 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of a Reliable and Accessible Caregiving Language Model (CaLM)
Mar 11, 2024



Unlike professional caregivers, family caregivers often assume this role without formal preparation or training. Because of this, there is an urgent need to enhance the capacity of family caregivers to provide quality care. Large language models can potentially be used as a foundation technology for supporting caregivers as educational tools or as adjunct to care. This study aimed to develop a reliable Caregiving Language Model (CaLM) by using FMs and a caregiving knowledge base, develop an accessible CaLM using a small FM that requires fewer computing resources, and evaluate the performance of the model compared to a large FM. We developed CaLM using the Retrieval Augmented Generation (RAG) framework combined with FM fine-tuning for improving the quality of FM answers by grounding the model on a caregiving knowledge base. We used two small FMs as candidates for the FM of CaLM (LLaMA-2 and Falcon with 7B parameters) and larger FM GPT-3.5 as a benchmark. We developed the caregiving knowledge base by gathering various types of documents from the Internet. In this study, we focused on caregivers of individuals with Alzheimer's Disease Related Dementias. We evaluated the models' performance using the benchmark metrics commonly used in evaluating language models and their reliability to provide accurate references with the answers. The RAG framework improved the performance of all FMs used in this study across all measures. As expected, the large FM performed better than small FMs across all metrics. The most interesting result is that small fine-tuned FMs with RAG performed significantly better than GPT 3.5 across all metrics. The fine-tuned LLaMA-2 small FM performed better than GPT 3.5 (even with RAG) in returning references with the answers. The study shows that reliable and accessible CaLM can be developed by using small FMs with a knowledge base specific to the caregiving domain.
ReDWINE: A Clinical Datamart with Text Analytical Capabilities to Facilitate Rehabilitation Research
Apr 12, 2023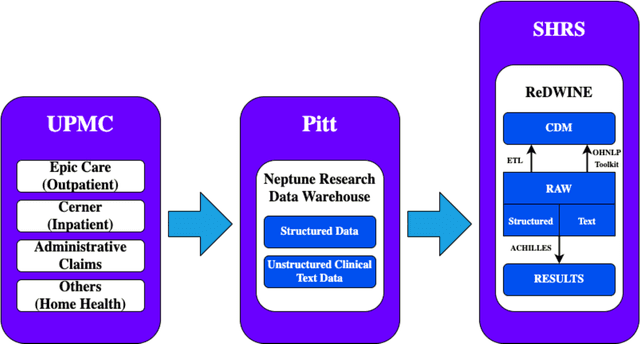
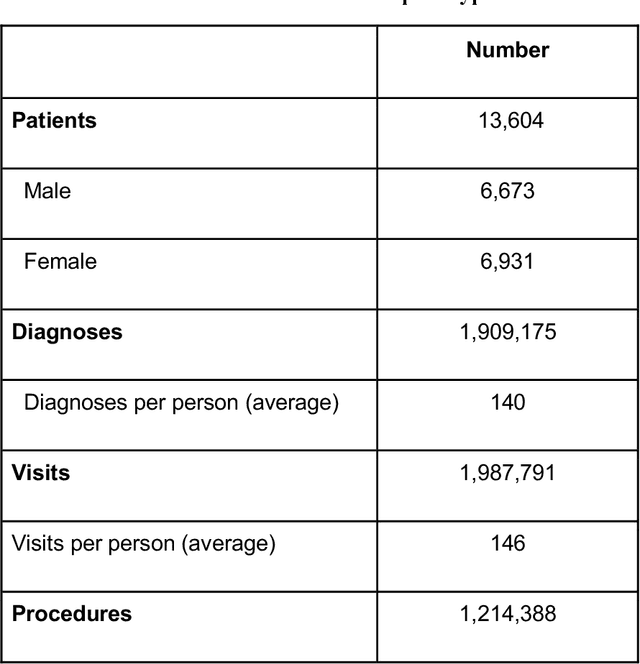
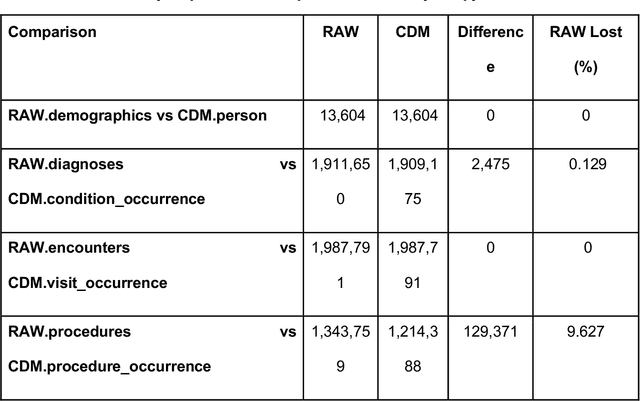
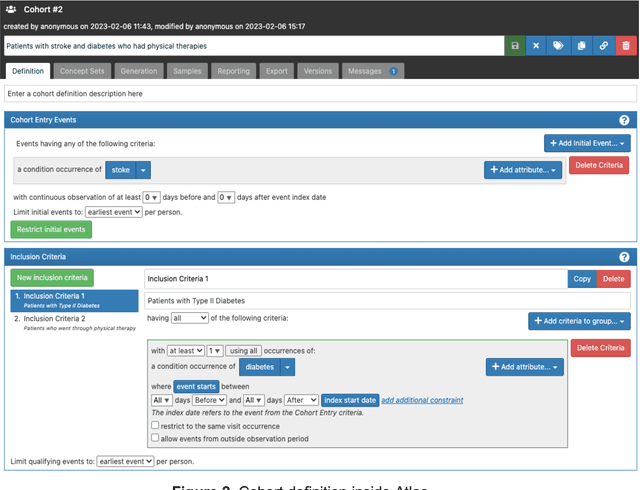
Rehabilitation research focuses on determining the components of a treatment intervention, the mechanism of how these components lead to recovery and rehabilitation, and ultimately the optimal intervention strategies to maximize patients' physical, psychologic, and social functioning. Traditional randomized clinical trials that study and establish new interventions face several challenges, such as high cost and time commitment. Observational studies that use existing clinical data to observe the effect of an intervention have shown several advantages over RCTs. Electronic Health Records (EHRs) have become an increasingly important resource for conducting observational studies. To support these studies, we developed a clinical research datamart, called ReDWINE (Rehabilitation Datamart With Informatics iNfrastructure for rEsearch), that transforms the rehabilitation-related EHR data collected from the UPMC health care system to the Observational Health Data Sciences and Informatics (OHDSI) Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) to facilitate rehabilitation research. The standardized EHR data stored in ReDWINE will further reduce the time and effort required by investigators to pool, harmonize, clean, and analyze data from multiple sources, leading to more robust and comprehensive research findings. ReDWINE also includes deployment of data visualization and data analytics tools to facilitate cohort definition and clinical data analysis. These include among others the Open Health Natural Language Processing (OHNLP) toolkit, a high-throughput NLP pipeline, to provide text analytical capabilities at scale in ReDWINE. Using this comprehensive representation of patient data in ReDWINE for rehabilitation research will facilitate real-world evidence for health interventions and outcomes.