 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision Rehabilitation for Patients Post-Stroke based on Electronic Health Records and Machine Learning
May 09, 2024



In this study, we utilized statistical analysis and machine learning methods to examine whether rehabilitation exercises can improve patients post-stroke functional abilities, as well as forecast the improvement in functional abilities. Our dataset is patients' rehabilitation exercises and demographic information recorded in the unstructured electronic health records (EHRs) data and free-text rehabilitation procedure notes. We collected data for 265 stroke patients from the University of Pittsburgh Medical Center. We employed a pre-existing natural language processing (NLP) algorithm to extract data on rehabilitation exercises and developed a rule-based NLP algorithm to extract Activity Measure for Post-Acute Care (AM-PAC) scores, covering basic mobility (BM) and applied cognitive (AC) domains, from procedure notes. Changes in AM-PAC scores were classified based on the minimal clinically important difference (MCID), and significance was assessed using Friedman and Wilcoxon tests. To identify impactful exercises, we used Chi-square tests, Fisher's exact tests, and logistic regression for odds ratios. Additionally, we developed five machine learning models-logistic regression (LR), Adaboost (ADB), support vector machine (SVM), gradient boosting (GB), and random forest (RF)-to predict outcomes in functional ability. Statistical analyses revealed significant associations between functional improvements and specific exercises. The RF model achieved the best performance in predicting functional outcomes. In this study, we identified three rehabilitation exercises that significantly contributed to patient post-stroke functional ability improvement in the first two months. Additionally, the successful application of a machine learning model to predict patient-specific functional outcomes underscores the potential for precision rehabilitation.
ReDWINE: A Clinical Datamart with Text Analytical Capabilities to Facilitate Rehabilitation Research
Apr 12, 2023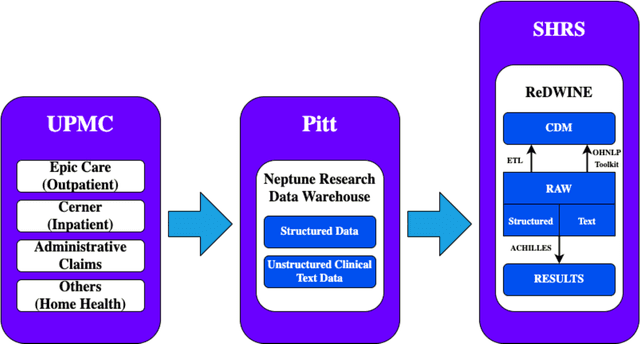
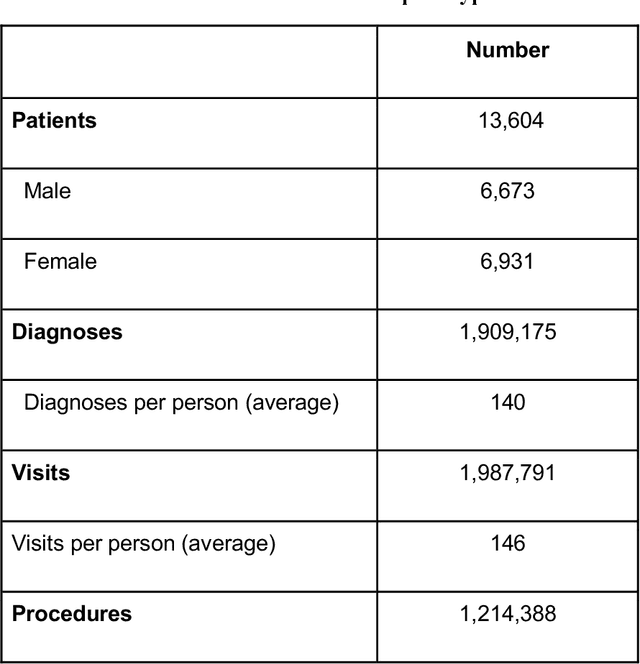
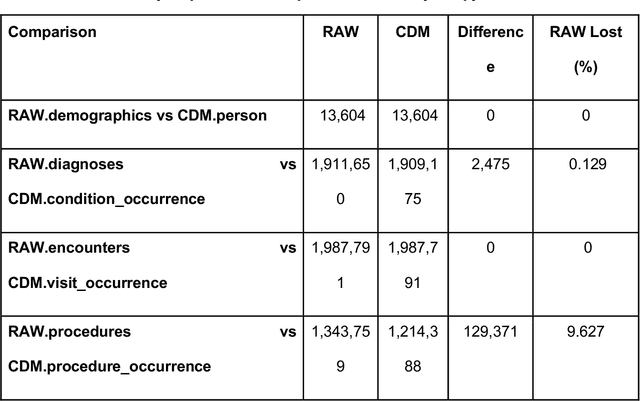
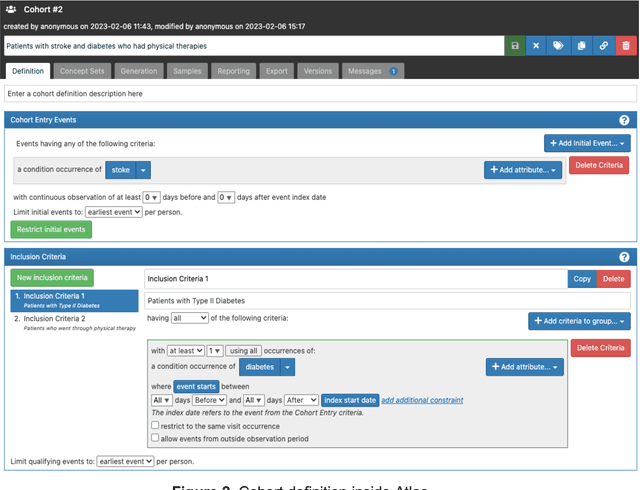
