 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Demo is Worth a Thousand Trajectories: Action-View Augmentation for Visuomotor Policies
Jun 17, 2026Visuomotor policies for manipulation have demonstrated remarkable potential in modeling complex robotic behaviors, yet minor alterations in the robot's initial configuration and unseen obstacles easily lead to out-of-distribution observations. Without extensive data collection effort, these result in catastrophic execution failures. In this work, we introduce an effective data augmentation framework that generates visually realistic fisheye image sequences and corresponding physically feasible action trajectories from real-world eye-in-hand demonstrations, captured with a portable parallel gripper with a single fisheye camera. We introduce a novel Gaussian Splatting formulation, adapted to wide FoV fisheye cameras, to reconstruct and edit the 3D scene with unseen objects. We utilize trajectory optimization to generate smooth, collision-free, view-rendering-friendly action trajectories and render visual observations from corresponding novel views. Comprehensive experiments in simulation and the real world show that our augmentation framework improves the success rate for various manipulation tasks in both the same scene and the augmented scene with obstacles requiring collision avoidance.
* Project website: https://chuerpan.com/1001-demos.github.io/. Published at CoRL 2025
Universal Manipulation Exoskeleton: Learning Compliant Whole-body Policies with Real-time Torque Feedback
Jun 12, 2026For robots to work safely in household environments, they need to be compliant and react to torque and force feedback during contact. However, the majority of existing data collection pipelines still lack the ability to capture force and torque data for learning active compliant policies. In this paper, we present Universal Manipulation Exoskeleton (UME), an upper-limb exoskeleton that provides real-time haptic torque feedback while recording whole-arm configurations and joint torque signals for teleoperation. With transparent torque feedback, human operators can even unsheathe kinematically constrained objects while blindfolded. UME is low-cost, lightweight, and portable. Equipped with an embedded IMU, it enables teleoperation for mobile manipulation. With our proposed universal retargeting algorithm, UME can teleoperate a range of robots, including the 7DoF OpenArm, 7DoF Franka, and 6DoF X-ARM. We demonstrate that this combination of capabilities enables learning bimanual, whole-body, and active compliant policies that operate effectively in highly constrained spaces. The learned robust autonomous policies achieve high success rates across a variety of tasks, including long-horizon mobile manipulation, force-mediated box flipping, visually occluded box pushing, and space-constrained tabletop manipulation. Videos, code, and additional information can be found at https://ume-exo.github.io.
When Should We Prefer State-to-Visual DAgger Over Visual Reinforcement Learning?
Dec 18, 2024



Learning policies from high-dimensional visual inputs, such as pixels and point clouds, is crucial in various applications. Visual reinforcement learning is a promising approach that directly trains policies from visual observations, although it faces challenges in sample efficiency and computational costs. This study conducts an empirical comparison of State-to-Visual DAgger, a two-stage framework that initially trains a state policy before adopting online imitation to learn a visual policy, and Visual RL across a diverse set of tasks. We evaluate both methods across 16 tasks from three benchmarks, focusing on their asymptotic performance, sample efficiency, and computational costs. Surprisingly, our findings reveal that State-to-Visual DAgger does not universally outperform Visual RL but shows significant advantages in challenging tasks, offering more consistent performance. In contrast, its benefits in sample efficiency are less pronounced, although it often reduces the overall wall-clock time required for training. Based on our findings, we provide recommendations for practitioners and hope that our results contribute valuable perspectives for future research in visual policy learning.
