 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShoeRinsics: Shoeprint Prediction for Forensics with Intrinsic Decomposition
May 04, 2022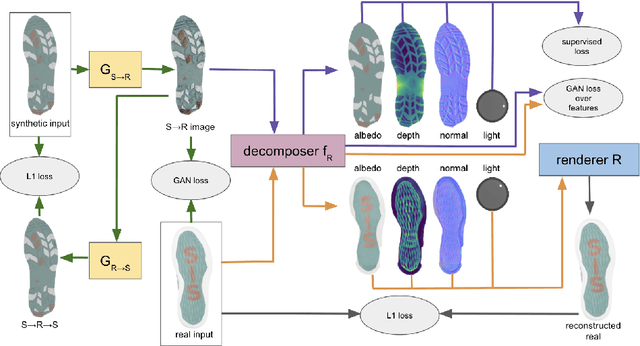


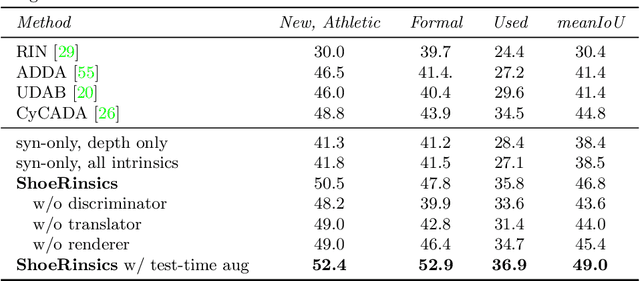
Shoe tread impressions are one of the most common types of evidence left at crime scenes. However, the utility of such evidence is limited by the lack of databases of footwear impression patterns that cover the huge and growing number of distinct shoe models. We propose to address this gap by leveraging shoe tread photographs collected by online retailers. The core challenge is to predict the impression pattern from the shoe photograph since ground-truth impressions or 3D shapes of tread patterns are not available. We develop a model that performs intrinsic image decomposition (predicting depth, normal, albedo, and lighting) from a single tread photo. Our approach, which we term ShoeRinsics, combines domain adaptation and re-rendering losses in order to leverage a mix of fully supervised synthetic data and unsupervised retail image data. To validate model performance, we also collected a set of paired shoe-sole images and corresponding prints, and define a benchmarking protocol to quantify the accuracy of predicted impressions. On this benchmark, ShoeRinsics outperforms existing methods for depth prediction and synthetic-to-real domain adaptation.
Modular Framework for Visuomotor Language Grounding
Sep 05, 2021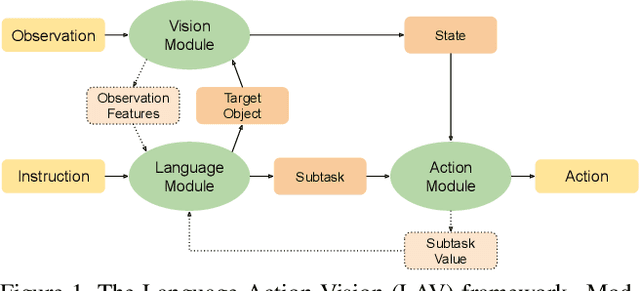
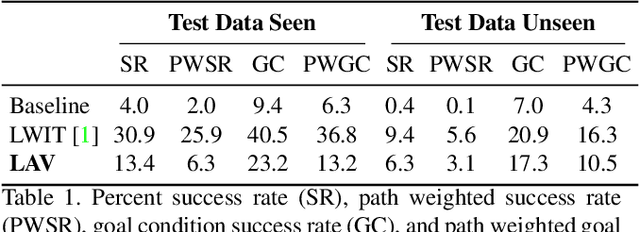
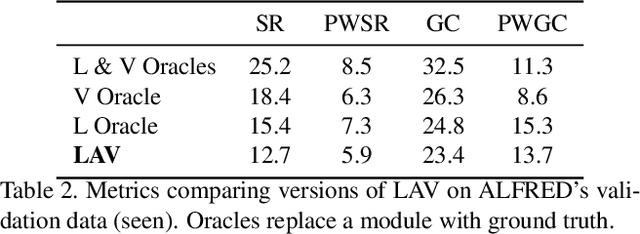
Natural language instruction following tasks serve as a valuable test-bed for grounded language and robotics research. However, data collection for these tasks is expensive and end-to-end approaches suffer from data inefficiency. We propose the structuring of language, acting, and visual tasks into separate modules that can be trained independently. Using a Language, Action, and Vision (LAV) framework removes the dependence of action and vision modules on instruction following datasets, making them more efficient to train. We also present a preliminary evaluation of LAV on the ALFRED task for visual and interactive instruction following.
