 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaEval: Evaluating Agents in Production
Apr 14, 2026The rapid deployment of AI agents in commercial settings has outpaced the development of evaluation methodologies that reflect production realities. Existing benchmarks measure agent capabilities through retrospectively curated tasks with well-specified requirements and deterministic metrics -- conditions that diverge fundamentally from production environments where requirements contain implicit constraints, inputs are heterogeneous multi-modal documents with information fragmented across sources, tasks demand undeclared domain expertise, outputs are long-horizon professional deliverables, and success is judged by domain experts whose standards evolve over time. We present AlphaEval, a production-grounded benchmark of 94 tasks sourced from seven companies deploying AI agents in their core business, spanning six O*NET (Occupational Information Network) domains. Unlike model-centric benchmarks, AlphaEval evaluates complete agent products -- Claude Code, Codex, etc. -- as commercial systems, capturing performance variations invisible to model-level evaluation. Our evaluation framework covers multiple paradigms (LLM-as-a-Judge, reference-driven metrics, formal verification, rubric-based assessment, automated UI testing, etc.), with individual domains composing multiple paradigms. Beyond the benchmark itself, we contribute a requirement-to-benchmark construction framework -- a systematic methodology that transforms authentic production requirements into executable evaluation tasks in minimal time. This framework standardizes the entire pipeline from requirement to evaluation, providing a reproducible, modular process that any organization can adopt to construct production-grounded benchmarks for their own domains.
ICHOR: A Robust Representation Learning Approach for ASL CBF Maps with Self-Supervised Masked Autoencoders
Mar 05, 2026Arterial spin labeling (ASL) perfusion MRI allows direct quantification of regional cerebral blood flow (CBF) without exogenous contrast, enabling noninvasive measurements that can be repeated without constraints imposed by contrast injection. ASL is increasingly acquired in research studies and clinical MRI protocols. Building on successes in structural imaging, recent efforts have implemented deep learning based methods to improve image quality, enable automated quality control, and derive robust quantitative and predictive biomarkers with ASL derived CBF. However, progress has been limited by variable image quality, substantial inter-site, vendor and protocol differences, and limited availability of labeled datasets needed to train models that generalize across cohorts. To address these challenges, we introduce ICHOR, a self supervised pre-training approach for ASL CBF maps that learns transferable representations using 3D masked autoencoders. ICHOR is pretrained via masked image modeling using a Vision Transformer backbone and can be used as a general-purpose encoder for downstream ASL tasks. For pre-training, we curated one of the largest ASL datasets to date, comprising 11,405 ASL CBF scans from 14 studies spanning multiple sites and acquisition protocols. We evaluated the pre-trained ICHOR encoder on three downstream diagnostic classification tasks and one ASL CBF map quality prediction regression task. Across all evaluations, ICHOR outperformed existing neuroimaging self-supervised pre-training methods adapted to ASL. Pre-trained weights and code will be made publicly available.
Information Bottleneck-based Causal Attention for Multi-label Medical Image Recognition
Aug 11, 2025Multi-label classification (MLC) of medical images aims to identify multiple diseases and holds significant clinical potential. A critical step is to learn class-specific features for accurate diagnosis and improved interpretability effectively. However, current works focus primarily on causal attention to learn class-specific features, yet they struggle to interpret the true cause due to the inadvertent attention to class-irrelevant features. To address this challenge, we propose a new structural causal model (SCM) that treats class-specific attention as a mixture of causal, spurious, and noisy factors, and a novel Information Bottleneck-based Causal Attention (IBCA) that is capable of learning the discriminative class-specific attention for MLC of medical images. Specifically, we propose learning Gaussian mixture multi-label spatial attention to filter out class-irrelevant information and capture each class-specific attention pattern. Then a contrastive enhancement-based causal intervention is proposed to gradually mitigate the spurious attention and reduce noise information by aligning multi-head attention with the Gaussian mixture multi-label spatial. Quantitative and ablation results on Endo and MuReD show that IBCA outperforms all methods. Compared to the second-best results for each metric, IBCA achieves improvements of 6.35\% in CR, 7.72\% in OR, and 5.02\% in mAP for MuReD, 1.47\% in CR, and 1.65\% in CF1, and 1.42\% in mAP for Endo.
RingFormer: A Ring-Enhanced Graph Transformer for Organic Solar Cell Property Prediction
Dec 12, 2024



Organic Solar Cells (OSCs) are a promising technology for sustainable energy production. However, the identification of molecules with desired OSC properties typically involves laborious experimental research. To accelerate progress in the field, it is crucial to develop machine learning models capable of accurately predicting the properties of OSC molecules. While graph representation learning has demonstrated success in molecular property prediction, it remains underexplored for OSC-specific tasks. Existing methods fail to capture the unique structural features of OSC molecules, particularly the intricate ring systems that critically influence OSC properties, leading to suboptimal performance. To fill the gap, we present RingFormer, a novel graph transformer framework specially designed to capture both atom and ring level structural patterns in OSC molecules. RingFormer constructs a hierarchical graph that integrates atomic and ring structures and employs a combination of local message passing and global attention mechanisms to generate expressive graph representations for accurate OSC property prediction. We evaluate RingFormer's effectiveness on five curated OSC molecule datasets through extensive experiments. The results demonstrate that RingFormer consistently outperforms existing methods, achieving a 22.77% relative improvement over the nearest competitor on the CEPDB dataset.