A Quantitative Approach for Evaluating Disease Focus and Interpretability of Deep Learning Models for Alzheimer's Disease Classification
Sep 07, 2024

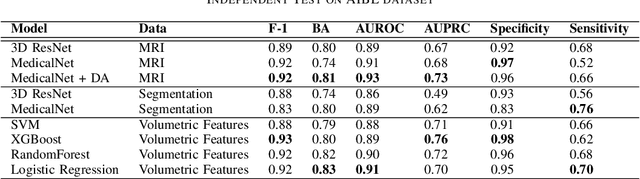

Deep learning (DL) models have shown significant potential in Alzheimer's Disease (AD) classification. However, understanding and interpreting these models remains challenging, which hinders the adoption of these models in clinical practice. Techniques such as saliency maps have been proven effective in providing visual and empirical clues about how these models work, but there still remains a gap in understanding which specific brain regions DL models focus on and whether these brain regions are pathologically associated with AD. To bridge such gap, in this study, we developed a quantitative disease-focusing strategy to first enhance the interpretability of DL models using saliency maps and brain segmentations; then we propose a disease-focus (DF) score that quantifies how much a DL model focuses on brain areas relevant to AD pathology based on clinically known MRI-based pathological regions of AD. Using this strategy, we compared several state-of-the-art DL models, including a baseline 3D ResNet model, a pretrained MedicalNet model, and a MedicalNet with data augmentation to classify patients with AD vs. cognitive normal patients using MRI data; then we evaluated these models in terms of their abilities to focus on disease-relevant regions. Our results show interesting disease-focusing patterns with different models, particularly characteristic patterns with the pretrained models and data augmentation, and also provide insight into their classification performance. These results suggest that the approach we developed for quantitatively assessing the abilities of DL models to focus on disease-relevant regions may help improve interpretability of these models for AD classification and facilitate their adoption for AD diagnosis in clinical practice. The code is publicly available at https://github.com/Liang-lt/ADNI.
Robo360: A 3D Omnispective Multi-Material Robotic Manipulation Dataset
Dec 09, 2023
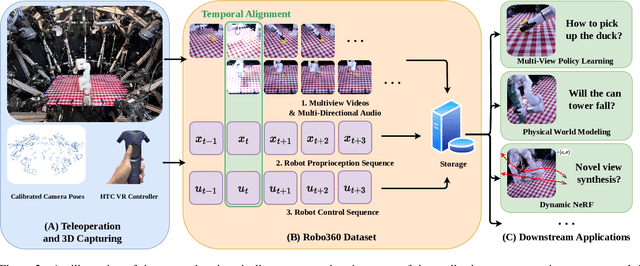
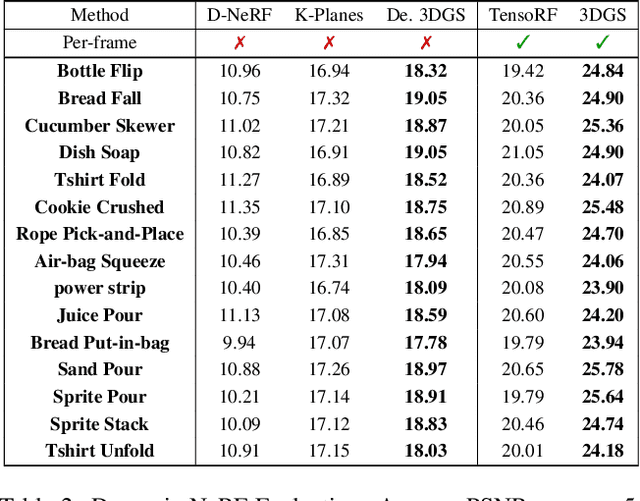

Building robots that can automate labor-intensive tasks has long been the core motivation behind the advancements in computer vision and the robotics community. Recent interest in leveraging 3D algorithms, particularly neural fields, has led to advancements in robot perception and physical understanding in manipulation scenarios. However, the real world's complexity poses significant challenges. To tackle these challenges, we present Robo360, a dataset that features robotic manipulation with a dense view coverage, which enables high-quality 3D neural representation learning, and a diverse set of objects with various physical and optical properties and facilitates research in various object manipulation and physical world modeling tasks. We confirm the effectiveness of our dataset using existing dynamic NeRF and evaluate its potential in learning multi-view policies. We hope that Robo360 can open new research directions yet to be explored at the intersection of understanding the physical world in 3D and robot control.
