 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Graph Refinement and Label Propagation with LLMs for Cost-Effective Entity Resolution
May 25, 2026Dirty entity resolution (ER), which identifies records referring to the same real-world entity from a single, messy dataset, is a fundamental task in data management and mining. However, the dominant blocking-matching-clustering paradigm for ER suffers from critical flaws. Its cascaded, decoupled workflow essentially produces a static, sparse graph plagued by missing edges (due to blocking failures) and noisy links (due to matching errors), causing error propagation and yielding suboptimal clusters, particularly when rigid transitivity is imposed in the clustering. We contend that matching and clustering are fundamentally synergistic, both optimizing for the construction of an ideal entity graph. Building upon this insight, we propose Alper, a unified framework that integrates these steps into an iterative probabilistic label propagation process over a global, evolving graph. Unlike disjoint blocking, Alper refines the graph structure and labels dynamically by adaptively integrating "weak but cheap" signals from graph propagation with "strong but expensive" LLM-based pairwise queries. For higher cost-effectiveness, we formulate the signal selection as a constrained optimization problem maximizing cumulative marginal gain under a query budget, solved via our greedy algorithm with provable theoretical guarantees. Our extensive experiments over eight benchmark datasets demonstrate that Alper is consistently superior to state-of-the-art cascaded pipelines.
Identified-Set Geometry of Distributional Model Extraction under Top-$K$ Censored API Access
May 11, 2026Modern LLM APIs often reveal only top-$K$ logit scores and censor the remaining vocabulary. We study the per-position distribution-recovery limits of this access model. For censoring threshold $τ$, the compatible teacher distributions form an identified set whose total-variation diameter is exactly $U_K=(V-K)\exp(τ)/(Z_A+(V-K)\exp(τ))$, where $Z_A$ is the observed partition function. For KL recovery, we give a computable binary-endpoint lower bound and an asymptotically matching small-ambiguity upper bound, with an extension to reference-aware attackers. Experiments on a Qwen3 math-reasoning teacher reveal a layered extraction hierarchy: on-task top-$K$ distillation recovers 12% of private capability, full-logit distillation recovers 56% despite 99% KL closure, and generation-based extraction recovers 96%. Top-$K$ censoring therefore limits per-position distribution recovery but does not by itself prevent capability extraction, separating fidelity from transfer in prompt-only logit distillation.
Knowledge Poisoning Attacks on Medical Multi-Modal Retrieval-Augmented Generation
May 11, 2026Retrieval-augmented generation (RAG) is a widely adopted paradigm for enhancing LLMs in medical applications by incorporating expert multimodal knowledge during generation. However, the underlying retrieval databases may naturally contain, or be intentionally injected with, adversarial knowledge, which can perturb model outputs and undermine system reliability. To investigate this risk, prior studies have explored knowledge poisoning attacks in medical RAG systems. Nevertheless, most of them rely on the strong assumption that adversaries possess prior knowledge of user queries, which is unrealistic in deployments and substantially limits their practical applicability. In this paper, we propose M\textsuperscript{3}Att, a knowledge-poisoning framework designed for medical multimodal RAG systems, assuming only limited distribution knowledge of the underlying database. Our core idea is to inject covert misinformation into textual data while using paired visual data as a query-agnostic trigger to promote retrieval. We first propose a unified framework that introduces imperceptible perturbations to visual inputs to manipulate retrieval probabilities. Besides, due to the prior medical knowledge in LLMs, naively poisoned medical content with explicit factual errors can be corrected during generation. Thus, we leverage the inherent ambiguity of medical diagnosis and design a covert misinformation injection strategy that degrades diagnostic accuracy while evading model self-correction. Experiments on five LLMs and datasets demonstrate that M\textsuperscript{3}Att consistently produces clinically plausible yet incorrect generations. Codes: https://github.com/ypr17/M3Att.
MrM: Black-Box Membership Inference Attacks against Multimodal RAG Systems
Jun 09, 2025



Multimodal retrieval-augmented generation (RAG) systems enhance large vision-language models by integrating cross-modal knowledge, enabling their increasing adoption across real-world multimodal tasks. These knowledge databases may contain sensitive information that requires privacy protection. However, multimodal RAG systems inherently grant external users indirect access to such data, making them potentially vulnerable to privacy attacks, particularly membership inference attacks (MIAs). % Existing MIA methods targeting RAG systems predominantly focus on the textual modality, while the visual modality remains relatively underexplored. To bridge this gap, we propose MrM, the first black-box MIA framework targeted at multimodal RAG systems. It utilizes a multi-object data perturbation framework constrained by counterfactual attacks, which can concurrently induce the RAG systems to retrieve the target data and generate information that leaks the membership information. Our method first employs an object-aware data perturbation method to constrain the perturbation to key semantics and ensure successful retrieval. Building on this, we design a counterfact-informed mask selection strategy to prioritize the most informative masked regions, aiming to eliminate the interference of model self-knowledge and amplify attack efficacy. Finally, we perform statistical membership inference by modeling query trials to extract features that reflect the reconstruction of masked semantics from response patterns. Experiments on two visual datasets and eight mainstream commercial visual-language models (e.g., GPT-4o, Gemini-2) demonstrate that MrM achieves consistently strong performance across both sample-level and set-level evaluations, and remains robust under adaptive defenses.
