 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouchGuide: Inference-Time Steering of Visuomotor Policies via Touch Guidance
Jan 28, 2026Fine-grained and contact-rich manipulation remain challenging for robots, largely due to the underutilization of tactile feedback. To address this, we introduce TouchGuide, a novel cross-policy visuo-tactile fusion paradigm that fuses modalities within a low-dimensional action space. Specifically, TouchGuide operates in two stages to guide a pre-trained diffusion or flow-matching visuomotor policy at inference time. First, the policy produces a coarse, visually-plausible action using only visual inputs during early sampling. Second, a task-specific Contact Physical Model (CPM) provides tactile guidance to steer and refine the action, ensuring it aligns with realistic physical contact conditions. Trained through contrastive learning on limited expert demonstrations, the CPM provides a tactile-informed feasibility score to steer the sampling process toward refined actions that satisfy physical contact constraints. Furthermore, to facilitate TouchGuide training with high-quality and cost-effective data, we introduce TacUMI, a data collection system. TacUMI achieves a favorable trade-off between precision and affordability; by leveraging rigid fingertips, it obtains direct tactile feedback, thereby enabling the collection of reliable tactile data. Extensive experiments on five challenging contact-rich tasks, such as shoe lacing and chip handover, show that TouchGuide consistently and significantly outperforms state-of-the-art visuo-tactile policies.
A Two-Stage GPU Kernel Tuner Combining Semantic Refactoring and Search-Based Optimization
Jan 21, 2026GPU code optimization is a key performance bottleneck for HPC workloads as well as large-model training and inference. Although compiler optimizations and hand-written kernels can partially alleviate this issue, achieving near-hardware-limit performance still relies heavily on manual code refactoring and parameter tuning. Recent progress in LLM-agent-based kernel generation and optimization has been reported, yet many approaches primarily focus on direct code rewriting, where parameter choices are often implicit and hard to control, or require human intervention, leading to unstable performance gains. This paper introduces a template-based rewriting layer on top of an agent-driven iterative loop: kernels are semantically refactored into explicitly parameterizable templates, and template parameters are then optimized via search-based autotuning, yielding more stable and higher-quality speedups. Experiments on a set of real-world kernels demonstrate speedups exceeding 3x in the best case. We extract representative CUDA kernels from SGLang as evaluation targets; the proposed agentic tuner iteratively performs templating, testing, analysis, and planning, and leverages profiling feedback to execute constrained parameter search under hardware resource limits. Compared to agent-only direct rewriting, the template-plus-search design significantly reduces the randomness of iterative optimization, making the process more interpretable and enabling a more systematic approach toward high-performance configurations. The proposed method can be further extended to OpenCL, HIP, and other backends to deliver automated performance optimization for real production workloads.
Toward Ultra-Long-Horizon Agentic Science: Cognitive Accumulation for Machine Learning Engineering
Jan 15, 2026The advancement of artificial intelligence toward agentic science is currently bottlenecked by the challenge of ultra-long-horizon autonomy, the ability to sustain strategic coherence and iterative correction over experimental cycles spanning days or weeks. While Large Language Models (LLMs) have demonstrated prowess in short-horizon reasoning, they are easily overwhelmed by execution details in the high-dimensional, delayed-feedback environments of real-world research, failing to consolidate sparse feedback into coherent long-term guidance. Here, we present ML-Master 2.0, an autonomous agent that masters ultra-long-horizon machine learning engineering (MLE) which is a representative microcosm of scientific discovery. By reframing context management as a process of cognitive accumulation, our approach introduces Hierarchical Cognitive Caching (HCC), a multi-tiered architecture inspired by computer systems that enables the structural differentiation of experience over time. By dynamically distilling transient execution traces into stable knowledge and cross-task wisdom, HCC allows agents to decouple immediate execution from long-term experimental strategy, effectively overcoming the scaling limits of static context windows. In evaluations on OpenAI's MLE-Bench under 24-hour budgets, ML-Master 2.0 achieves a state-of-the-art medal rate of 56.44%. Our findings demonstrate that ultra-long-horizon autonomy provides a scalable blueprint for AI capable of autonomous exploration beyond human-precedent complexities.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
PhysMaster: Building an Autonomous AI Physicist for Theoretical and Computational Physics Research
Dec 22, 2025Advances in LLMs have produced agents with knowledge and operational capabilities comparable to human scientists, suggesting potential to assist, accelerate, and automate research. However, existing studies mainly evaluate such systems on well-defined benchmarks or general tasks like literature retrieval, limiting their end-to-end problem-solving ability in open scientific scenarios. This is particularly true in physics, which is abstract, mathematically intensive, and requires integrating analytical reasoning with code-based computation. To address this, we propose PhysMaster, an LLM-based agent functioning as an autonomous theoretical and computational physicist. PhysMaster couples absract reasoning with numerical computation and leverages LANDAU, the Layered Academic Data Universe, which preserves retrieved literature, curated prior knowledge, and validated methodological traces, enhancing decision reliability and stability. It also employs an adaptive exploration strategy balancing efficiency and open-ended exploration, enabling robust performance in ultra-long-horizon tasks. We evaluate PhysMaster on problems from high-energy theory, condensed matter theory to astrophysics, including: (i) acceleration, compressing labor-intensive research from months to hours; (ii) automation, autonomously executing hypothesis-driven loops ; and (iii) autonomous discovery, independently exploring open problems.