Predicting Camera Viewpoint Improves Cross-dataset Generalization for 3D Human Pose Estimation
Apr 07, 2020
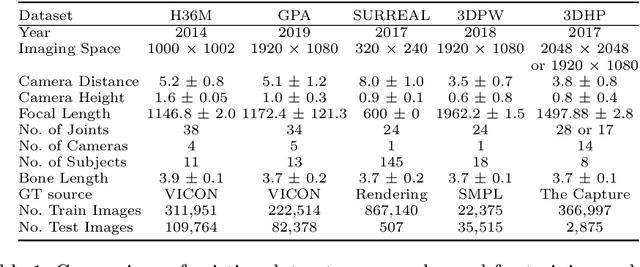
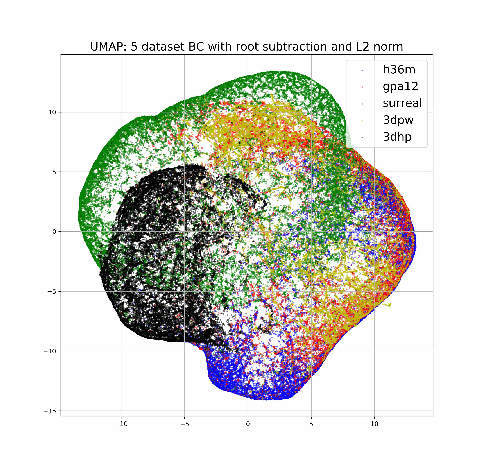
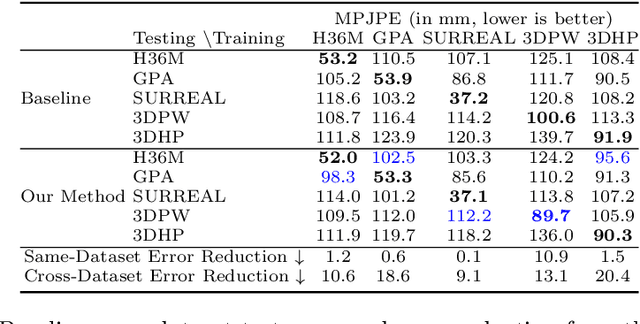
Monocular estimation of 3d human pose has attracted increased attention with the availability of large ground-truth motion capture datasets. However, the diversity of training data available is limited and it is not clear to what extent methods generalize outside the specific datasets they are trained on. In this work we carry out a systematic study of the diversity and biases present in specific datasets and its effect on cross-dataset generalization across a compendium of 5 pose datasets. We specifically focus on systematic differences in the distribution of camera viewpoints relative to a body-centered coordinate frame. Based on this observation, we propose an auxiliary task of predicting the camera viewpoint in addition to pose. We find that models trained to jointly predict viewpoint and pose systematically show significantly improved cross-dataset generalization.
