 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Graph Refinement and Label Propagation with LLMs for Cost-Effective Entity Resolution
May 25, 2026Dirty entity resolution (ER), which identifies records referring to the same real-world entity from a single, messy dataset, is a fundamental task in data management and mining. However, the dominant blocking-matching-clustering paradigm for ER suffers from critical flaws. Its cascaded, decoupled workflow essentially produces a static, sparse graph plagued by missing edges (due to blocking failures) and noisy links (due to matching errors), causing error propagation and yielding suboptimal clusters, particularly when rigid transitivity is imposed in the clustering. We contend that matching and clustering are fundamentally synergistic, both optimizing for the construction of an ideal entity graph. Building upon this insight, we propose Alper, a unified framework that integrates these steps into an iterative probabilistic label propagation process over a global, evolving graph. Unlike disjoint blocking, Alper refines the graph structure and labels dynamically by adaptively integrating "weak but cheap" signals from graph propagation with "strong but expensive" LLM-based pairwise queries. For higher cost-effectiveness, we formulate the signal selection as a constrained optimization problem maximizing cumulative marginal gain under a query budget, solved via our greedy algorithm with provable theoretical guarantees. Our extensive experiments over eight benchmark datasets demonstrate that Alper is consistently superior to state-of-the-art cascaded pipelines.
Balanced Co-Clustering of Users and Items for Embedding Table Compression in Recommender Systems
Apr 20, 2026Recommender systems have advanced markedly over the past decade by transforming each user/item into a dense embedding vector with deep learning models. At industrial scale, embedding tables constituted by such vectors of all users/items demand a vast amount of parameters and impose heavy compute and memory overhead during training and inference, hindering model deployment under resource constraints. Existing solutions towards embedding compression either suffer from severely compromised recommendation accuracy or incur considerable computational costs. To mitigate these issues, this paper presents BACO, a fast and effective framework for compressing embedding tables. Unlike traditional ID hashing, BACO is built on the idea of exploiting collaborative signals in user-item interactions for user and item groupings, such that similar users/items share the same embeddings in the codebook. Specifically, we formulate a balanced co-clustering objective that maximizes intra-cluster connectivity while enforcing cluster-volume balance, and unify canonical graph clustering techniques into the framework through rigorous theoretical analyses. To produce effective groupings while averting codebook collapse, BACO instantiates this framework with a principled weighting scheme for users and items, an efficient label propagation solver, as well as secondary user clusters. Our extensive experiments comparing BACO against full models and 18 baselines over benchmark datasets demonstrate that BACO cuts embedding parameters by over 75% with a drop of at most 1.85% in recall, while surpassing the strongest baselines by being up to 346X faster.
NILC: Discovering New Intents with LLM-assisted Clustering
Nov 08, 2025New intent discovery (NID) seeks to recognize both new and known intents from unlabeled user utterances, which finds prevalent use in practical dialogue systems. Existing works towards NID mainly adopt a cascaded architecture, wherein the first stage focuses on encoding the utterances into informative text embeddings beforehand, while the latter is to group similar embeddings into clusters (i.e., intents), typically by K-Means. However, such a cascaded pipeline fails to leverage the feedback from both steps for mutual refinement, and, meanwhile, the embedding-only clustering overlooks nuanced textual semantics, leading to suboptimal performance. To bridge this gap, this paper proposes NILC, a novel clustering framework specially catered for effective NID. Particularly, NILC follows an iterative workflow, in which clustering assignments are judiciously updated by carefully refining cluster centroids and text embeddings of uncertain utterances with the aid of large language models (LLMs). Specifically, NILC first taps into LLMs to create additional semantic centroids for clusters, thereby enriching the contextual semantics of the Euclidean centroids of embeddings. Moreover, LLMs are then harnessed to augment hard samples (ambiguous or terse utterances) identified from clusters via rewriting for subsequent cluster correction. Further, we inject supervision signals through non-trivial techniques seeding and soft must links for more accurate NID in the semi-supervised setting. Extensive experiments comparing NILC against multiple recent baselines under both unsupervised and semi-supervised settings showcase that NILC can achieve significant performance improvements over six benchmark datasets of diverse domains consistently.