Rehabilitation research focuses on determining the components of a treatment intervention, the mechanism of how these components lead to recovery and rehabilitation, and ultimately the optimal intervention strategies to maximize patients' physical, psychologic, and social functioning. Traditional randomized clinical trials that study and establish new interventions face several challenges, such as high cost and time commitment. Observational studies that use existing clinical data to observe the effect of an intervention have shown several advantages over RCTs. Electronic Health Records (EHRs) have become an increasingly important resource for conducting observational studies. To support these studies, we developed a clinical research datamart, called ReDWINE (Rehabilitation Datamart With Informatics iNfrastructure for rEsearch), that transforms the rehabilitation-related EHR data collected from the UPMC health care system to the Observational Health Data Sciences and Informatics (OHDSI) Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) to facilitate rehabilitation research. The standardized EHR data stored in ReDWINE will further reduce the time and effort required by investigators to pool, harmonize, clean, and analyze data from multiple sources, leading to more robust and comprehensive research findings. ReDWINE also includes deployment of data visualization and data analytics tools to facilitate cohort definition and clinical data analysis. These include among others the Open Health Natural Language Processing (OHNLP) toolkit, a high-throughput NLP pipeline, to provide text analytical capabilities at scale in ReDWINE. Using this comprehensive representation of patient data in ReDWINE for rehabilitation research will facilitate real-world evidence for health interventions and outcomes.
Extracting Physical Rehabilitation Exercise Information from Clinical Notes: a Comparison of Rule-Based and Machine Learning Natural Language Processing Techniques
Mar 22, 2023Physical rehabilitation plays a crucial role in the recovery process of post-stroke patients. By personalizing therapies for patients leveraging predictive modeling and electronic health records (EHRs), healthcare providers can make the rehabilitation process more efficient. Before predictive modeling can provide decision support for the assignment of treatment plans, automated methods are necessary to extract physical rehabilitation exercise information from unstructured EHRs. We introduce a rule-based natural language processing algorithm to annotate therapeutic procedures for stroke patients and compare it to several small machine learning models. We find that our algorithm outperforms these models in extracting half of the concepts where sufficient data is available, and individual exercise descriptions can be assigned binary labels with an f-score of no less than 0.75 per concept. More research needs to be done before these algorithms can be deployed on unlabeled documents, but current progress gives promise to the potential of precision rehabilitation research.