Reparameterized Policy Learning for Multimodal Trajectory Optimization
Jul 20, 2023



We investigate the challenge of parametrizing policies for reinforcement learning (RL) in high-dimensional continuous action spaces. Our objective is to develop a multimodal policy that overcomes limitations inherent in the commonly-used Gaussian parameterization. To achieve this, we propose a principled framework that models the continuous RL policy as a generative model of optimal trajectories. By conditioning the policy on a latent variable, we derive a novel variational bound as the optimization objective, which promotes exploration of the environment. We then present a practical model-based RL method, called Reparameterized Policy Gradient (RPG), which leverages the multimodal policy parameterization and learned world model to achieve strong exploration capabilities and high data efficiency. Empirical results demonstrate that our method can help agents evade local optima in tasks with dense rewards and solve challenging sparse-reward environments by incorporating an object-centric intrinsic reward. Our method consistently outperforms previous approaches across a range of tasks. Code and supplementary materials are available on the project page https://haosulab.github.io/RPG/
Reducing Variance in Temporal-Difference Value Estimation via Ensemble of Deep Networks
Sep 16, 2022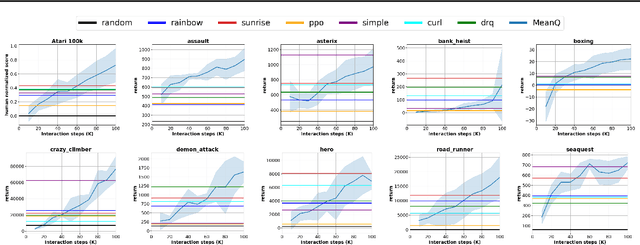

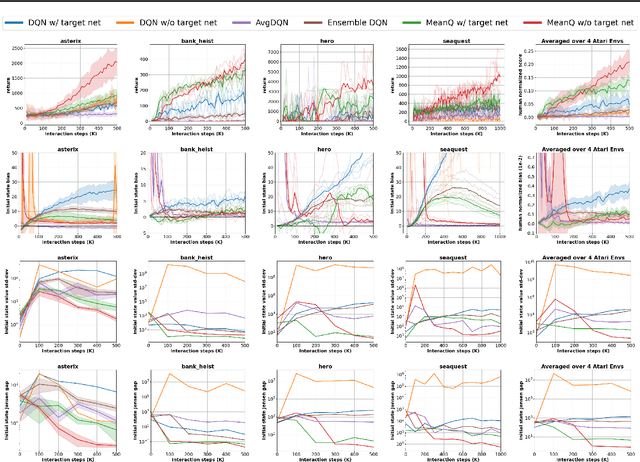
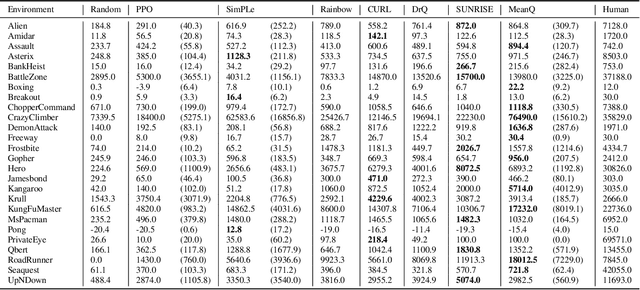
In temporal-difference reinforcement learning algorithms, variance in value estimation can cause instability and overestimation of the maximal target value. Many algorithms have been proposed to reduce overestimation, including several recent ensemble methods, however none have shown success in sample-efficient learning through addressing estimation variance as the root cause of overestimation. In this paper, we propose MeanQ, a simple ensemble method that estimates target values as ensemble means. Despite its simplicity, MeanQ shows remarkable sample efficiency in experiments on the Atari Learning Environment benchmark. Importantly, we find that an ensemble of size 5 sufficiently reduces estimation variance to obviate the lagging target network, eliminating it as a source of bias and further gaining sample efficiency. We justify intuitively and empirically the design choices in MeanQ, including the necessity of independent experience sampling. On a set of 26 benchmark Atari environments, MeanQ outperforms all tested baselines, including the best available baseline, SUNRISE, at 100K interaction steps in 16/26 environments, and by 68% on average. MeanQ also outperforms Rainbow DQN at 500K steps in 21/26 environments, and by 49% on average, and achieves average human-level performance using 200K ($\pm$100K) interaction steps. Our implementation is available at https://github.com/indylab/MeanQ.
