 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Stage GPU Kernel Tuner Combining Semantic Refactoring and Search-Based Optimization
Jan 21, 2026GPU code optimization is a key performance bottleneck for HPC workloads as well as large-model training and inference. Although compiler optimizations and hand-written kernels can partially alleviate this issue, achieving near-hardware-limit performance still relies heavily on manual code refactoring and parameter tuning. Recent progress in LLM-agent-based kernel generation and optimization has been reported, yet many approaches primarily focus on direct code rewriting, where parameter choices are often implicit and hard to control, or require human intervention, leading to unstable performance gains. This paper introduces a template-based rewriting layer on top of an agent-driven iterative loop: kernels are semantically refactored into explicitly parameterizable templates, and template parameters are then optimized via search-based autotuning, yielding more stable and higher-quality speedups. Experiments on a set of real-world kernels demonstrate speedups exceeding 3x in the best case. We extract representative CUDA kernels from SGLang as evaluation targets; the proposed agentic tuner iteratively performs templating, testing, analysis, and planning, and leverages profiling feedback to execute constrained parameter search under hardware resource limits. Compared to agent-only direct rewriting, the template-plus-search design significantly reduces the randomness of iterative optimization, making the process more interpretable and enabling a more systematic approach toward high-performance configurations. The proposed method can be further extended to OpenCL, HIP, and other backends to deliver automated performance optimization for real production workloads.
MVSS: A Unified Framework for Multi-View Structured Survey Generation
Jan 14, 2026Scientific surveys require not only summarizing large bodies of literature, but also organizing them into clear and coherent conceptual structures. Existing automatic survey generation methods typically focus on linear text generation and struggle to explicitly model hierarchical relations among research topics and structured methodological comparisons, resulting in gaps in structural organization compared to expert-written surveys. We propose MVSS, a multi-view structured survey generation framework that jointly generates and aligns citation-grounded hierarchical trees, structured comparison tables, and survey text. MVSS follows a structure-first paradigm: it first constructs a conceptual tree of the research domain, then generates comparison tables constrained by the tree, and finally uses both as structural constraints for text generation. This enables complementary multi-view representations across structure, comparison, and narrative. We introduce an evaluation framework assessing structural quality, comparative completeness, and citation fidelity. Experiments on 76 computer science topics show MVSS outperforms existing methods in organization and evidence grounding, achieving performance comparable to expert surveys.
MM-UAVBench: How Well Do Multimodal Large Language Models See, Think, and Plan in Low-Altitude UAV Scenarios?
Dec 29, 2025While Multimodal Large Language Models (MLLMs) have exhibited remarkable general intelligence across diverse domains, their potential in low-altitude applications dominated by Unmanned Aerial Vehicles (UAVs) remains largely underexplored. Existing MLLM benchmarks rarely cover the unique challenges of low-altitude scenarios, while UAV-related evaluations mainly focus on specific tasks such as localization or navigation, without a unified evaluation of MLLMs'general intelligence. To bridge this gap, we present MM-UAVBench, a comprehensive benchmark that systematically evaluates MLLMs across three core capability dimensions-perception, cognition, and planning-in low-altitude UAV scenarios. MM-UAVBench comprises 19 sub-tasks with over 5.7K manually annotated questions, all derived from real-world UAV data collected from public datasets. Extensive experiments on 16 open-source and proprietary MLLMs reveal that current models struggle to adapt to the complex visual and cognitive demands of low-altitude scenarios. Our analyses further uncover critical bottlenecks such as spatial bias and multi-view understanding that hinder the effective deployment of MLLMs in UAV scenarios. We hope MM-UAVBench will foster future research on robust and reliable MLLMs for real-world UAV intelligence.