SAFT: Structure-aware Transformers for Textual Interaction Classification
Apr 07, 2025Textual interaction networks (TINs) are an omnipresent data structure used to model the interplay between users and items on e-commerce websites, social networks, etc., where each interaction is associated with a text description. Classifying such textual interactions (TIC) finds extensive use in detecting spam reviews in e-commerce, fraudulent transactions in finance, and so on. Existing TIC solutions either (i) fail to capture the rich text semantics due to the use of context-free text embeddings, and/or (ii) disregard the bipartite structure and node heterogeneity of TINs, leading to compromised TIC performance. In this work, we propose SAFT, a new architecture that integrates language- and graph-based modules for the effective fusion of textual and structural semantics in the representation learning of interactions. In particular, line graph attention (LGA)/gated attention units (GAUs) and pretrained language models (PLMs) are capitalized on to model the interaction-level and token-level signals, which are further coupled via the proxy token in an iterative and contextualized fashion. Additionally, an efficient and theoretically-grounded approach is developed to encode the local and global topology information pertaining to interactions into structural embeddings. The resulting embeddings not only inject the structural features underlying TINs into the textual interaction encoding but also facilitate the design of graph sampling strategies. Extensive empirical evaluations on multiple real TIN datasets demonstrate the superiority of SAFT over the state-of-the-art baselines in TIC accuracy.
Adaptive Local Clustering over Attributed Graphs
Mar 26, 2025Given a graph $G$ and a seed node $v_s$, the objective of local graph clustering (LGC) is to identify a subgraph $C_s \in G$ (a.k.a. local cluster) surrounding $v_s$ in time roughly linear with the size of $C_s$. This approach yields personalized clusters without needing to access the entire graph, which makes it highly suitable for numerous applications involving large graphs. However, most existing solutions merely rely on the topological connectivity between nodes in $G$, rendering them vulnerable to missing or noisy links that are commonly present in real-world graphs. To address this issue, this paper resorts to leveraging the complementary nature of graph topology and node attributes to enhance local clustering quality. To effectively exploit the attribute information, we first formulate the LGC as an estimation of the bidirectional diffusion distribution (BDD), which is specialized for capturing the multi-hop affinity between nodes in the presence of attributes. Furthermore, we propose LACA, an efficient and effective approach for LGC that achieves superb empirical performance on multiple real datasets while maintaining strong locality. The core components of LACA include (i) a fast and theoretically-grounded preprocessing technique for node attributes, (ii) an adaptive algorithm for diffusing any vectors over $G$ with rigorous theoretical guarantees and expedited convergence, and (iii) an effective three-step scheme for BDD approximation. Extensive experiments, comparing 17 competitors on 8 real datasets, show that LACA outperforms all competitors in terms of result quality measured against ground truth local clusters, while also being up to orders of magnitude faster. The code is available at https://github.com/HaoranZ99/alac.
Developing Cryptocurrency Trading Strategy Based on Autoencoder-CNN-GANs Algorithms
Dec 24, 2024


This paper leverages machine learning algorithms to forecast and analyze financial time series. The process begins with a denoising autoencoder to filter out random noise fluctuations from the main contract price data. Then, one-dimensional convolution reduces the dimensionality of the filtered data and extracts key information. The filtered and dimensionality-reduced price data is fed into a GANs network, and its output serve as input of a fully connected network. Through cross-validation, a model is trained to capture features that precede large price fluctuations. The model predicts the likelihood and direction of significant price changes in real-time price sequences, placing trades at moments of high prediction accuracy. Empirical results demonstrate that using autoencoders and convolution to filter and denoise financial data, combined with GANs, achieves a certain level of predictive performance, validating the capabilities of machine learning algorithms to discover underlying patterns in financial sequences. Keywords - CNN;GANs; Cryptocurrency; Prediction.
GraSP: Simple yet Effective Graph Similarity Predictions
Dec 13, 2024Graph similarity computation (GSC) is to calculate the similarity between one pair of graphs, which is a fundamental problem with fruitful applications in the graph community. In GSC, graph edit distance (GED) and maximum common subgraph (MCS) are two important similarity metrics, both of which are NP-hard to compute. Instead of calculating the exact values, recent solutions resort to leveraging graph neural networks (GNNs) to learn data-driven models for the estimation of GED and MCS. Most of them are built on components involving node-level interactions crossing graphs, which engender vast computation overhead but are of little avail in effectiveness. In the paper, we present GraSP, a simple yet effective GSC approach for GED and MCS prediction. GraSP achieves high result efficacy through several key instruments: enhanced node features via positional encoding and a GNN model augmented by a gating mechanism, residual connections, as well as multi-scale pooling. Theoretically, GraSP can surpass the 1-WL test, indicating its high expressiveness. Empirically, extensive experiments comparing GraSP against 10 competitors on multiple widely adopted benchmark datasets showcase the superiority of GraSP over prior arts in terms of both effectiveness and efficiency. The code is available at https://github.com/HaoranZ99/GraSP.
