 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Quantitative Approach for Evaluating Disease Focus and Interpretability of Deep Learning Models for Alzheimer's Disease Classification
Sep 07, 2024

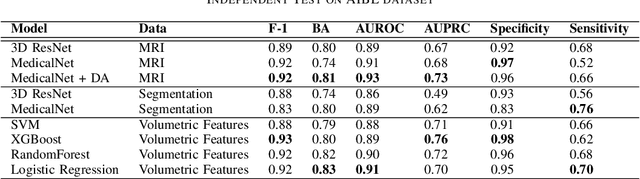

Deep learning (DL) models have shown significant potential in Alzheimer's Disease (AD) classification. However, understanding and interpreting these models remains challenging, which hinders the adoption of these models in clinical practice. Techniques such as saliency maps have been proven effective in providing visual and empirical clues about how these models work, but there still remains a gap in understanding which specific brain regions DL models focus on and whether these brain regions are pathologically associated with AD. To bridge such gap, in this study, we developed a quantitative disease-focusing strategy to first enhance the interpretability of DL models using saliency maps and brain segmentations; then we propose a disease-focus (DF) score that quantifies how much a DL model focuses on brain areas relevant to AD pathology based on clinically known MRI-based pathological regions of AD. Using this strategy, we compared several state-of-the-art DL models, including a baseline 3D ResNet model, a pretrained MedicalNet model, and a MedicalNet with data augmentation to classify patients with AD vs. cognitive normal patients using MRI data; then we evaluated these models in terms of their abilities to focus on disease-relevant regions. Our results show interesting disease-focusing patterns with different models, particularly characteristic patterns with the pretrained models and data augmentation, and also provide insight into their classification performance. These results suggest that the approach we developed for quantitatively assessing the abilities of DL models to focus on disease-relevant regions may help improve interpretability of these models for AD classification and facilitate their adoption for AD diagnosis in clinical practice. The code is publicly available at https://github.com/Liang-lt/ADNI.
A Literature Review and Framework for Human Evaluation of Generative Large Language Models in Healthcare
May 04, 2024As generative artificial intelligence (AI), particularly Large Language Models (LLMs), continues to permeate healthcare, it remains crucial to supplement traditional automated evaluations with human expert evaluation. Understanding and evaluating the generated texts is vital for ensuring safety, reliability, and effectiveness. However, the cumbersome, time-consuming, and non-standardized nature of human evaluation presents significant obstacles to the widespread adoption of LLMs in practice. This study reviews existing literature on human evaluation methodologies for LLMs within healthcare. We highlight a notable need for a standardized and consistent human evaluation approach. Our extensive literature search, adhering to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, spans publications from January 2018 to February 2024. This review provides a comprehensive overview of the human evaluation approaches used in diverse healthcare applications.This analysis examines the human evaluation of LLMs across various medical specialties, addressing factors such as evaluation dimensions, sample types, and sizes, the selection and recruitment of evaluators, frameworks and metrics, the evaluation process, and statistical analysis of the results. Drawing from diverse evaluation strategies highlighted in these studies, we propose a comprehensive and practical framework for human evaluation of generative LLMs, named QUEST: Quality of Information, Understanding and Reasoning, Expression Style and Persona, Safety and Harm, and Trust and Confidence. This framework aims to improve the reliability, generalizability, and applicability of human evaluation of generative LLMs in different healthcare applications by defining clear evaluation dimensions and offering detailed guidelines.