GegenNet: Spectral Convolutional Neural Networks for Link Sign Prediction in Signed Bipartite Graphs
Aug 27, 2025Given a signed bipartite graph (SBG) G with two disjoint node sets U and V, the goal of link sign prediction is to predict the signs of potential links connecting U and V based on known positive and negative edges in G. The majority of existing solutions towards link sign prediction mainly focus on unipartite signed graphs, which are sub-optimal due to the neglect of node heterogeneity and unique bipartite characteristics of SBGs. To this end, recent studies adapt graph neural networks to SBGs by introducing message-passing schemes for both inter-partition (UxV) and intra-partition (UxU or VxV) node pairs. However, the fundamental spectral convolutional operators were originally designed for positive links in unsigned graphs, and thus, are not optimal for inferring missing positive or negative links from known ones in SBGs. Motivated by this, this paper proposes GegenNet, a novel and effective spectral convolutional neural network model for link sign prediction in SBGs. In particular, GegenNet achieves enhanced model capacity and high predictive accuracy through three main technical contributions: (i) fast and theoretically grounded spectral decomposition techniques for node feature initialization; (ii) a new spectral graph filter based on the Gegenbauer polynomial basis; and (iii) multi-layer sign-aware spectral convolutional networks alternating Gegenbauer polynomial filters with positive and negative edges. Our extensive empirical studies reveal that GegenNet can achieve significantly superior performance (up to a gain of 4.28% in AUC and 11.69% in F1) in link sign prediction compared to 11 strong competitors over 6 benchmark SBG datasets.
Effective Clustering for Large Multi-Relational Graphs
Aug 24, 2025Multi-relational graphs (MRGs) are an expressive data structure for modeling diverse interactions/relations among real objects (i.e., nodes), which pervade extensive applications and scenarios. Given an MRG G with N nodes, partitioning the node set therein into K disjoint clusters (MRGC) is a fundamental task in analyzing MRGs, which has garnered considerable attention. However, the majority of existing solutions towards MRGC either yield severely compromised result quality by ineffective fusion of heterogeneous graph structures and attributes, or struggle to cope with sizable MRGs with millions of nodes and billions of edges due to the adoption of sophisticated and costly deep learning models. In this paper, we present DEMM and DEMM+, two effective MRGC approaches to address the limitations above. Specifically, our algorithms are built on novel two-stage optimization objectives, where the former seeks to derive high-caliber node feature vectors by optimizing the multi-relational Dirichlet energy specialized for MRGs, while the latter minimizes the Dirichlet energy of clustering results over the node affinity graph. In particular, DEMM+ achieves significantly higher scalability and efficiency over our based method DEMM through a suite of well-thought-out optimizations. Key technical contributions include (i) a highly efficient approximation solver for constructing node feature vectors, and (ii) a theoretically-grounded problem transformation with carefully-crafted techniques that enable linear-time clustering without explicitly materializing the NxN dense affinity matrix. Further, we extend DEMM+ to handle attribute-less MRGs through non-trivial adaptations. Extensive experiments, comparing DEMM+ against 20 baselines over 11 real MRGs, exhibit that DEMM+ is consistently superior in terms of clustering quality measured against ground-truth labels, while often being remarkably faster.
Community-Aware Social Community Recommendation
Aug 07, 2025Social recommendation, which seeks to leverage social ties among users to alleviate the sparsity issue of user-item interactions, has emerged as a popular technique for elevating personalized services in recommender systems. Despite being effective, existing social recommendation models are mainly devised for recommending regular items such as blogs, images, and products, and largely fail for community recommendations due to overlooking the unique characteristics of communities. Distinctly, communities are constituted by individuals, who present high dynamicity and relate to rich structural patterns in social networks. To our knowledge, limited research has been devoted to comprehensively exploiting this information for recommending communities. To bridge this gap, this paper presents CASO, a novel and effective model specially designed for social community recommendation. Under the hood, CASO harnesses three carefully-crafted encoders for user embedding, wherein two of them extract community-related global and local structures from the social network via social modularity maximization and social closeness aggregation, while the third one captures user preferences using collaborative filtering with observed user-community affiliations. To further eliminate feature redundancy therein, we introduce a mutual exclusion between social and collaborative signals. Finally, CASO includes a community detection loss in the model optimization, thereby producing community-aware embeddings for communities. Our extensive experiments evaluating CASO against nine strong baselines on six real-world social networks demonstrate its consistent and remarkable superiority over the state of the art in terms of community recommendation performance.
