 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating the Risk of Health Inequity Exacerbated by Large Language Models
Oct 14, 2024Recent advancements in large language models have demonstrated their potential in numerous medical applications, particularly in automating clinical trial matching for translational research and enhancing medical question answering for clinical decision support. However, our study shows that incorporating non decisive sociodemographic factors such as race, sex, income level, LGBT+ status, homelessness, illiteracy, disability, and unemployment into the input of LLMs can lead to incorrect and harmful outputs for these populations. These discrepancies risk exacerbating existing health disparities if LLMs are widely adopted in healthcare. To address this issue, we introduce EquityGuard, a novel framework designed to detect and mitigate the risk of health inequities in LLM based medical applications. Our evaluation demonstrates its efficacy in promoting equitable outcomes across diverse populations.
Enhancing Equity in Large Language Models for Medical Applications
Oct 07, 2024Recent advancements have highlighted the potential of large language models (LLMs) in medical applications, notably in automating Clinical Trial Matching for translational research and providing medical question-answering for clinical decision support. However, our study reveals significant inequities in the use of LLMs, particularly for individuals from specific racial, gender, and underrepresented groups influenced by social determinants of health. These disparities could worsen existing health inequities if LLMs are broadly adopted in healthcare. To address this, we propose and evaluate a novel framework, EquityGuard, designed to detect and mitigate biases in LLM-based medical applications. EquityGuard incorporates a Bias Detection Mechanism capable of identifying and correcting unfair predictions, thus enhancing outcomes and promoting equity across diverse population groups.
Mammo-CLIP: A Vision Language Foundation Model to Enhance Data Efficiency and Robustness in Mammography
May 22, 2024The lack of large and diverse training data on Computer-Aided Diagnosis (CAD) in breast cancer detection has been one of the concerns that impedes the adoption of the system. Recently, pre-training with large-scale image text datasets via Vision-Language models (VLM) (\eg CLIP) partially addresses the issue of robustness and data efficiency in computer vision (CV). This paper proposes Mammo-CLIP, the first VLM pre-trained on a substantial amount of screening mammogram-report pairs, addressing the challenges of dataset diversity and size. Our experiments on two public datasets demonstrate strong performance in classifying and localizing various mammographic attributes crucial for breast cancer detection, showcasing data efficiency and robustness similar to CLIP in CV. We also propose Mammo-FActOR, a novel feature attribution method, to provide spatial interpretation of representation with sentence-level granularity within mammography reports. Code is available publicly: \url{https://github.com/batmanlab/Mammo-CLIP}.
Precision Rehabilitation for Patients Post-Stroke based on Electronic Health Records and Machine Learning
May 09, 2024



In this study, we utilized statistical analysis and machine learning methods to examine whether rehabilitation exercises can improve patients post-stroke functional abilities, as well as forecast the improvement in functional abilities. Our dataset is patients' rehabilitation exercises and demographic information recorded in the unstructured electronic health records (EHRs) data and free-text rehabilitation procedure notes. We collected data for 265 stroke patients from the University of Pittsburgh Medical Center. We employed a pre-existing natural language processing (NLP) algorithm to extract data on rehabilitation exercises and developed a rule-based NLP algorithm to extract Activity Measure for Post-Acute Care (AM-PAC) scores, covering basic mobility (BM) and applied cognitive (AC) domains, from procedure notes. Changes in AM-PAC scores were classified based on the minimal clinically important difference (MCID), and significance was assessed using Friedman and Wilcoxon tests. To identify impactful exercises, we used Chi-square tests, Fisher's exact tests, and logistic regression for odds ratios. Additionally, we developed five machine learning models-logistic regression (LR), Adaboost (ADB), support vector machine (SVM), gradient boosting (GB), and random forest (RF)-to predict outcomes in functional ability. Statistical analyses revealed significant associations between functional improvements and specific exercises. The RF model achieved the best performance in predicting functional outcomes. In this study, we identified three rehabilitation exercises that significantly contributed to patient post-stroke functional ability improvement in the first two months. Additionally, the successful application of a machine learning model to predict patient-specific functional outcomes underscores the potential for precision rehabilitation.
A Literature Review and Framework for Human Evaluation of Generative Large Language Models in Healthcare
May 04, 2024As generative artificial intelligence (AI), particularly Large Language Models (LLMs), continues to permeate healthcare, it remains crucial to supplement traditional automated evaluations with human expert evaluation. Understanding and evaluating the generated texts is vital for ensuring safety, reliability, and effectiveness. However, the cumbersome, time-consuming, and non-standardized nature of human evaluation presents significant obstacles to the widespread adoption of LLMs in practice. This study reviews existing literature on human evaluation methodologies for LLMs within healthcare. We highlight a notable need for a standardized and consistent human evaluation approach. Our extensive literature search, adhering to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, spans publications from January 2018 to February 2024. This review provides a comprehensive overview of the human evaluation approaches used in diverse healthcare applications.This analysis examines the human evaluation of LLMs across various medical specialties, addressing factors such as evaluation dimensions, sample types, and sizes, the selection and recruitment of evaluators, frameworks and metrics, the evaluation process, and statistical analysis of the results. Drawing from diverse evaluation strategies highlighted in these studies, we propose a comprehensive and practical framework for human evaluation of generative LLMs, named QUEST: Quality of Information, Understanding and Reasoning, Expression Style and Persona, Safety and Harm, and Trust and Confidence. This framework aims to improve the reliability, generalizability, and applicability of human evaluation of generative LLMs in different healthcare applications by defining clear evaluation dimensions and offering detailed guidelines.
Enhancing Large Language Models for Clinical Decision Support by Incorporating Clinical Practice Guidelines
Jan 23, 2024



