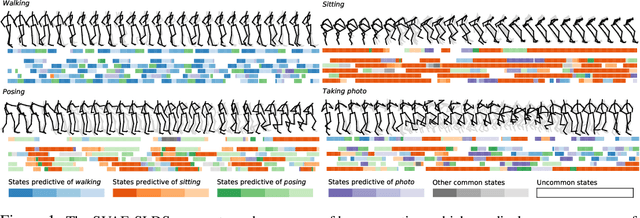
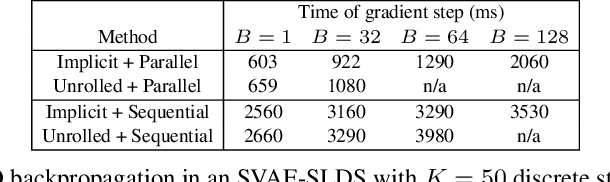
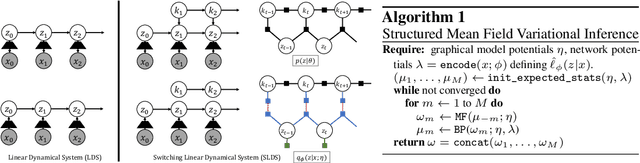
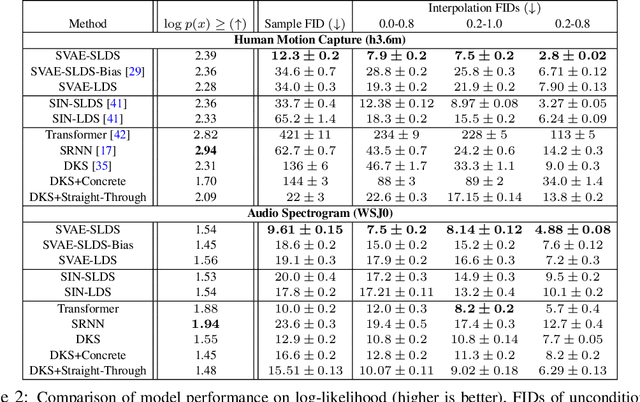
By composing graphical models with deep learning architectures, we learn generative models with the strengths of both frameworks. The structured variational autoencoder (SVAE) inherits structure and interpretability from graphical models, and flexible likelihoods for high-dimensional data from deep learning, but poses substantial optimization challenges. We propose novel algorithms for learning SVAEs, and are the first to demonstrate the SVAE's ability to handle multimodal uncertainty when data is missing by incorporating discrete latent variables. Our memory-efficient implicit differentiation scheme makes the SVAE tractable to learn via gradient descent, while demonstrating robustness to incomplete optimization. To more rapidly learn accurate graphical model parameters, we derive a method for computing natural gradients without manual derivations, which avoids biases found in prior work. These optimization innovations enable the first comparisons of the SVAE to state-of-the-art time series models, where the SVAE performs competitively while learning interpretable and structured discrete data representations.
Learning Consistent Deep Generative Models from Sparse Data via Prediction Constraints
Dec 12, 2020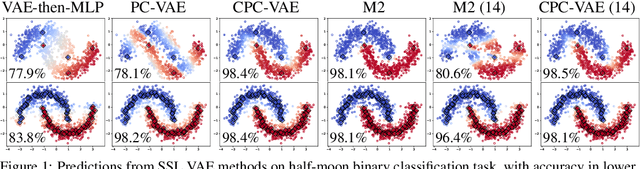
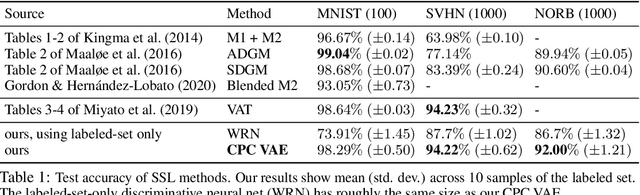


We develop a new framework for learning variational autoencoders and other deep generative models that balances generative and discriminative goals. Our framework optimizes model parameters to maximize a variational lower bound on the likelihood of observed data, subject to a task-specific prediction constraint that prevents model misspecification from leading to inaccurate predictions. We further enforce a consistency constraint, derived naturally from the generative model, that requires predictions on reconstructed data to match those on the original data. We show that these two contributions -- prediction constraints and consistency constraints -- lead to promising image classification performance, especially in the semi-supervised scenario where category labels are sparse but unlabeled data is plentiful. Our approach enables advances in generative modeling to directly boost semi-supervised classification performance, an ability we demonstrate by augmenting deep generative models with latent variables capturing spatial transformations.
Clouds of Oriented Gradients for 3D Detection of Objects, Surfaces, and Indoor Scene Layouts
Jun 11, 2019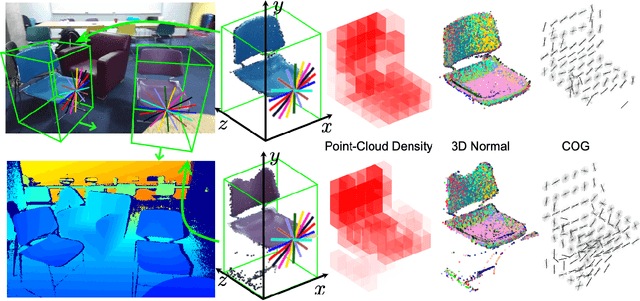
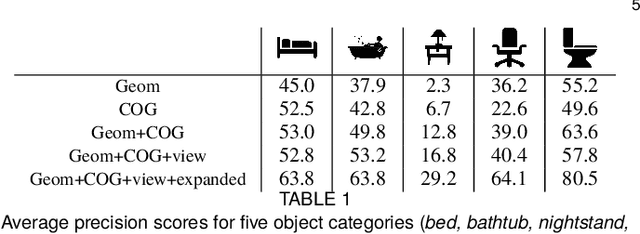