GraphRAG-R1: Graph Retrieval-Augmented Generation with Process-Constrained Reinforcement Learning
Jul 31, 2025Graph Retrieval-Augmented Generation (GraphRAG) has shown great effectiveness in enhancing the reasoning abilities of LLMs by leveraging graph structures for knowledge representation and modeling complex real-world relationships. However, existing GraphRAG methods still face significant bottlenecks when handling complex problems that require multi-hop reasoning, as their query and retrieval phases are largely based on pre-defined heuristics and do not fully utilize the reasoning potentials of LLMs. To address this problem, we propose GraphRAG-R1, an adaptive GraphRAG framework by training LLMs with process-constrained outcome-based reinforcement learning (RL) to enhance the multi-hop reasoning ability. Our method can decompose complex problems, autonomously invoke retrieval tools to acquire necessary information, and perform effective reasoning. Specifically, we utilize a modified version of Group Relative Policy Optimization (GRPO) that supports rollout-with-thinking capability. Next, we design two process-constrained reward functions. To handle the shallow retrieval problem, we design a Progressive Retrieval Attenuation (PRA) reward to encourage essential retrievals. Then, to handle the over-thinking problem, we design Cost-Aware F1 (CAF) reward to balance the model performance with computational costs. We further design a phase-dependent training strategy, containing three training stages corresponding to cold start and these two rewards. Lastly, our method adopts a hybrid graph-textual retrieval to improve the reasoning capacity. Extensive experimental results demonstrate that GraphRAG-R1 boosts LLM capabilities in solving complex reasoning problems compared to state-of-the-art GraphRAG methods on both in-domain and out-of-domain datasets. Furthermore, our framework can be flexibly integrated with various existing retrieval methods, consistently delivering performance improvements.
Car-GS: Addressing Reflective and Transparent Surface Challenges in 3D Car Reconstruction
Jan 19, 2025



3D car modeling is crucial for applications in autonomous driving systems, virtual and augmented reality, and gaming. However, due to the distinctive properties of cars, such as highly reflective and transparent surface materials, existing methods often struggle to achieve accurate 3D car reconstruction.To address these limitations, we propose Car-GS, a novel approach designed to mitigate the effects of specular highlights and the coupling of RGB and geometry in 3D geometric and shading reconstruction (3DGS). Our method incorporates three key innovations: First, we introduce view-dependent Gaussian primitives to effectively model surface reflections. Second, we identify the limitations of using a shared opacity parameter for both image rendering and geometric attributes when modeling transparent objects. To overcome this, we assign a learnable geometry-specific opacity to each 2D Gaussian primitive, dedicated solely to rendering depth and normals. Third, we observe that reconstruction errors are most prominent when the camera view is nearly orthogonal to glass surfaces. To address this issue, we develop a quality-aware supervision module that adaptively leverages normal priors from a pre-trained large-scale normal model.Experimental results demonstrate that Car-GS achieves precise reconstruction of car surfaces and significantly outperforms prior methods. The project page is available at https://lcc815.github.io/Car-GS.
Deep Feature Surgery: Towards Accurate and Efficient Multi-Exit Networks
Jul 19, 2024



Multi-exit network is a promising architecture for efficient model inference by sharing backbone networks and weights among multiple exits. However, the gradient conflict of the shared weights results in sub-optimal accuracy. This paper introduces Deep Feature Surgery (\methodname), which consists of feature partitioning and feature referencing approaches to resolve gradient conflict issues during the training of multi-exit networks. The feature partitioning separates shared features along the depth axis among all exits to alleviate gradient conflict while simultaneously promoting joint optimization for each exit. Subsequently, feature referencing enhances multi-scale features for distinct exits across varying depths to improve the model accuracy. Furthermore, \methodname~reduces the training operations with the reduced complexity of backpropagation. Experimental results on Cifar100 and ImageNet datasets exhibit that \methodname~provides up to a \textbf{50.00\%} reduction in training time and attains up to a \textbf{6.94\%} enhancement in accuracy when contrasted with baseline methods across diverse models and tasks. Budgeted batch classification evaluation on MSDNet demonstrates that DFS uses about $\mathbf{2}\boldsymbol{\times}$ fewer average FLOPs per image to achieve the same classification accuracy as baseline methods on Cifar100.
