 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Adjudication of Cardiovascular Events Using Large Language Models
Mar 21, 2025Cardiovascular events, such as heart attacks and strokes, remain a leading cause of mortality globally, necessitating meticulous monitoring and adjudication in clinical trials. This process, traditionally performed manually by clinical experts, is time-consuming, resource-intensive, and prone to inter-reviewer variability, potentially introducing bias and hindering trial progress. This study addresses these critical limitations by presenting a novel framework for automating the adjudication of cardiovascular events in clinical trials using Large Language Models (LLMs). We developed a two-stage approach: first, employing an LLM-based pipeline for event information extraction from unstructured clinical data and second, using an LLM-based adjudication process guided by a Tree of Thoughts approach and clinical endpoint committee (CEC) guidelines. Using cardiovascular event-specific clinical trial data, the framework achieved an F1-score of 0.82 for event extraction and an accuracy of 0.68 for adjudication. Furthermore, we introduce the CLEART score, a novel, automated metric specifically designed for evaluating the quality of AI-generated clinical reasoning in adjudicating cardiovascular events. This approach demonstrates significant potential for substantially reducing adjudication time and costs while maintaining high-quality, consistent, and auditable outcomes in clinical trials. The reduced variability and enhanced standardization also allow for faster identification and mitigation of risks associated with cardiovascular therapies.
Mitigating the Risk of Health Inequity Exacerbated by Large Language Models
Oct 14, 2024Recent advancements in large language models have demonstrated their potential in numerous medical applications, particularly in automating clinical trial matching for translational research and enhancing medical question answering for clinical decision support. However, our study shows that incorporating non decisive sociodemographic factors such as race, sex, income level, LGBT+ status, homelessness, illiteracy, disability, and unemployment into the input of LLMs can lead to incorrect and harmful outputs for these populations. These discrepancies risk exacerbating existing health disparities if LLMs are widely adopted in healthcare. To address this issue, we introduce EquityGuard, a novel framework designed to detect and mitigate the risk of health inequities in LLM based medical applications. Our evaluation demonstrates its efficacy in promoting equitable outcomes across diverse populations.
Enhancing Equity in Large Language Models for Medical Applications
Oct 07, 2024Recent advancements have highlighted the potential of large language models (LLMs) in medical applications, notably in automating Clinical Trial Matching for translational research and providing medical question-answering for clinical decision support. However, our study reveals significant inequities in the use of LLMs, particularly for individuals from specific racial, gender, and underrepresented groups influenced by social determinants of health. These disparities could worsen existing health inequities if LLMs are broadly adopted in healthcare. To address this, we propose and evaluate a novel framework, EquityGuard, designed to detect and mitigate biases in LLM-based medical applications. EquityGuard incorporates a Bias Detection Mechanism capable of identifying and correcting unfair predictions, thus enhancing outcomes and promoting equity across diverse population groups.
RAG-RLRC-LaySum at BioLaySumm: Integrating Retrieval-Augmented Generation and Readability Control for Layman Summarization of Biomedical Texts
May 21, 2024This paper introduces the RAG-RLRC-LaySum framework, designed to make complex biomedical research understandable to laymen through advanced Natural Language Processing (NLP) techniques. Our Retrieval Augmented Generation (RAG) solution, enhanced by a reranking method, utilizes multiple knowledge sources to ensure the precision and pertinence of lay summaries. Additionally, our Reinforcement Learning for Readability Control (RLRC) strategy improves readability, making scientific content comprehensible to non-specialists. Evaluations using the publicly accessible PLOS and eLife datasets show that our methods surpass Plain Gemini model, demonstrating a 20% increase in readability scores, a 15% improvement in ROUGE-2 relevance scores, and a 10% enhancement in factual accuracy. The RAG-RLRC-LaySum framework effectively democratizes scientific knowledge, enhancing public engagement with biomedical discoveries.
Precision Rehabilitation for Patients Post-Stroke based on Electronic Health Records and Machine Learning
May 09, 2024



In this study, we utilized statistical analysis and machine learning methods to examine whether rehabilitation exercises can improve patients post-stroke functional abilities, as well as forecast the improvement in functional abilities. Our dataset is patients' rehabilitation exercises and demographic information recorded in the unstructured electronic health records (EHRs) data and free-text rehabilitation procedure notes. We collected data for 265 stroke patients from the University of Pittsburgh Medical Center. We employed a pre-existing natural language processing (NLP) algorithm to extract data on rehabilitation exercises and developed a rule-based NLP algorithm to extract Activity Measure for Post-Acute Care (AM-PAC) scores, covering basic mobility (BM) and applied cognitive (AC) domains, from procedure notes. Changes in AM-PAC scores were classified based on the minimal clinically important difference (MCID), and significance was assessed using Friedman and Wilcoxon tests. To identify impactful exercises, we used Chi-square tests, Fisher's exact tests, and logistic regression for odds ratios. Additionally, we developed five machine learning models-logistic regression (LR), Adaboost (ADB), support vector machine (SVM), gradient boosting (GB), and random forest (RF)-to predict outcomes in functional ability. Statistical analyses revealed significant associations between functional improvements and specific exercises. The RF model achieved the best performance in predicting functional outcomes. In this study, we identified three rehabilitation exercises that significantly contributed to patient post-stroke functional ability improvement in the first two months. Additionally, the successful application of a machine learning model to predict patient-specific functional outcomes underscores the potential for precision rehabilitation.