Weakly-supervised Action Localization with Background Modeling
Aug 19, 2019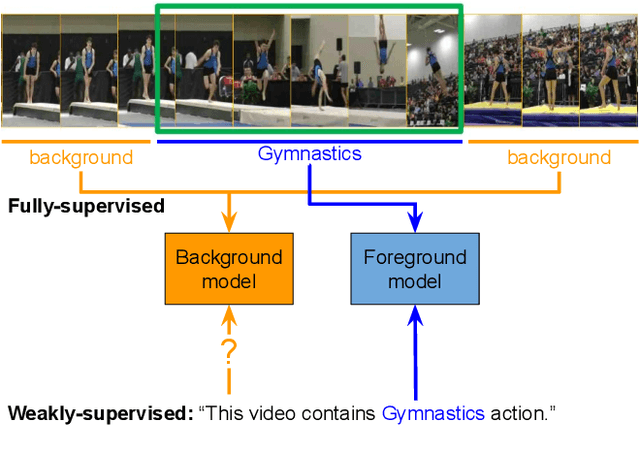
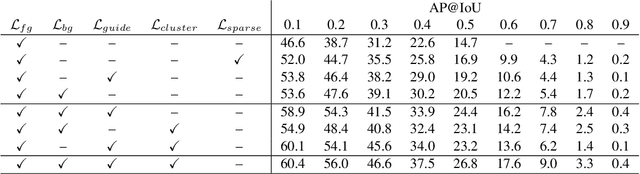
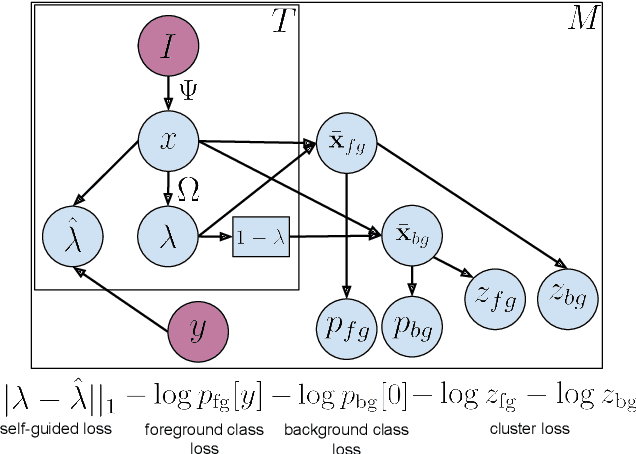
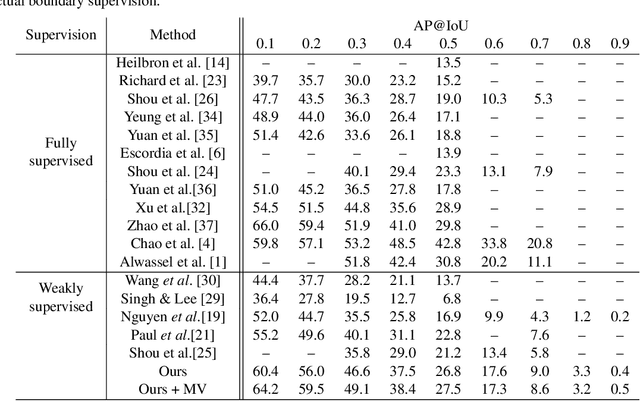
We describe a latent approach that learns to detect actions in long sequences given training videos with only whole-video class labels. Our approach makes use of two innovations to attention-modeling in weakly-supervised learning. First, and most notably, our framework uses an attention model to extract both foreground and background frames whose appearance is explicitly modeled. Most prior works ignore the background, but we show that modeling it allows our system to learn a richer notion of actions and their temporal extents. Second, we combine bottom-up, class-agnostic attention modules with top-down, class-specific activation maps, using the latter as form of self-supervision for the former. Doing so allows our model to learn a more accurate model of attention without explicit temporal supervision. These modifications lead to 10% AP@IoU=0.5 improvement over existing systems on THUMOS14. Our proposed weaklysupervised system outperforms recent state-of-the-arts by at least 4.3% AP@IoU=0.5. Finally, we demonstrate that weakly-supervised learning can be used to aggressively scale-up learning to in-the-wild, uncurated Instagram videos. The addition of these videos significantly improves localization performance of our weakly-supervised model