RedNote-Vibe: A Dataset for Capturing Temporal Dynamics of AI-Generated Text in Social Media
Sep 26, 2025



The proliferation of Large Language Models (LLMs) has led to widespread AI-Generated Text (AIGT) on social media platforms, creating unique challenges where content dynamics are driven by user engagement and evolve over time. However, existing datasets mainly depict static AIGT detection. In this work, we introduce RedNote-Vibe, the first longitudinal (5-years) dataset for social media AIGT analysis. This dataset is sourced from Xiaohongshu platform, containing user engagement metrics (e.g., likes, comments) and timestamps spanning from the pre-LLM period to July 2025, which enables research into the temporal dynamics and user interaction patterns of AIGT. Furthermore, to detect AIGT in the context of social media, we propose PsychoLinguistic AIGT Detection Framework (PLAD), an interpretable approach that leverages psycholinguistic features. Our experiments show that PLAD achieves superior detection performance and provides insights into the signatures distinguishing human and AI-generated content. More importantly, it reveals the complex relationship between these linguistic features and social media engagement. The dataset is available at https://github.com/testuser03158/RedNote-Vibe.
Invariant Graph Transformer for Out-of-Distribution Generalization
Aug 01, 2025Graph Transformers (GTs) have demonstrated great effectiveness across various graph analytical tasks. However, the existing GTs focus on training and testing graph data originated from the same distribution, but fail to generalize under distribution shifts. Graph invariant learning, aiming to capture generalizable graph structural patterns with labels under distribution shifts, is potentially a promising solution, but how to design attention mechanisms and positional and structural encodings (PSEs) based on graph invariant learning principles remains challenging. To solve these challenges, we introduce Graph Out-Of-Distribution generalized Transformer (GOODFormer), aiming to learn generalized graph representations by capturing invariant relationships between predictive graph structures and labels through jointly optimizing three modules. Specifically, we first develop a GT-based entropy-guided invariant subgraph disentangler to separate invariant and variant subgraphs while preserving the sharpness of the attention function. Next, we design an evolving subgraph positional and structural encoder to effectively and efficiently capture the encoding information of dynamically changing subgraphs during training. Finally, we propose an invariant learning module utilizing subgraph node representations and encodings to derive generalizable graph representations that can to unseen graphs. We also provide theoretical justifications for our method. Extensive experiments on benchmark datasets demonstrate the superiority of our method over state-of-the-art baselines under distribution shifts.
GraphRAG-R1: Graph Retrieval-Augmented Generation with Process-Constrained Reinforcement Learning
Jul 31, 2025Graph Retrieval-Augmented Generation (GraphRAG) has shown great effectiveness in enhancing the reasoning abilities of LLMs by leveraging graph structures for knowledge representation and modeling complex real-world relationships. However, existing GraphRAG methods still face significant bottlenecks when handling complex problems that require multi-hop reasoning, as their query and retrieval phases are largely based on pre-defined heuristics and do not fully utilize the reasoning potentials of LLMs. To address this problem, we propose GraphRAG-R1, an adaptive GraphRAG framework by training LLMs with process-constrained outcome-based reinforcement learning (RL) to enhance the multi-hop reasoning ability. Our method can decompose complex problems, autonomously invoke retrieval tools to acquire necessary information, and perform effective reasoning. Specifically, we utilize a modified version of Group Relative Policy Optimization (GRPO) that supports rollout-with-thinking capability. Next, we design two process-constrained reward functions. To handle the shallow retrieval problem, we design a Progressive Retrieval Attenuation (PRA) reward to encourage essential retrievals. Then, to handle the over-thinking problem, we design Cost-Aware F1 (CAF) reward to balance the model performance with computational costs. We further design a phase-dependent training strategy, containing three training stages corresponding to cold start and these two rewards. Lastly, our method adopts a hybrid graph-textual retrieval to improve the reasoning capacity. Extensive experimental results demonstrate that GraphRAG-R1 boosts LLM capabilities in solving complex reasoning problems compared to state-of-the-art GraphRAG methods on both in-domain and out-of-domain datasets. Furthermore, our framework can be flexibly integrated with various existing retrieval methods, consistently delivering performance improvements.