A Literature Review and Framework for Human Evaluation of Generative Large Language Models in Healthcare
May 04, 2024As generative artificial intelligence (AI), particularly Large Language Models (LLMs), continues to permeate healthcare, it remains crucial to supplement traditional automated evaluations with human expert evaluation. Understanding and evaluating the generated texts is vital for ensuring safety, reliability, and effectiveness. However, the cumbersome, time-consuming, and non-standardized nature of human evaluation presents significant obstacles to the widespread adoption of LLMs in practice. This study reviews existing literature on human evaluation methodologies for LLMs within healthcare. We highlight a notable need for a standardized and consistent human evaluation approach. Our extensive literature search, adhering to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, spans publications from January 2018 to February 2024. This review provides a comprehensive overview of the human evaluation approaches used in diverse healthcare applications.This analysis examines the human evaluation of LLMs across various medical specialties, addressing factors such as evaluation dimensions, sample types, and sizes, the selection and recruitment of evaluators, frameworks and metrics, the evaluation process, and statistical analysis of the results. Drawing from diverse evaluation strategies highlighted in these studies, we propose a comprehensive and practical framework for human evaluation of generative LLMs, named QUEST: Quality of Information, Understanding and Reasoning, Expression Style and Persona, Safety and Harm, and Trust and Confidence. This framework aims to improve the reliability, generalizability, and applicability of human evaluation of generative LLMs in different healthcare applications by defining clear evaluation dimensions and offering detailed guidelines.
Generation of a Compendium of Transcription Factor Cascades and Identification of Potential Therapeutic Targets using Graph Machine Learning
Nov 29, 2023



Transcription factors (TFs) play a vital role in the regulation of gene expression thereby making them critical to many cellular processes. In this study, we used graph machine learning methods to create a compendium of TF cascades using data extracted from the STRING database. A TF cascade is a sequence of TFs that regulate each other, forming a directed path in the TF network. We constructed a knowledge graph of 81,488 unique TF cascades, with the longest cascade consisting of 62 TFs. Our results highlight the complex and intricate nature of TF interactions, where multiple TFs work together to regulate gene expression. We also identified 10 TFs with the highest regulatory influence based on centrality measurements, providing valuable information for researchers interested in studying specific TFs. Furthermore, our pathway enrichment analysis revealed significant enrichment of various pathways and functional categories, including those involved in cancer and other diseases, as well as those involved in development, differentiation, and cell signaling. The enriched pathways identified in this study may have potential as targets for therapeutic intervention in diseases associated with dysregulation of transcription factors. We have released the dataset, knowledge graph, and graphML methods for the TF cascades, and created a website to display the results, which can be accessed by researchers interested in using this dataset. Our study provides a valuable resource for understanding the complex network of interactions between TFs and their regulatory roles in cellular processes.
An Empirical Evaluation of Prompting Strategies for Large Language Models in Zero-Shot Clinical Natural Language Processing
Sep 14, 2023Large language models (LLMs) have shown remarkable capabilities in Natural Language Processing (NLP), especially in domains where labeled data is scarce or expensive, such as clinical domain. However, to unlock the clinical knowledge hidden in these LLMs, we need to design effective prompts that can guide them to perform specific clinical NLP tasks without any task-specific training data. This is known as in-context learning, which is an art and science that requires understanding the strengths and weaknesses of different LLMs and prompt engineering approaches. In this paper, we present a comprehensive and systematic experimental study on prompt engineering for five clinical NLP tasks: Clinical Sense Disambiguation, Biomedical Evidence Extraction, Coreference Resolution, Medication Status Extraction, and Medication Attribute Extraction. We assessed the prompts proposed in recent literature, including simple prefix, simple cloze, chain of thought, and anticipatory prompts, and introduced two new types of prompts, namely heuristic prompting and ensemble prompting. We evaluated the performance of these prompts on three state-of-the-art LLMs: GPT-3.5, BARD, and LLAMA2. We also contrasted zero-shot prompting with few-shot prompting, and provide novel insights and guidelines for prompt engineering for LLMs in clinical NLP. To the best of our knowledge, this is one of the first works on the empirical evaluation of different prompt engineering approaches for clinical NLP in this era of generative AI, and we hope that it will inspire and inform future research in this area.