Multi-layer Depth and Epipolar Feature Transformers for 3D Scene Reconstruction
Feb 18, 2019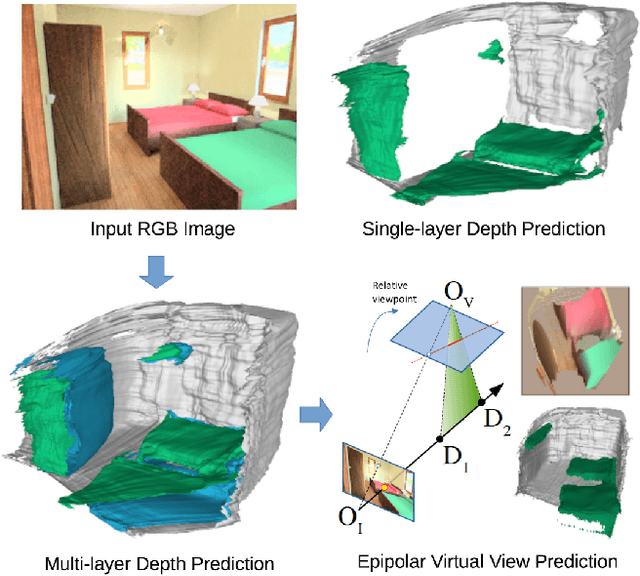
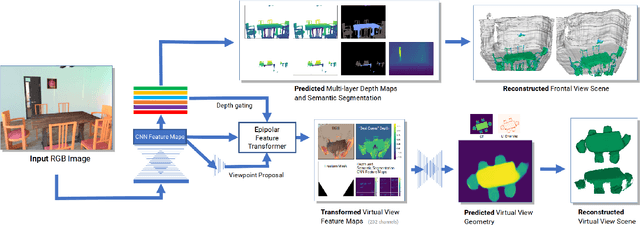

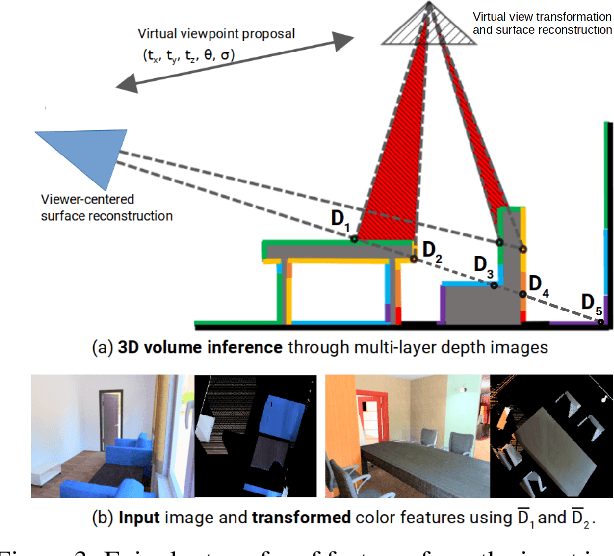
We tackle the problem of automatically reconstructing a complete 3D model of a scene from a single RGB image. This challenging task requires inferring the shape of both visible and occluded surfaces. Our approach utilizes viewer-centered, multi-layer representation of scene geometry adapted from recent methods for single object shape completion. To improve the accuracy of view-centered representations for complex scenes, we introduce a novel "Epipolar Feature Transformer" that transfers convolutional network features from an input view to other virtual camera viewpoints, and thus better covers the 3D scene geometry. Unlike existing approaches that first detect and localize objects in 3D, and then infer object shape using category-specific models, our approach is fully convolutional, end-to-end differentiable, and avoids the resolution and memory limitations of voxel representations. We demonstrate the advantages of multi-layer depth representations and epipolar feature transformers on the reconstruction of a large database of indoor scenes.