We develop new representations and algorithms for three-dimensional (3D) object detection and spatial layout prediction in cluttered indoor scenes. We first propose a clouds of oriented gradient (COG) descriptor that links the 2D appearance and 3D pose of object categories, and thus accurately models how perspective projection affects perceived image gradients. To better represent the 3D visual styles of large objects and provide contextual cues to improve the detection of small objects, we introduce latent support surfaces. We then propose a "Manhattan voxel" representation which better captures the 3D room layout geometry of common indoor environments. Effective classification rules are learned via a latent structured prediction framework. Contextual relationships among categories and layout are captured via a cascade of classifiers, leading to holistic scene hypotheses that exceed the state-of-the-art on the SUN RGB-D database.
Multi-layer Depth and Epipolar Feature Transformers for 3D Scene Reconstruction
Feb 18, 2019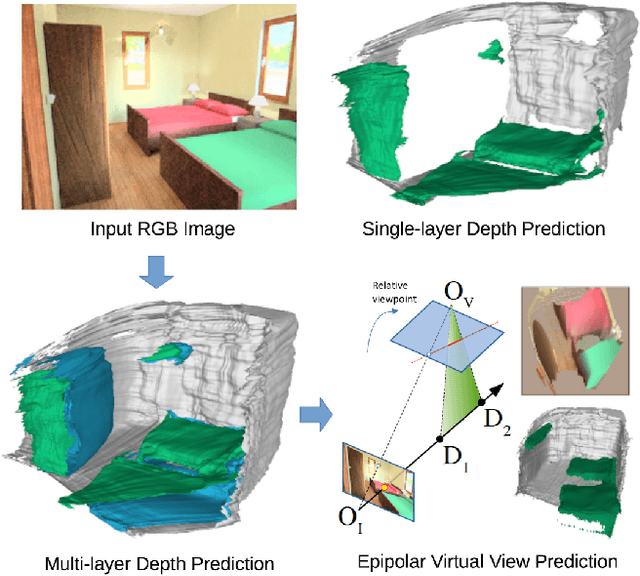
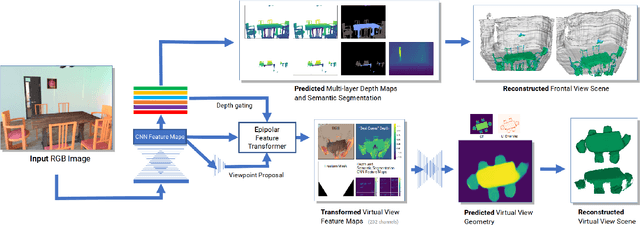

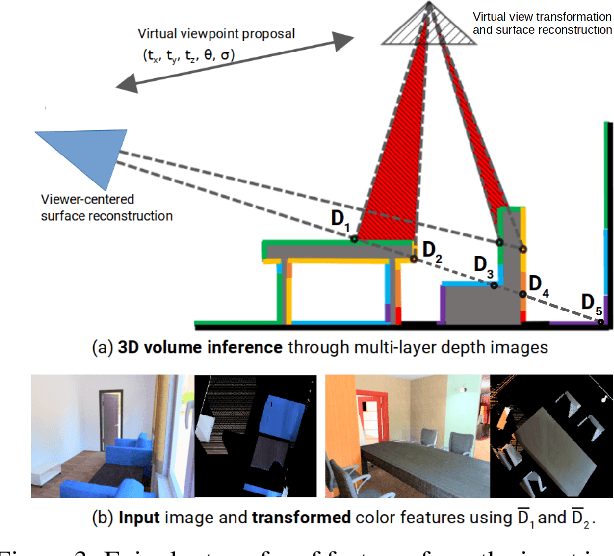
We tackle the problem of automatically reconstructing a complete 3D model of a scene from a single RGB image. This challenging task requires inferring the shape of both visible and occluded surfaces. Our approach utilizes viewer-centered, multi-layer representation of scene geometry adapted from recent methods for single object shape completion. To improve the accuracy of view-centered representations for complex scenes, we introduce a novel "Epipolar Feature Transformer" that transfers convolutional network features from an input view to other virtual camera viewpoints, and thus better covers the 3D scene geometry. Unlike existing approaches that first detect and localize objects in 3D, and then infer object shape using category-specific models, our approach is fully convolutional, end-to-end differentiable, and avoids the resolution and memory limitations of voxel representations. We demonstrate the advantages of multi-layer depth representations and epipolar feature transformers on the reconstruction of a large database of indoor scenes.
A Fusion Approach for Multi-Frame Optical Flow Estimation
Oct 23, 2018