Fair Patient Model: Mitigating Bias in the Patient Representation Learned from the Electronic Health Records
Jun 05, 2023



Objective: To pre-train fair and unbiased patient representations from Electronic Health Records (EHRs) using a novel weighted loss function that reduces bias and improves fairness in deep representation learning models. Methods: We defined a new loss function, called weighted loss function, in the deep representation learning model to balance the importance of different groups of patients and features. We applied the proposed model, called Fair Patient Model (FPM), to a sample of 34,739 patients from the MIMIC-III dataset and learned patient representations for four clinical outcome prediction tasks. Results: FPM outperformed the baseline models in terms of three fairness metrics: demographic parity, equality of opportunity difference, and equalized odds ratio. FPM also achieved comparable predictive performance with the baselines, with an average accuracy of 0.7912. Feature analysis revealed that FPM captured more information from clinical features than the baselines. Conclusion: FPM is a novel method to pre-train fair and unbiased patient representations from EHR data using a weighted loss function. The learned representations can be used for various downstream tasks in healthcare and can be extended to other domains where bias and fairness are important.
Few-Shot Learning for Clinical Natural Language Processing Using Siamese Neural Networks
Aug 31, 2022

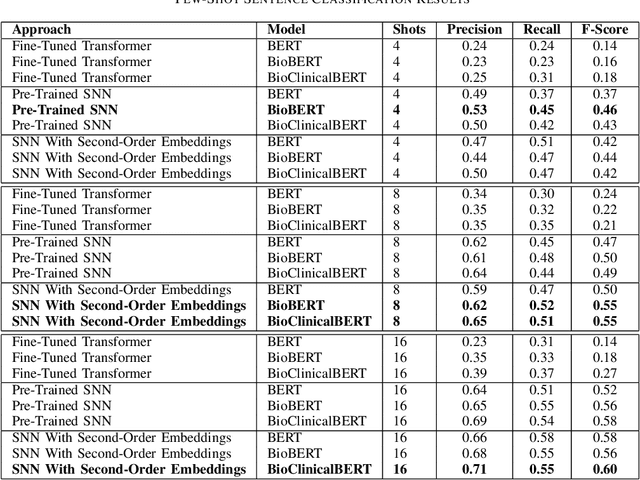
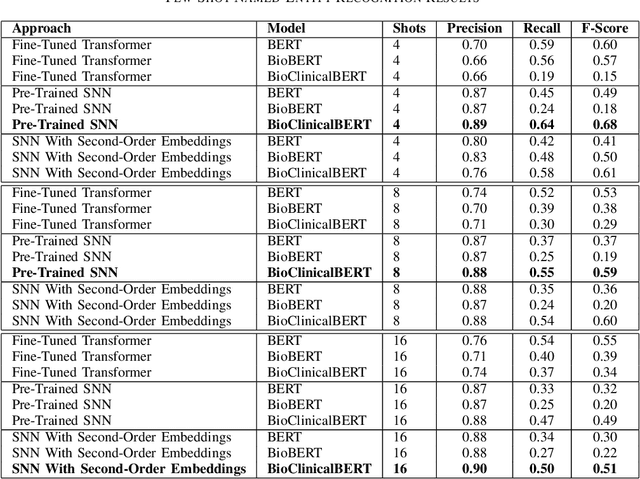
Clinical Natural Language Processing (NLP) has become an emerging technology in healthcare that leverages a large amount of free-text data in electronic health records (EHRs) to improve patient care, support clinical decisions, and facilitate clinical and translational science research. Deep learning has achieved state-of-the-art performance in many clinical NLP tasks. However, training deep learning models usually require large annotated datasets, which are normally not publicly available and can be time-consuming to build in clinical domains. Working with smaller annotated datasets is typical in clinical NLP and therefore, ensuring that deep learning models perform well is crucial for the models to be used in real-world applications. A widely adopted approach is fine-tuning existing Pre-trained Language Models (PLMs), but these attempts fall short when the training dataset contains only a few annotated samples. Few-Shot Learning (FSL) has recently been investigated to tackle this problem. Siamese Neural Network (SNN) has been widely utilized as an FSL approach in computer vision, but has not been studied well in NLP. Furthermore, the literature on its applications in clinical domains is scarce. In this paper, we propose two SNN-based FSL approaches for clinical NLP, including pre-trained SNN (PT-SNN) and SNN with second-order embeddings (SOE-SNN). We evaluated the proposed approaches on two clinical tasks, namely clinical text classification and clinical named entity recognition. We tested three few-shot settings including 4-shot, 8-shot, and 16-shot learning. Both clinical NLP tasks were benchmarked using three PLMs, including BERT, BioBERT, and BioClinicalBERT. The experimental results verified the effectiveness of the proposed SNN-based FSL approaches in both clinical NLP tasks.