Cross-Domain Image Matching with Deep Feature Maps
Oct 01, 2018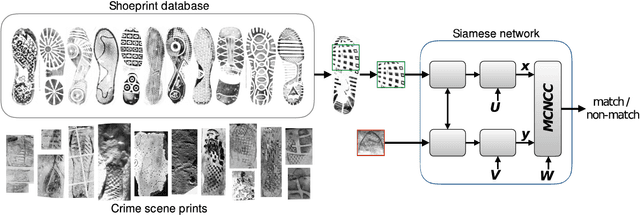
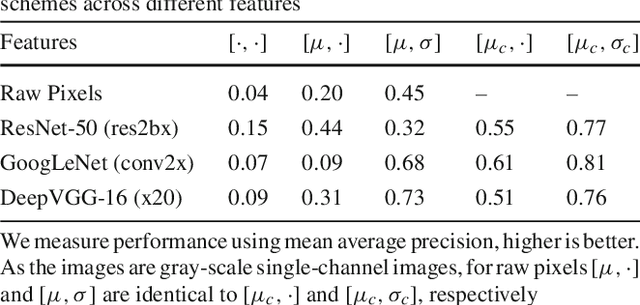
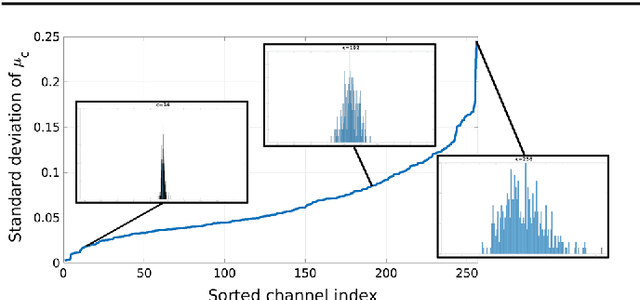
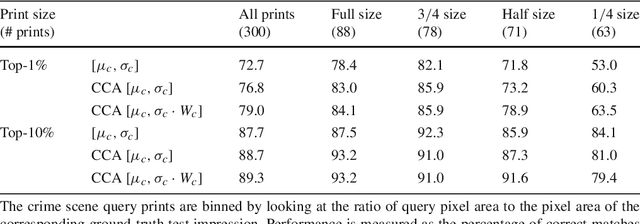
We investigate the problem of automatically determining what type of shoe left an impression found at a crime scene. This recognition problem is made difficult by the variability in types of crime scene evidence (ranging from traces of dust or oil on hard surfaces to impressions made in soil) and the lack of comprehensive databases of shoe outsole tread patterns. We find that mid-level features extracted by pre-trained convolutional neural nets are surprisingly effective descriptors for this specialized domains. However, the choice of similarity measure for matching exemplars to a query image is essential to good performance. For matching multi-channel deep features, we propose the use of multi-channel normalized cross-correlation and analyze its effectiveness. Our proposed metric significantly improves performance in matching crime scene shoeprints to laboratory test impressions. We also show its effectiveness in other cross-domain image retrieval problems: matching facade images to segmentation labels and aerial photos to map images. Finally, we introduce a discriminatively trained variant and fine-tune our system through our proposed metric, obtaining state-of-the-art performance.
Pixels, voxels, and views: A study of shape representations for single view 3D object shape prediction
Jun 12, 2018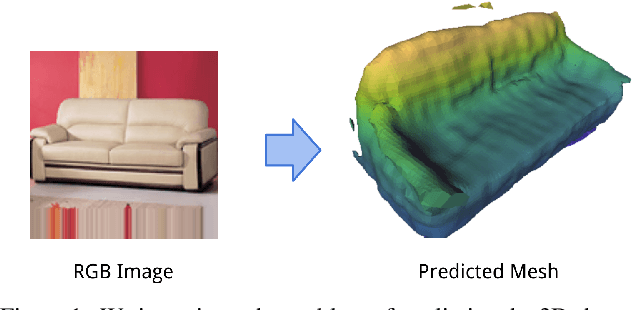


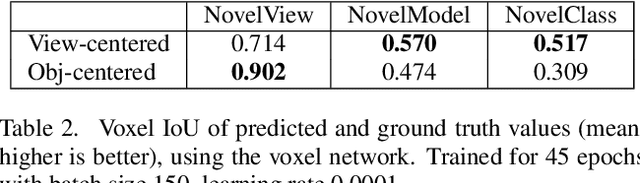
The goal of this paper is to compare surface-based and volumetric 3D object shape representations, as well as viewer-centered and object-centered reference frames for single-view 3D shape prediction. We propose a new algorithm for predicting depth maps from multiple viewpoints, with a single depth or RGB image as input. By modifying the network and the way models are evaluated, we can directly compare the merits of voxels vs. surfaces and viewer-centered vs. object-centered for familiar vs. unfamiliar objects, as predicted from RGB or depth images. Among our findings, we show that surface-based methods outperform voxel representations for objects from novel classes and produce higher resolution outputs. We also find that using viewer-centered coordinates is advantageous for novel objects, while object-centered representations are better for more familiar objects. Interestingly, the coordinate frame significantly affects the shape representation learned, with object-centered placing more importance on implicitly recognizing the object category and viewer-centered producing shape representations with less dependence on category recognition.