Memoryless Multimodal Anomaly Detection via Student-Teacher Network and Signed Distance Learning
Sep 09, 2024Unsupervised anomaly detection is a challenging computer vision task, in which 2D-based anomaly detection methods have been extensively studied. However, multimodal anomaly detection based on RGB images and 3D point clouds requires further investigation. The existing methods are mainly inspired by memory bank based methods commonly used in 2D-based anomaly detection, which may cost extra memory for storing mutimodal features. In present study, a novel memoryless method MDSS is proposed for multimodal anomaly detection, which employs a light-weighted student-teacher network and a signed distance function to learn from RGB images and 3D point clouds respectively, and complements the anomaly information from the two modalities. Specifically, a student-teacher network is trained with normal RGB images and masks generated from point clouds by a dynamic loss, and the anomaly score map could be obtained from the discrepancy between the output of student and teacher. Furthermore, the signed distance function learns from normal point clouds to predict the signed distances between points and surface, and the obtained signed distances are used to generate anomaly score map. Subsequently, the anomaly score maps are aligned to generate the final anomaly score map for detection. The experimental results indicate that MDSS is comparable but more stable than the SOTA memory bank based method Shape-guided, and furthermore performs better than other baseline methods.
A Versatile Framework for Attributed Network Clustering via K-Nearest Neighbor Augmentation
Aug 10, 2024Attributed networks containing entity-specific information in node attributes are ubiquitous in modeling social networks, e-commerce, bioinformatics, etc. Their inherent network topology ranges from simple graphs to hypergraphs with high-order interactions and multiplex graphs with separate layers. An important graph mining task is node clustering, aiming to partition the nodes of an attributed network into k disjoint clusters such that intra-cluster nodes are closely connected and share similar attributes, while inter-cluster nodes are far apart and dissimilar. It is highly challenging to capture multi-hop connections via nodes or attributes for effective clustering on multiple types of attributed networks. In this paper, we first present AHCKA as an efficient approach to attributed hypergraph clustering (AHC). AHCKA includes a carefully-crafted K-nearest neighbor augmentation strategy for the optimized exploitation of attribute information on hypergraphs, a joint hypergraph random walk model to devise an effective AHC objective, and an efficient solver with speedup techniques for the objective optimization. The proposed techniques are extensible to various types of attributed networks, and thus, we develop ANCKA as a versatile attributed network clustering framework, capable of attributed graph clustering (AGC), attributed multiplex graph clustering (AMGC), and AHC. Moreover, we devise ANCKA with algorithmic designs tailored for GPU acceleration to boost efficiency. We have conducted extensive experiments to compare our methods with 19 competitors on 8 attributed hypergraphs, 16 competitors on 6 attributed graphs, and 16 competitors on 3 attributed multiplex graphs, all demonstrating the superb clustering quality and efficiency of our methods.
GNNAnatomy: Systematic Generation and Evaluation of Multi-Level Explanations for Graph Neural Networks
Jun 06, 2024



Graph Neural Networks (GNNs) have proven highly effective in various machine learning (ML) tasks involving graphs, such as node/graph classification and link prediction. However, explaining the decisions made by GNNs poses challenges because of the aggregated relational information based on graph structure, leading to complex data transformations. Existing methods for explaining GNNs often face limitations in systematically exploring diverse substructures and evaluating results in the absence of ground truths. To address this gap, we introduce GNNAnatomy, a model- and dataset-agnostic visual analytics system designed to facilitate the generation and evaluation of multi-level explanations for GNNs. In GNNAnatomy, we employ graphlets to elucidate GNN behavior in graph-level classification tasks. By analyzing the associations between GNN classifications and graphlet frequencies, we formulate hypothesized factual and counterfactual explanations. To validate a hypothesized graphlet explanation, we introduce two metrics: (1) the correlation between its frequency and the classification confidence, and (2) the change in classification confidence after removing this substructure from the original graph. To demonstrate the effectiveness of GNNAnatomy, we conduct case studies on both real-world and synthetic graph datasets from various domains. Additionally, we qualitatively compare GNNAnatomy with a state-of-the-art GNN explainer, demonstrating the utility and versatility of our design.