Spectral Subspace Clustering for Attributed Graphs
Nov 17, 2024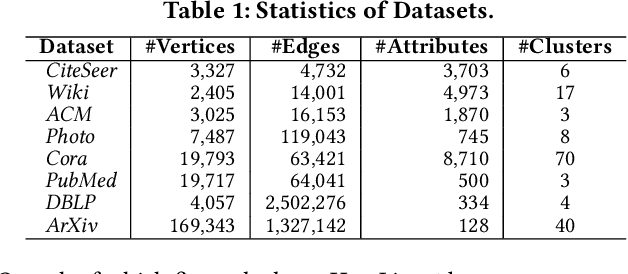
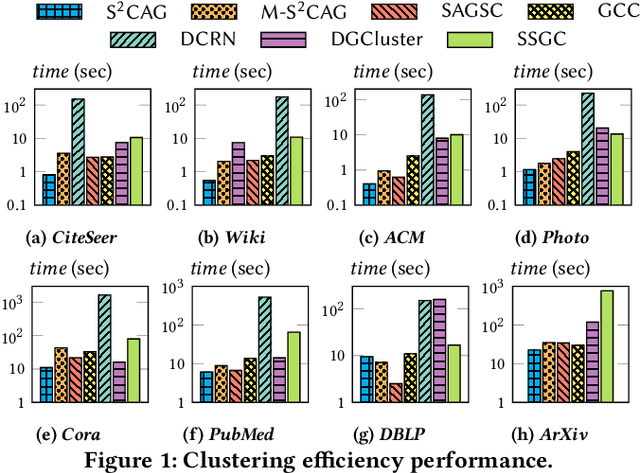
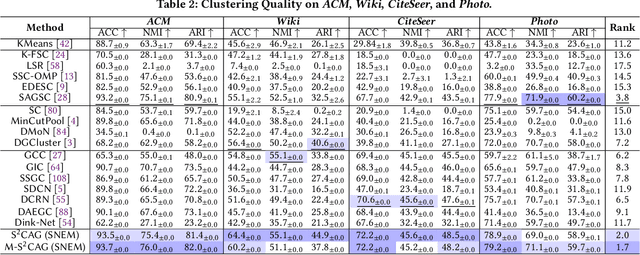
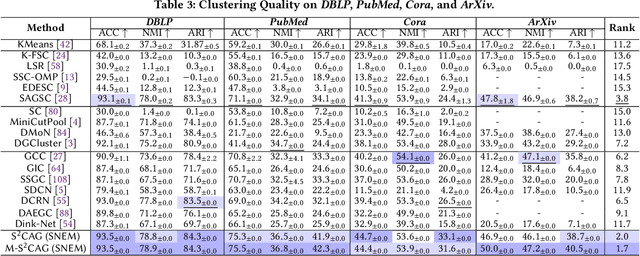
Subspace clustering seeks to identify subspaces that segment a set of n data points into k (k<<n) groups, which has emerged as a powerful tool for analyzing data from various domains, especially images and videos. Recently, several studies have demonstrated the great potential of subspace clustering models for partitioning vertices in attributed graphs, referred to as SCAG. However, these works either demand significant computational overhead for constructing the nxn self-expressive matrix, or fail to incorporate graph topology and attribute data into the subspace clustering framework effectively, and thus, compromise result quality. Motivated by this, this paper presents two effective and efficient algorithms, S2CAG and M-S2CAG, for SCAG computation. Particularly, S2CAG obtains superb performance through three major contributions. First, we formulate a new objective function for SCAG with a refined representation model for vertices and two non-trivial constraints. On top of that, an efficient linear-time optimization solver is developed based on our theoretically grounded problem transformation and well-thought-out adaptive strategy. We then conduct an in-depth analysis to disclose the theoretical connection of S2CAG to conductance minimization, which further inspires the design of M-S2CAG that maximizes the modularity. Our extensive experiments, comparing S2CAG and M-S2CAG against 17 competitors over 8 benchmark datasets, exhibit that our solutions outperform all baselines in terms of clustering quality measured against the ground truth while delivering high efficiency
SCENE: Evaluating Explainable AI Techniques Using Soft Counterfactuals
Aug 08, 2024Explainable Artificial Intelligence (XAI) is essential for enhancing the transparency and accountability of AI models, especially in natural language processing (NLP) tasks. This paper introduces SCENE (Soft Counterfactual Evaluation for Natural language Explainability), a novel evaluation method that leverages large language models (LLMs) to generate Soft Counterfactual explanations in a zero-shot manner. By focusing on token-based substitutions, SCENE creates contextually appropriate and seman-tically meaningful Soft Counterfactuals without extensive fine-tuning. SCENE adopts Validitysoft and Csoft metrics to evaluate the effectiveness of model-agnostic XAI methods in text classification tasks. Applied to CNN, RNN, and BERT architectures, SCENE provides valuable insights into the strengths and limitations of various XAI techniques.