Simple yet Effective Graph Distillation via Clustering
May 27, 2025Despite plentiful successes achieved by graph representation learning in various domains, the training of graph neural networks (GNNs) still remains tenaciously challenging due to the tremendous computational overhead needed for sizable graphs in practice. Recently, graph data distillation (GDD), which seeks to distill large graphs into compact and informative ones, has emerged as a promising technique to enable efficient GNN training. However, most existing GDD works rely on heuristics that align model gradients or representation distributions on condensed and original graphs, leading to compromised result quality, expensive training for distilling large graphs, or both. Motivated by this, this paper presents an efficient and effective GDD approach, ClustGDD. Under the hood, ClustGDD resorts to synthesizing the condensed graph and node attributes through fast and theoretically-grounded clustering that minimizes the within-cluster sum of squares and maximizes the homophily on the original graph. The fundamental idea is inspired by our empirical and theoretical findings unveiling the connection between clustering and empirical condensation quality using Fr\'echet Inception Distance, a well-known quality metric for synthetic images. Furthermore, to mitigate the adverse effects caused by the homophily-based clustering, ClustGDD refines the nodal attributes of the condensed graph with a small augmentation learned via class-aware graph sampling and consistency loss. Our extensive experiments exhibit that GNNs trained over condensed graphs output by ClustGDD consistently achieve superior or comparable performance to state-of-the-art GDD methods in terms of node classification on five benchmark datasets, while being orders of magnitude faster.
Cost-Effective Text Clustering with Large Language Models
Apr 22, 2025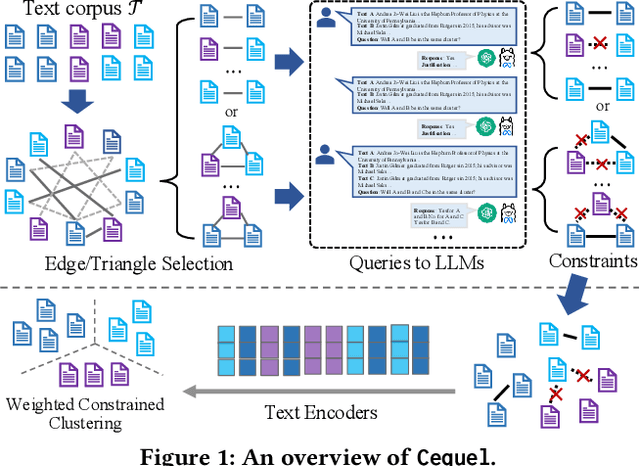

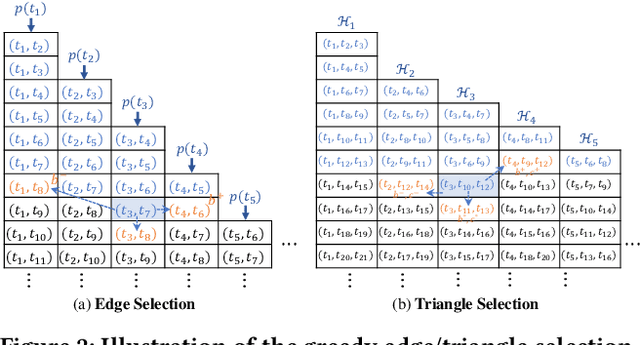
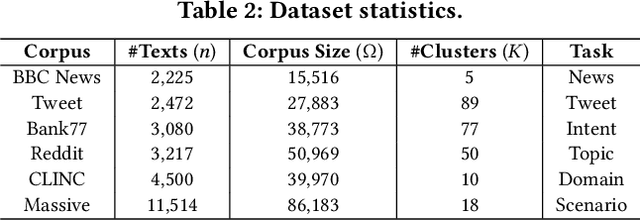
Text clustering aims to automatically partition a collection of text documents into distinct clusters based on linguistic features. In the literature, this task is usually framed as metric clustering based on text embeddings from pre-trained encoders or a graph clustering problem upon pairwise similarities from an oracle, e.g., a large ML model. Recently, large language models (LLMs) bring significant advancement in this field by offering contextualized text embeddings and highly accurate similarity scores, but meanwhile, present grand challenges to cope with substantial computational and/or financial overhead caused by numerous API-based queries or inference calls to the models. In response, this paper proposes TECL, a cost-effective framework that taps into the feedback from LLMs for accurate text clustering within a limited budget of queries to LLMs. Under the hood, TECL adopts our EdgeLLM or TriangleLLM to construct must-link/cannot-link constraints for text pairs, and further leverages such constraints as supervision signals input to our weighted constrained clustering approach to generate clusters. Particularly, EdgeLLM (resp. TriangleLLM) enables the identification of informative text pairs (resp. triplets) for querying LLMs via well-thought-out greedy algorithms and accurate extraction of pairwise constraints through carefully-crafted prompting techniques. Our experiments on multiple benchmark datasets exhibit that TECL consistently and considerably outperforms existing solutions in unsupervised text clustering under the same query cost for LLMs.