Energy-Based Spherical Sparse Coding
Oct 04, 2017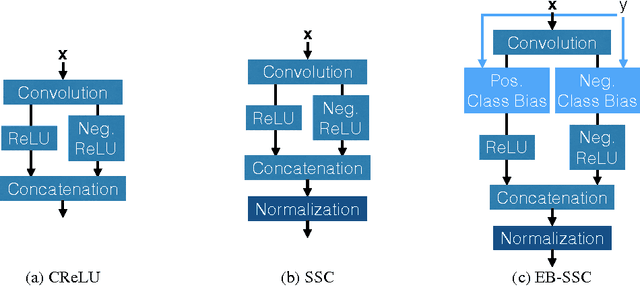
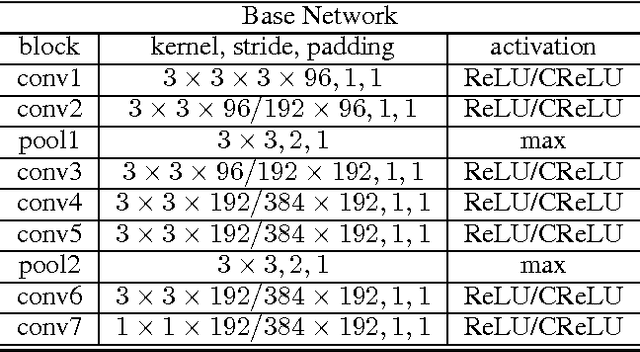
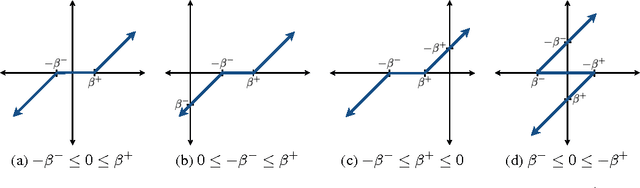
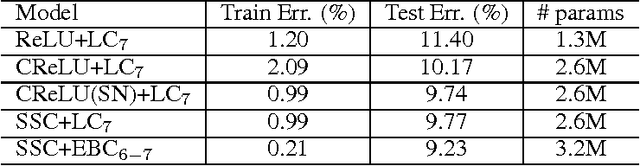
In this paper, we explore an efficient variant of convolutional sparse coding with unit norm code vectors where reconstruction quality is evaluated using an inner product (cosine distance). To use these codes for discriminative classification, we describe a model we term Energy-Based Spherical Sparse Coding (EB-SSC) in which the hypothesized class label introduces a learned linear bias into the coding step. We evaluate and visualize performance of stacking this encoder to make a deep layered model for image classification.