MrM: Black-Box Membership Inference Attacks against Multimodal RAG Systems
Jun 09, 2025



Multimodal retrieval-augmented generation (RAG) systems enhance large vision-language models by integrating cross-modal knowledge, enabling their increasing adoption across real-world multimodal tasks. These knowledge databases may contain sensitive information that requires privacy protection. However, multimodal RAG systems inherently grant external users indirect access to such data, making them potentially vulnerable to privacy attacks, particularly membership inference attacks (MIAs). % Existing MIA methods targeting RAG systems predominantly focus on the textual modality, while the visual modality remains relatively underexplored. To bridge this gap, we propose MrM, the first black-box MIA framework targeted at multimodal RAG systems. It utilizes a multi-object data perturbation framework constrained by counterfactual attacks, which can concurrently induce the RAG systems to retrieve the target data and generate information that leaks the membership information. Our method first employs an object-aware data perturbation method to constrain the perturbation to key semantics and ensure successful retrieval. Building on this, we design a counterfact-informed mask selection strategy to prioritize the most informative masked regions, aiming to eliminate the interference of model self-knowledge and amplify attack efficacy. Finally, we perform statistical membership inference by modeling query trials to extract features that reflect the reconstruction of masked semantics from response patterns. Experiments on two visual datasets and eight mainstream commercial visual-language models (e.g., GPT-4o, Gemini-2) demonstrate that MrM achieves consistently strong performance across both sample-level and set-level evaluations, and remains robust under adaptive defenses.
HPSS: Heuristic Prompting Strategy Search for LLM Evaluators
Feb 18, 2025
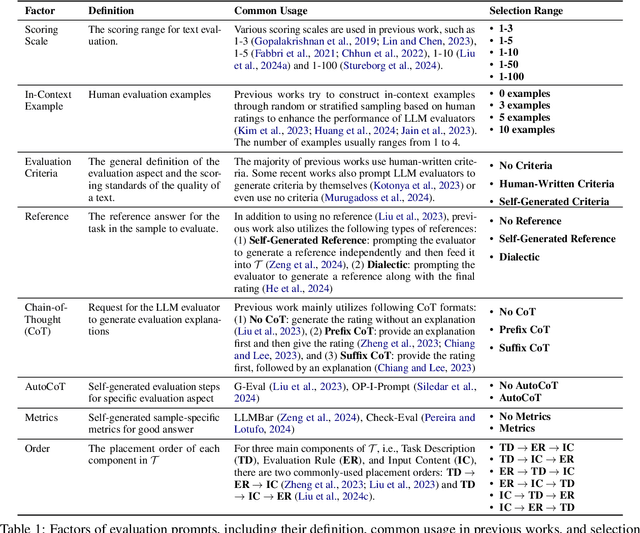
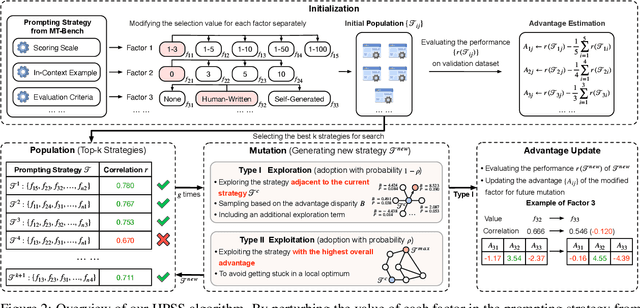
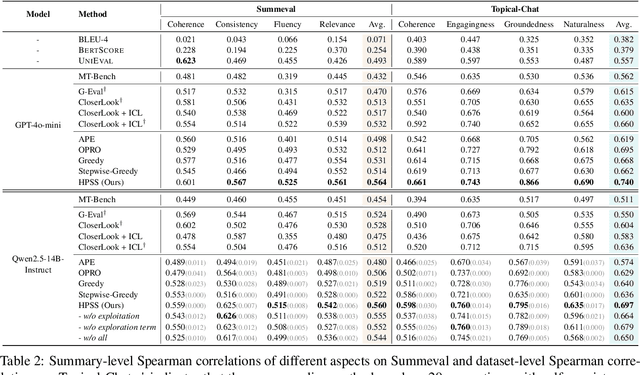
Since the adoption of large language models (LLMs) for text evaluation has become increasingly prevalent in the field of natural language processing (NLP), a series of existing works attempt to optimize the prompts for LLM evaluators to improve their alignment with human judgment. However, their efforts are limited to optimizing individual factors of evaluation prompts, such as evaluation criteria or output formats, neglecting the combinatorial impact of multiple factors, which leads to insufficient optimization of the evaluation pipeline. Nevertheless, identifying well-behaved prompting strategies for adjusting multiple factors requires extensive enumeration. To this end, we comprehensively integrate 8 key factors for evaluation prompts and propose a novel automatic prompting strategy optimization method called Heuristic Prompting Strategy Search (HPSS). Inspired by the genetic algorithm, HPSS conducts an iterative search to find well-behaved prompting strategies for LLM evaluators. A heuristic function is employed to guide the search process, enhancing the performance of our algorithm. Extensive experiments across four evaluation tasks demonstrate the effectiveness of HPSS, consistently outperforming both human-designed evaluation prompts and existing automatic prompt optimization methods.