A Visual Analytics Design for Connecting Healthcare Team Communication to Patient Outcomes
Jan 08, 2024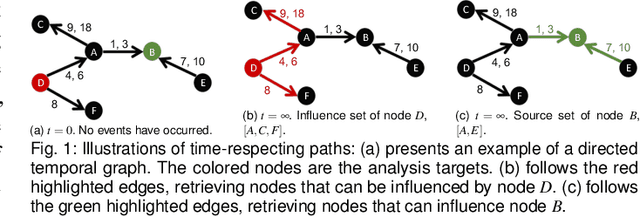
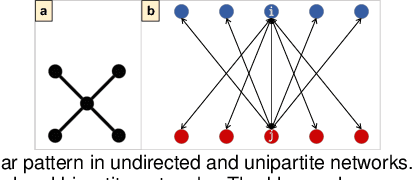
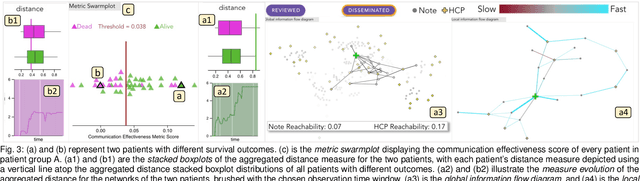
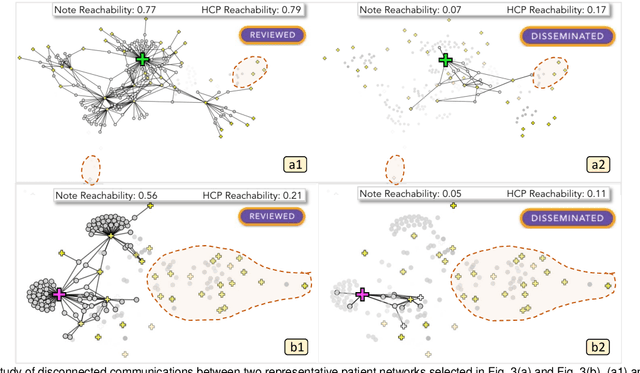
Communication among healthcare professionals (HCPs) is crucial for the quality of patient treatment. Surrounding each patient's treatment, communication among HCPs can be examined as temporal networks, constructed from Electronic Health Record (EHR) access logs. This paper introduces a visual analytics system designed to study the effectiveness and efficiency of temporal communication networks mediated by the EHR system. We present a method that associates network measures with patient survival outcomes and devises effectiveness metrics based on these associations. To analyze communication efficiency, we extract the latencies and frequencies of EHR accesses. Our visual analytics system is designed to assist in inspecting and understanding the composed communication effectiveness metrics and to enable the exploration of communication efficiency by encoding latencies and frequencies in an information flow diagram. We demonstrate and evaluate our system through multiple case studies and an expert review.
Visual Analytics for Efficient Image Exploration and User-Guided Image Captioning
Nov 02, 2023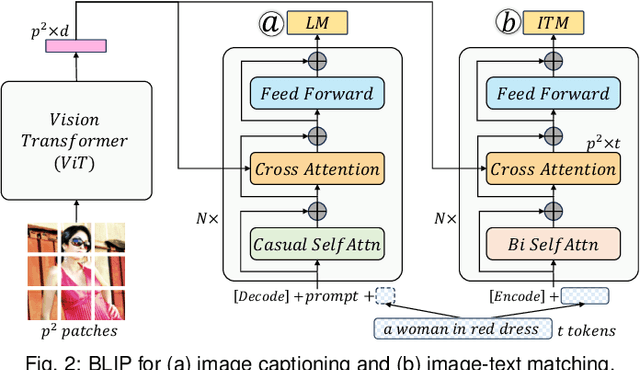



Recent advancements in pre-trained large-scale language-image models have ushered in a new era of visual comprehension, offering a significant leap forward. These breakthroughs have proven particularly instrumental in addressing long-standing challenges that were previously daunting. Leveraging these innovative techniques, this paper tackles two well-known issues within the realm of visual analytics: (1) the efficient exploration of large-scale image datasets and identification of potential data biases within them; (2) the evaluation of image captions and steering of their generation process. On the one hand, by visually examining the captions automatically generated from language-image models for an image dataset, we gain deeper insights into the semantic underpinnings of the visual contents, unearthing data biases that may be entrenched within the dataset. On the other hand, by depicting the association between visual contents and textual captions, we expose the weaknesses of pre-trained language-image models in their captioning capability and propose an interactive interface to steer caption generation. The two parts have been coalesced into a coordinated visual analytics system, fostering mutual enrichment of visual and textual elements. We validate the effectiveness of the system with domain practitioners through concrete case studies with large-scale image datasets.
NeuralMatrix: Moving Entire Neural Networks to General Matrix Multiplication for Efficient Inference
May 23, 2023In this study, we introduce NeuralMatrix, a novel framework that enables the computation of versatile deep neural networks (DNNs) on a single general matrix multiplication (GEMM) accelerator. The proposed approach overcomes the specificity limitations of ASIC-based accelerators while achieving application-specific acceleration levels compared to general-purpose processors such as CPUs and GPUs. We address the challenges of mapping both linear and nonlinear operations in DNN computation to general matrix multiplications and the impact of using a GEMM accelerator on DNN inference accuracy. Extensive experiments are conducted on various DNN models from three popular categories (i.e., CNN, Transformers, and GNN) as illustrative backbone models. Our results demonstrate that DNNs suffer only up to a 2.02% accuracy loss after being converted to general matrix multiplication, while achieving 113x to 19.44x improvements in throughput per power compared to CPUs and GPUs.