To date, top-performing optical flow estimation methods only take pairs of consecutive frames into account. While elegant and appealing, the idea of using more than two frames has not yet produced state-of-the-art results. We present a simple, yet effective fusion approach for multi-frame optical flow that benefits from longer-term temporal cues. Our method first warps the optical flow from previous frames to the current, thereby yielding multiple plausible estimates. It then fuses the complementary information carried by these estimates into a new optical flow field. At the time of submission, our method ranks first among published flow methods in the MPI Sintel and KITTI 2015 benchmarks.
Bayesian Paragraph Vectors
Dec 07, 2017

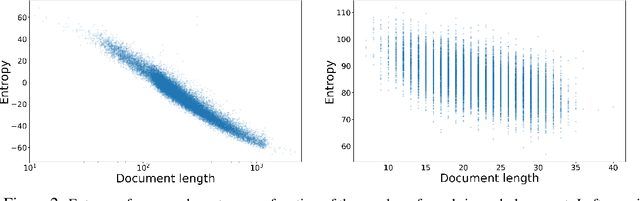
Word2vec (Mikolov et al., 2013) has proven to be successful in natural language processing by capturing the semantic relationships between different words. Built on top of single-word embeddings, paragraph vectors (Le and Mikolov, 2014) find fixed-length representations for pieces of text with arbitrary lengths, such as documents, paragraphs, and sentences. In this work, we propose a novel interpretation for neural-network-based paragraph vectors by developing an unsupervised generative model whose maximum likelihood solution corresponds to traditional paragraph vectors. This probabilistic formulation allows us to go beyond point estimates of parameters and to perform Bayesian posterior inference. We find that the entropy of paragraph vectors decreases with the length of documents, and that information about posterior uncertainty improves performance in supervised learning tasks such as sentiment analysis and paraphrase detection.
Prediction-Constrained Topic Models for Antidepressant Recommendation
Dec 01, 2017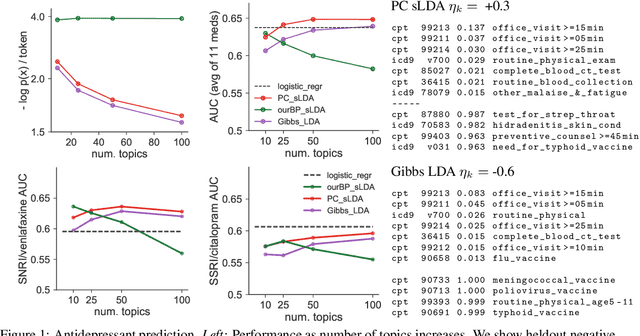
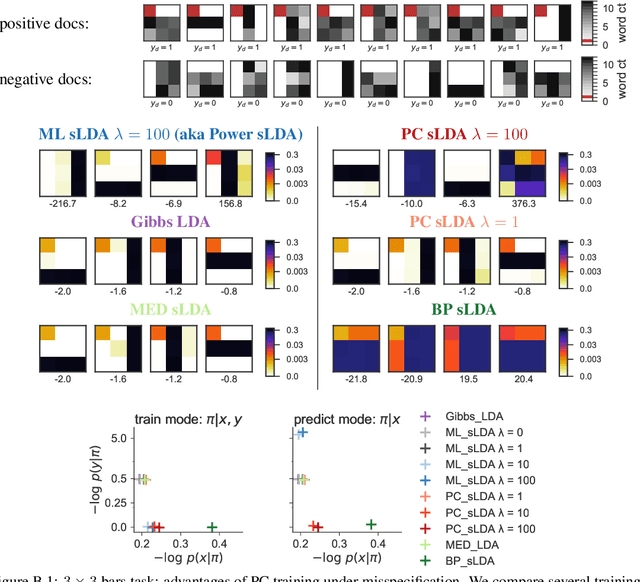
Supervisory signals can help topic models discover low-dimensional data representations that are more interpretable for clinical tasks. We propose a framework for training supervised latent Dirichlet allocation that balances two goals: faithful generative explanations of high-dimensional data and accurate prediction of associated class labels. Existing approaches fail to balance these goals by not properly handling a fundamental asymmetry: the intended task is always predicting labels from data, not data from labels. Our new prediction-constrained objective trains models that predict labels from heldout data well while also producing good generative likelihoods and interpretable topic-word parameters. In a case study on predicting depression medications from electronic health records, we demonstrate improved recommendations compared to previous supervised topic models and high- dimensional logistic regression from words alone.