SAFT: Structure-aware Transformers for Textual Interaction Classification
Apr 07, 2025Textual interaction networks (TINs) are an omnipresent data structure used to model the interplay between users and items on e-commerce websites, social networks, etc., where each interaction is associated with a text description. Classifying such textual interactions (TIC) finds extensive use in detecting spam reviews in e-commerce, fraudulent transactions in finance, and so on. Existing TIC solutions either (i) fail to capture the rich text semantics due to the use of context-free text embeddings, and/or (ii) disregard the bipartite structure and node heterogeneity of TINs, leading to compromised TIC performance. In this work, we propose SAFT, a new architecture that integrates language- and graph-based modules for the effective fusion of textual and structural semantics in the representation learning of interactions. In particular, line graph attention (LGA)/gated attention units (GAUs) and pretrained language models (PLMs) are capitalized on to model the interaction-level and token-level signals, which are further coupled via the proxy token in an iterative and contextualized fashion. Additionally, an efficient and theoretically-grounded approach is developed to encode the local and global topology information pertaining to interactions into structural embeddings. The resulting embeddings not only inject the structural features underlying TINs into the textual interaction encoding but also facilitate the design of graph sampling strategies. Extensive empirical evaluations on multiple real TIN datasets demonstrate the superiority of SAFT over the state-of-the-art baselines in TIC accuracy.
Adaptive Local Clustering over Attributed Graphs
Mar 26, 2025Given a graph $G$ and a seed node $v_s$, the objective of local graph clustering (LGC) is to identify a subgraph $C_s \in G$ (a.k.a. local cluster) surrounding $v_s$ in time roughly linear with the size of $C_s$. This approach yields personalized clusters without needing to access the entire graph, which makes it highly suitable for numerous applications involving large graphs. However, most existing solutions merely rely on the topological connectivity between nodes in $G$, rendering them vulnerable to missing or noisy links that are commonly present in real-world graphs. To address this issue, this paper resorts to leveraging the complementary nature of graph topology and node attributes to enhance local clustering quality. To effectively exploit the attribute information, we first formulate the LGC as an estimation of the bidirectional diffusion distribution (BDD), which is specialized for capturing the multi-hop affinity between nodes in the presence of attributes. Furthermore, we propose LACA, an efficient and effective approach for LGC that achieves superb empirical performance on multiple real datasets while maintaining strong locality. The core components of LACA include (i) a fast and theoretically-grounded preprocessing technique for node attributes, (ii) an adaptive algorithm for diffusing any vectors over $G$ with rigorous theoretical guarantees and expedited convergence, and (iii) an effective three-step scheme for BDD approximation. Extensive experiments, comparing 17 competitors on 8 real datasets, show that LACA outperforms all competitors in terms of result quality measured against ground truth local clusters, while also being up to orders of magnitude faster. The code is available at https://github.com/HaoranZ99/alac.