Cluster-Wise Ratio Tests for Fast Camera Localization
May 20, 2017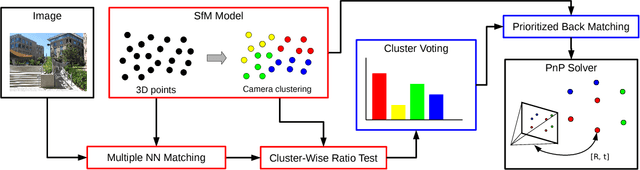
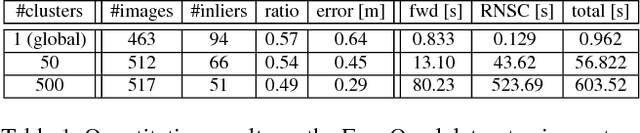
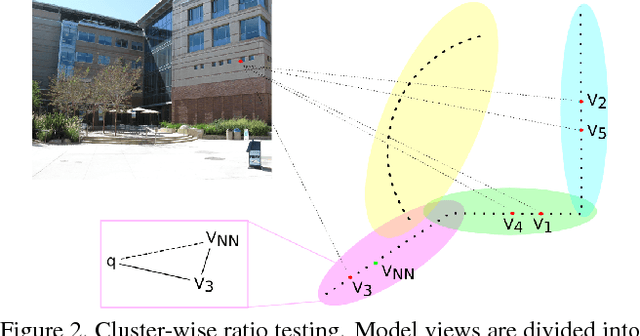
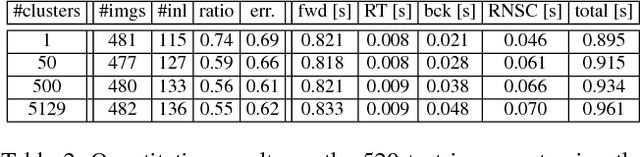
Feature point matching for camera localization suffers from scalability problems. Even when feature descriptors associated with 3D scene points are locally unique, as coverage grows, similar or repeated features become increasingly common. As a result, the standard distance ratio-test used to identify reliable image feature points is overly restrictive and rejects many good candidate matches. We propose a simple coarse-to-fine strategy that uses conservative approximations to robust local ratio-tests that can be computed efficiently using global approximate k-nearest neighbor search. We treat these forward matches as votes in camera pose space and use them to prioritize back-matching within candidate camera pose clusters, exploiting feature co-visibility captured by clustering the 3D model camera pose graph. This approach achieves state-of-the-art camera localization results on a variety of popular benchmarks, outperforming several methods that use more complicated data structures and that make more restrictive assumptions on camera pose. We also carry out diagnostic analyses on a difficult test dataset containing globally repetitive structure that suggest our approach successfully adapts to the challenges of large-scale image localization.
Learning Optimal Parameters for Multi-target Tracking with Contextual Interactions
Oct 05, 2016
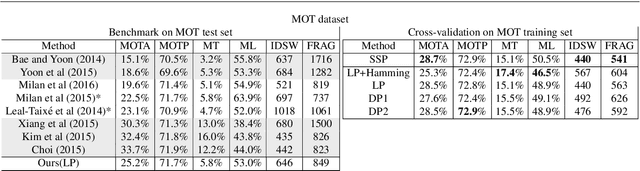

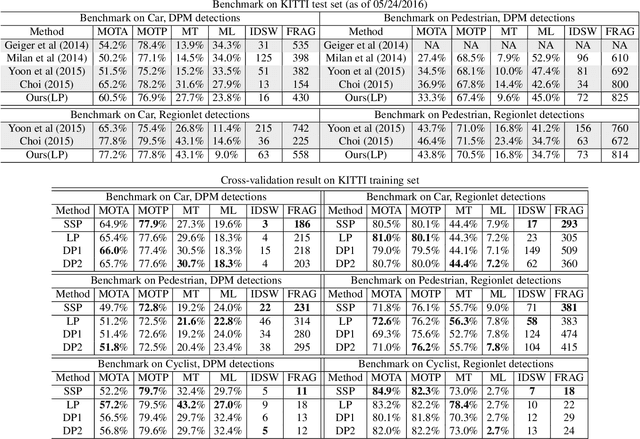
We describe an end-to-end framework for learning parameters of min-cost flow multi-target tracking problem with quadratic trajectory interactions including suppression of overlapping tracks and contextual cues about cooccurrence of different objects. Our approach utilizes structured prediction with a tracking-specific loss function to learn the complete set of model parameters. In this learning framework, we evaluate two different approaches to finding an optimal set of tracks under a quadratic model objective, one based on an LP relaxation and the other based on novel greedy variants of dynamic programming that handle pairwise interactions. We find the greedy algorithms achieve almost equivalent accuracy to the LP relaxation while being up to 10x faster than a commercial LP solver. We evaluate trained models on three challenging benchmarks. Surprisingly, we find that with proper parameter learning, our simple data association model without explicit appearance/motion reasoning is able to achieve comparable or better accuracy than many state-of-the-art methods that use far more complex motion features or appearance affinity metric learning.