Uni-ELF: A Multi-Level Representation Learning Framework for Electrolyte Formulation Design
Jul 08, 2024



Advancements in lithium battery technology heavily rely on the design and engineering of electrolytes. However, current schemes for molecular design and recipe optimization of electrolytes lack an effective computational-experimental closed loop and often fall short in accurately predicting diverse electrolyte formulation properties. In this work, we introduce Uni-ELF, a novel multi-level representation learning framework to advance electrolyte design. Our approach involves two-stage pretraining: reconstructing three-dimensional molecular structures at the molecular level using the Uni-Mol model, and predicting statistical structural properties (e.g., radial distribution functions) from molecular dynamics simulations at the mixture level. Through this comprehensive pretraining, Uni-ELF is able to capture intricate molecular and mixture-level information, which significantly enhances its predictive capability. As a result, Uni-ELF substantially outperforms state-of-the-art methods in predicting both molecular properties (e.g., melting point, boiling point, synthesizability) and formulation properties (e.g., conductivity, Coulombic efficiency). Moreover, Uni-ELF can be seamlessly integrated into an automatic experimental design workflow. We believe this innovative framework will pave the way for automated AI-based electrolyte design and engineering.
Minimize Quantization Output Error with Bias Compensation
Apr 02, 2024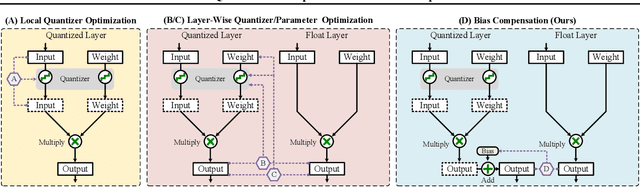
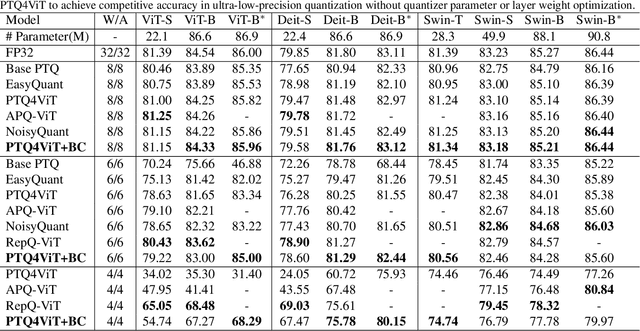
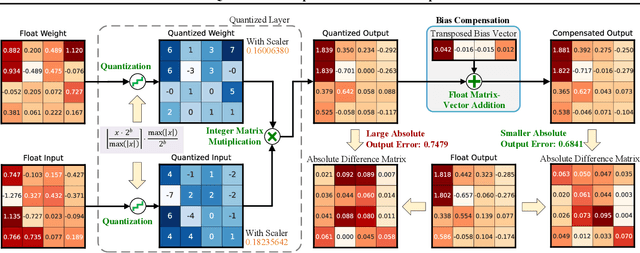
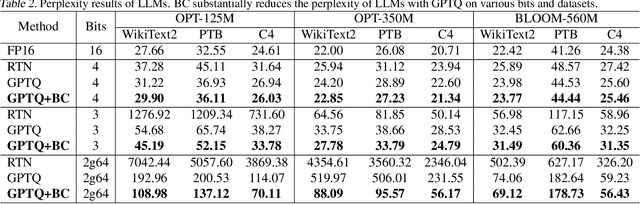
Quantization is a promising method that reduces memory usage and computational intensity of Deep Neural Networks (DNNs), but it often leads to significant output error that hinder model deployment. In this paper, we propose Bias Compensation (BC) to minimize the output error, thus realizing ultra-low-precision quantization without model fine-tuning. Instead of optimizing the non-convex quantization process as in most previous methods, the proposed BC bypasses the step to directly minimize the quantizing output error by identifying a bias vector for compensation. We have established that the minimization of output error through BC is a convex problem and provides an efficient strategy to procure optimal solutions associated with minimal output error,without the need for training or fine-tuning. We conduct extensive experiments on Vision Transformer models and Large Language Models, and the results show that our method notably reduces quantization output error, thereby permitting ultra-low-precision post-training quantization and enhancing the task performance of models. Especially, BC improves the accuracy of ViT-B with 4-bit PTQ4ViT by 36.89% on the ImageNet-1k task, and decreases the perplexity of OPT-350M with 3-bit GPTQ by 5.97 on WikiText2.The code is in https://github.com/GongCheng1919/bias-compensation.