Target Entropy Annealing for Discrete Soft Actor-Critic
Dec 06, 2021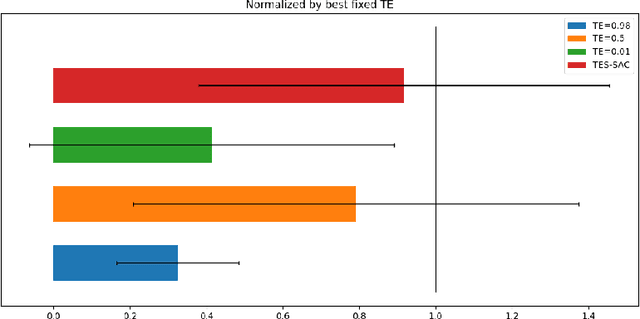
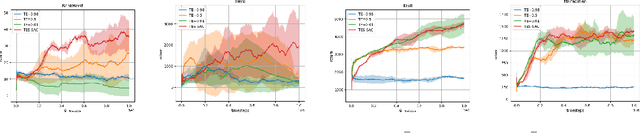
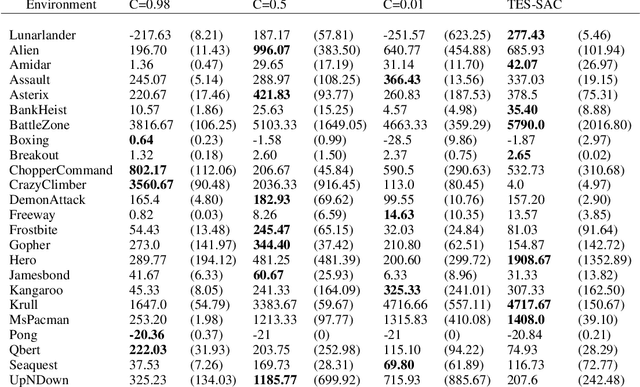
Soft Actor-Critic (SAC) is considered the state-of-the-art algorithm in continuous action space settings. It uses the maximum entropy framework for efficiency and stability, and applies a heuristic temperature Lagrange term to tune the temperature $\alpha$, which determines how "soft" the policy should be. It is counter-intuitive that empirical evidence shows SAC does not perform well in discrete domains. In this paper we investigate the possible explanations for this phenomenon and propose Target Entropy Scheduled SAC (TES-SAC), an annealing method for the target entropy parameter applied on SAC. Target entropy is a constant in the temperature Lagrange term and represents the target policy entropy in discrete SAC. We compare our method on Atari 2600 games with different constant target entropy SAC, and analyze on how our scheduling affects SAC.