Background Large Language Models (LLMs), enhanced with Clinical Practice Guidelines (CPGs), can significantly improve Clinical Decision Support (CDS). However, methods for incorporating CPGs into LLMs are not well studied. Methods We develop three distinct methods for incorporating CPGs into LLMs: Binary Decision Tree (BDT), Program-Aided Graph Construction (PAGC), and Chain-of-Thought-Few-Shot Prompting (CoT-FSP). To evaluate the effectiveness of the proposed methods, we create a set of synthetic patient descriptions and conduct both automatic and human evaluation of the responses generated by four LLMs: GPT-4, GPT-3.5 Turbo, LLaMA, and PaLM 2. Zero-Shot Prompting (ZSP) was used as the baseline method. We focus on CDS for COVID-19 outpatient treatment as the case study. Results All four LLMs exhibit improved performance when enhanced with CPGs compared to the baseline ZSP. BDT outperformed both CoT-FSP and PAGC in automatic evaluation. All of the proposed methods demonstrated high performance in human evaluation. Conclusion LLMs enhanced with CPGs demonstrate superior performance, as compared to plain LLMs with ZSP, in providing accurate recommendations for COVID-19 outpatient treatment, which also highlights the potential for broader applications beyond the case study.
MedSyn: Text-guided Anatomy-aware Synthesis of High-Fidelity 3D CT Images
Oct 18, 2023