Deep Feature Surgery: Towards Accurate and Efficient Multi-Exit Networks
Jul 19, 2024



Multi-exit network is a promising architecture for efficient model inference by sharing backbone networks and weights among multiple exits. However, the gradient conflict of the shared weights results in sub-optimal accuracy. This paper introduces Deep Feature Surgery (\methodname), which consists of feature partitioning and feature referencing approaches to resolve gradient conflict issues during the training of multi-exit networks. The feature partitioning separates shared features along the depth axis among all exits to alleviate gradient conflict while simultaneously promoting joint optimization for each exit. Subsequently, feature referencing enhances multi-scale features for distinct exits across varying depths to improve the model accuracy. Furthermore, \methodname~reduces the training operations with the reduced complexity of backpropagation. Experimental results on Cifar100 and ImageNet datasets exhibit that \methodname~provides up to a \textbf{50.00\%} reduction in training time and attains up to a \textbf{6.94\%} enhancement in accuracy when contrasted with baseline methods across diverse models and tasks. Budgeted batch classification evaluation on MSDNet demonstrates that DFS uses about $\mathbf{2}\boldsymbol{\times}$ fewer average FLOPs per image to achieve the same classification accuracy as baseline methods on Cifar100.
Learning Fair Face Representation With Progressive Cross Transformer
Aug 11, 2021

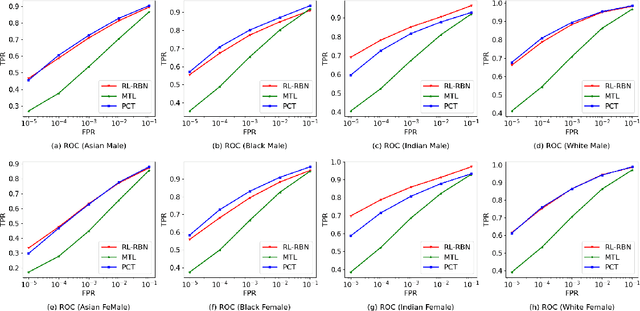

Face recognition (FR) has made extraordinary progress owing to the advancement of deep convolutional neural networks. However, demographic bias among different racial cohorts still challenges the practical face recognition system. The race factor has been proven to be a dilemma for fair FR (FFR) as the subject-related specific attributes induce the classification bias whilst carrying some useful cues for FR. To mitigate racial bias and meantime preserve robust FR, we abstract face identity-related representation as a signal denoising problem and propose a progressive cross transformer (PCT) method for fair face recognition. Originating from the signal decomposition theory, we attempt to decouple face representation into i) identity-related components and ii) noisy/identity-unrelated components induced by race. As an extension of signal subspace decomposition, we formulate face decoupling as a generalized functional expression model to cross-predict face identity and race information. The face expression model is further concretized by designing dual cross-transformers to distill identity-related components and suppress racial noises. In order to refine face representation, we take a progressive face decoupling way to learn identity/race-specific transformations, so that identity-unrelated components induced by race could be better disentangled. We evaluate the proposed PCT on the public fair face recognition benchmarks (BFW, RFW) and verify that PCT is capable of mitigating bias in face recognition while achieving state-of-the-art FR performance. Besides, visualization results also show that the attention maps in PCT can well reveal the race-related/biased facial regions.