Temporal-Difference Value Estimation via Uncertainty-Guided Soft Updates
Oct 28, 2021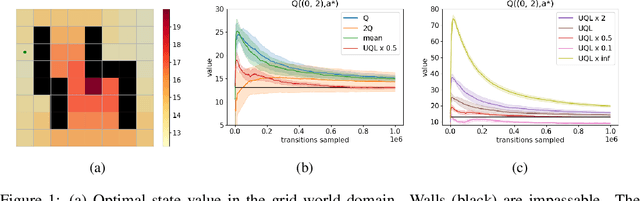

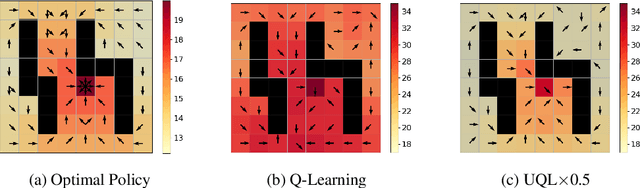
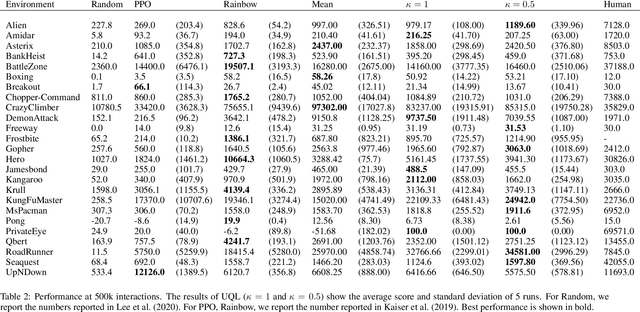
Temporal-Difference (TD) learning methods, such as Q-Learning, have proven effective at learning a policy to perform control tasks. One issue with methods like Q-Learning is that the value update introduces bias when predicting the TD target of a unfamiliar state. Estimation noise becomes a bias after the max operator in the policy improvement step, and carries over to value estimations of other states, causing Q-Learning to overestimate the Q value. Algorithms like Soft Q-Learning (SQL) introduce the notion of a soft-greedy policy, which reduces the estimation bias via soft updates in early stages of training. However, the inverse temperature $\beta$ that controls the softness of an update is usually set by a hand-designed heuristic, which can be inaccurate at capturing the uncertainty in the target estimate. Under the belief that $\beta$ is closely related to the (state dependent) model uncertainty, Entropy Regularized Q-Learning (EQL) further introduces a principled scheduling of $\beta$ by maintaining a collection of the model parameters that characterizes model uncertainty. In this paper, we present Unbiased Soft Q-Learning (UQL), which extends the work of EQL from two action, finite state spaces to multi-action, infinite state space Markov Decision Processes. We also provide a principled numerical scheduling of $\beta$, extended from SQL and using model uncertainty, during the optimization process. We show the theoretical guarantees and the effectiveness of this update method in experiments on several discrete control environments.
Modular Framework for Visuomotor Language Grounding
Sep 05, 2021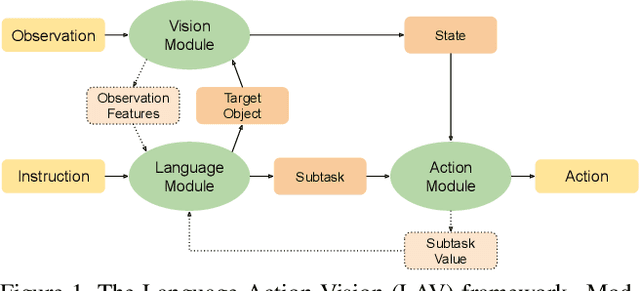
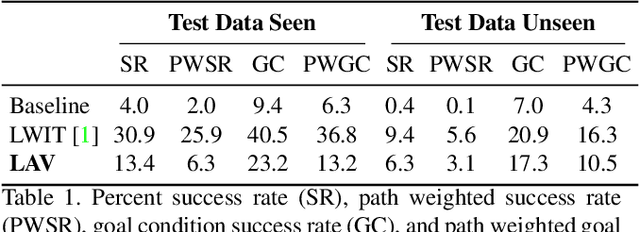
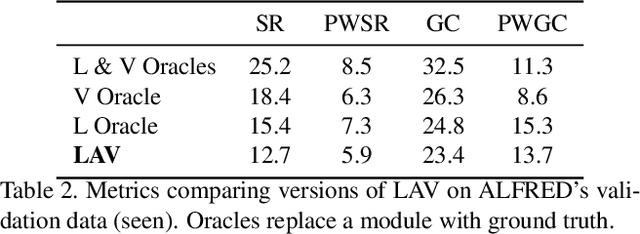
Natural language instruction following tasks serve as a valuable test-bed for grounded language and robotics research. However, data collection for these tasks is expensive and end-to-end approaches suffer from data inefficiency. We propose the structuring of language, acting, and visual tasks into separate modules that can be trained independently. Using a Language, Action, and Vision (LAV) framework removes the dependence of action and vision modules on instruction following datasets, making them more efficient to train. We also present a preliminary evaluation of LAV on the ALFRED task for visual and interactive instruction following.