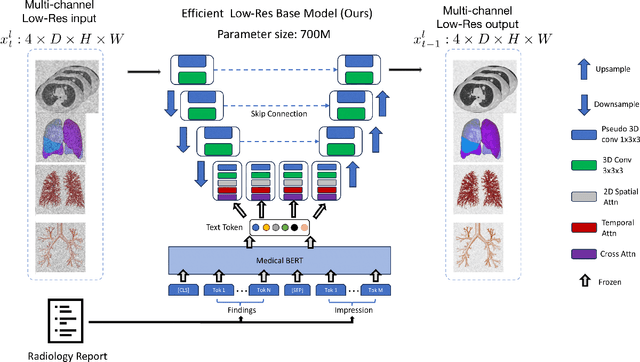

This paper introduces an innovative methodology for producing high-quality 3D lung CT images guided by textual information. While diffusion-based generative models are increasingly used in medical imaging, current state-of-the-art approaches are limited to low-resolution outputs and underutilize radiology reports' abundant information. The radiology reports can enhance the generation process by providing additional guidance and offering fine-grained control over the synthesis of images. Nevertheless, expanding text-guided generation to high-resolution 3D images poses significant memory and anatomical detail-preserving challenges. Addressing the memory issue, we introduce a hierarchical scheme that uses a modified UNet architecture. We start by synthesizing low-resolution images conditioned on the text, serving as a foundation for subsequent generators for complete volumetric data. To ensure the anatomical plausibility of the generated samples, we provide further guidance by generating vascular, airway, and lobular segmentation masks in conjunction with the CT images. The model demonstrates the capability to use textual input and segmentation tasks to generate synthesized images. The results of comparative assessments indicate that our approach exhibits superior performance compared to the most advanced models based on GAN and diffusion techniques, especially in accurately retaining crucial anatomical features such as fissure lines, airways, and vascular structures. This innovation introduces novel possibilities. This study focuses on two main objectives: (1) the development of a method for creating images based on textual prompts and anatomical components, and (2) the capability to generate new images conditioning on anatomical elements. The advancements in image generation can be applied to enhance numerous downstream tasks.
An Empirical Evaluation of Prompting Strategies for Large Language Models in Zero-Shot Clinical Natural Language Processing
Sep 14, 2023Large language models (LLMs) have shown remarkable capabilities in Natural Language Processing (NLP), especially in domains where labeled data is scarce or expensive, such as clinical domain. However, to unlock the clinical knowledge hidden in these LLMs, we need to design effective prompts that can guide them to perform specific clinical NLP tasks without any task-specific training data. This is known as in-context learning, which is an art and science that requires understanding the strengths and weaknesses of different LLMs and prompt engineering approaches. In this paper, we present a comprehensive and systematic experimental study on prompt engineering for five clinical NLP tasks: Clinical Sense Disambiguation, Biomedical Evidence Extraction, Coreference Resolution, Medication Status Extraction, and Medication Attribute Extraction. We assessed the prompts proposed in recent literature, including simple prefix, simple cloze, chain of thought, and anticipatory prompts, and introduced two new types of prompts, namely heuristic prompting and ensemble prompting. We evaluated the performance of these prompts on three state-of-the-art LLMs: GPT-3.5, BARD, and LLAMA2. We also contrasted zero-shot prompting with few-shot prompting, and provide novel insights and guidelines for prompt engineering for LLMs in clinical NLP. To the best of our knowledge, this is one of the first works on the empirical evaluation of different prompt engineering approaches for clinical NLP in this era of generative AI, and we hope that it will inspire and inform future research in this area.
Extracting Physical Rehabilitation Exercise Information from Clinical Notes: a Comparison of Rule-Based and Machine Learning Natural Language Processing Techniques
Mar 22, 2023Physical rehabilitation plays a crucial role in the recovery process of post-stroke patients. By personalizing therapies for patients leveraging predictive modeling and electronic health records (EHRs), healthcare providers can make the rehabilitation process more efficient. Before predictive modeling can provide decision support for the assignment of treatment plans, automated methods are necessary to extract physical rehabilitation exercise information from unstructured EHRs. We introduce a rule-based natural language processing algorithm to annotate therapeutic procedures for stroke patients and compare it to several small machine learning models. We find that our algorithm outperforms these models in extracting half of the concepts where sufficient data is available, and individual exercise descriptions can be assigned binary labels with an f-score of no less than 0.75 per concept. More research needs to be done before these algorithms can be deployed on unlabeled documents, but current progress gives promise to the potential of precision rehabilitation research.
Semi-Supervised Hierarchical Drug Embedding in Hyperbolic Space
Jun 01, 2020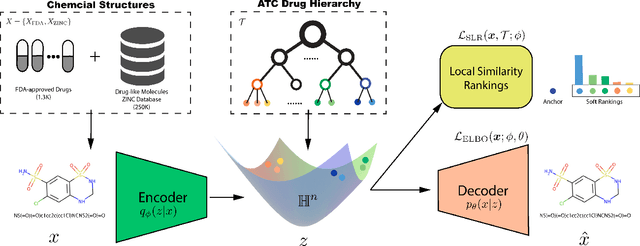
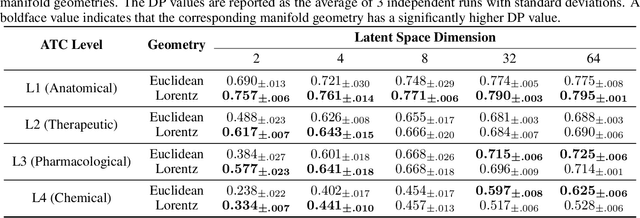


Learning accurate drug representation is essential for tasks such as computational drug repositioning and prediction of drug side-effects. A drug hierarchy is a valuable source that encodes human knowledge of drug relations in a tree-like structure where drugs that act on the same organs, treat the same disease, or bind to the same biological target are grouped together. However, its utility in learning drug representations has not yet been explored, and currently described drug representations cannot place novel molecules in a drug hierarchy. Here, we develop a semi-supervised drug embedding that incorporates two sources of information: (1) underlying chemical grammar that is inferred from molecular structures of drugs and drug-like molecules (unsupervised), and (2) hierarchical relations that are encoded in an expert-crafted hierarchy of approved drugs (supervised). We use the Variational Auto-Encoder (VAE) framework to encode the chemical structures of molecules and use the knowledge-based drug-drug similarity to induce the clustering of drugs in hyperbolic space. The hyperbolic space is amenable for encoding hierarchical concepts. Both quantitative and qualitative results support that the learned drug embedding can accurately reproduce the chemical structure and induce the hierarchical relations among drugs. Furthermore, our approach can infer the pharmacological properties of novel molecules by retrieving similar drugs from the embedding space. We demonstrate that the learned drug embedding can be used to find new uses for existing drugs and to discover side-effects. We show that it significantly outperforms baselines in both tasks.