 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of a Reliable and Accessible Caregiving Language Model (CaLM)
Mar 11, 2024Unlike professional caregivers, family caregivers often assume this role without formal preparation or training. Because of this, there is an urgent need to enhance the capacity of family caregivers to provide quality care. Large language models can potentially be used as a foundation technology for supporting caregivers as educational tools or as adjunct to care. This study aimed to develop a reliable Caregiving Language Model (CaLM) by using FMs and a caregiving knowledge base, develop an accessible CaLM using a small FM that requires fewer computing resources, and evaluate the performance of the model compared to a large FM. We developed CaLM using the Retrieval Augmented Generation (RAG) framework combined with FM fine-tuning for improving the quality of FM answers by grounding the model on a caregiving knowledge base. We used two small FMs as candidates for the FM of CaLM (LLaMA-2 and Falcon with 7B parameters) and larger FM GPT-3.5 as a benchmark. We developed the caregiving knowledge base by gathering various types of documents from the Internet. In this study, we focused on caregivers of individuals with Alzheimer's Disease Related Dementias. We evaluated the models' performance using the benchmark metrics commonly used in evaluating language models and their reliability to provide accurate references with the answers. The RAG framework improved the performance of all FMs used in this study across all measures. As expected, the large FM performed better than small FMs across all metrics. The most interesting result is that small fine-tuned FMs with RAG performed significantly better than GPT 3.5 across all metrics. The fine-tuned LLaMA-2 small FM performed better than GPT 3.5 (even with RAG) in returning references with the answers. The study shows that reliable and accessible CaLM can be developed by using small FMs with a knowledge base specific to the caregiving domain.
A Visual Analytics System for Multi-model Comparison on Clinical Data Predictions
Mar 23, 2020

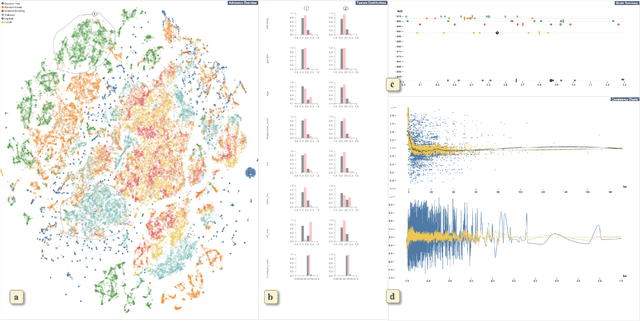

There is a growing trend of applying machine learning methods to medical datasets in order to predict patients' future status. Although some of these methods achieve high performance, challenges still exist in comparing and evaluating different models through their interpretable information. Such analytics can help clinicians improve evidence-based medical decision making. In this work, we develop a visual analytics system that compares multiple models' prediction criteria and evaluates their consistency. With our system, users can generate knowledge on different models' inner criteria and how confidently we can rely on each model's prediction for a certain patient. Through a case study of a publicly available clinical dataset, we demonstrate the effectiveness of our visual analytics system to assist clinicians and researchers in comparing and quantitatively evaluating different machine learning methods.