 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSARCLIP: A Vision Language Foundation Model for Semantic Understanding and Target Recognition in SAR Imagery
Oct 26, 2025Synthetic Aperture Radar (SAR) has emerged as a crucial imaging modality due to its all-weather capabilities. While recent advancements in self-supervised learning and Masked Image Modeling (MIM) have paved the way for SAR foundation models, these approaches primarily focus on low-level visual features, often overlooking multimodal alignment and zero-shot target recognition within SAR imagery. To address this limitation, we construct SARCLIP-1M, a large-scale vision language dataset comprising over one million text-image pairs aggregated from existing datasets. We further introduce SARCLIP, the first vision language foundation model tailored for the SAR domain. Our SARCLIP model is trained using a contrastive vision language learning approach by domain transferring strategy, enabling it to bridge the gap between SAR imagery and textual descriptions. Extensive experiments on image-text retrieval and zero-shot classification tasks demonstrate the superior performance of SARCLIP in feature extraction and interpretation, significantly outperforming state-of-the-art foundation models and advancing the semantic understanding of SAR imagery. The code and datasets will be released soon.
Which Channel in 6G, Low-rank or Full-rank, more needs RIS?
Dec 04, 2024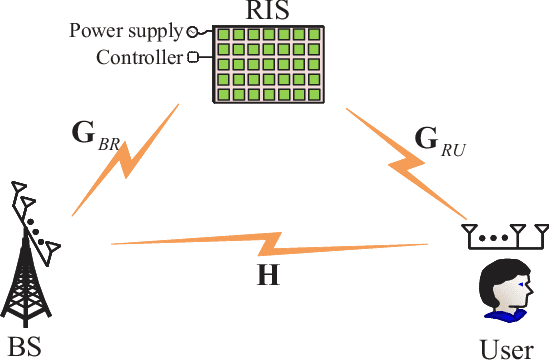



Reconfigurable intelligent surface (RIS), as an efficient tool to improve receive signal-to-noise ratio, extend coverage and create more spatial diversity, is viewed as a most promising technique for the future wireless networks like 6G. As you know, RIS is very suitable for a special wireless scenario with wireless link between BS and users being completely blocked, i.e., no link. In this paper, we extend its applications to a general scenario, i.e., rank-deficient channel, particularly some extremely low-rank ones such as no link, and line-of-sight (LoS, rank-one). Actually, there are several potential important low-rank applications like low-altitude, satellite, UAV, marine, and deep-space communications. In such a situation, it is found that RIS may make a dramatic degrees of freedom (DoF) enhancement over no RIS. By using a distributed RISs placement, the DoF of channel from BS to user in LoS channel may be even boosted from a low-rank like 0/1 to full-rank. This will achieve an extremely rate improvement via spatial parallel multiple-stream transmission from BS to user. In this paper, we present a complete review of making an in-depth discussion on DoF effect of RIS.
Fast High-Quality Enhanced Imaging Algorithm for Layered Dielectric Targets Based on MMW MIMO-SAR System
Nov 22, 2024Millimeter-wave (MMW) multiple-input multiple-output synthetic aperture radar (MIMO-SAR) system is a technology that can achieve high resolution, high frame rate, and all-weather imaging and has received extensive attention in the non-destructive testing and internal imaging applications of layered dielectric targets. However, the non-ideal scattering effect caused by dielectric materials can significantly deteriorate the imaging quality when using the existing MIMO-SAR fast algorithms. This paper proposes a rapid, high-quality dielectric target-enhanced imaging algorithm for a new universal non-uniform MIMO-SAR system. The algorithm builds on the existing non-uniform MIMO-SAR dielectric target frequency-domain algorithm (DT-FDA) by constructing a forward sensing operator and incorporating it into the alternating direction method of multipliers (ADMM) framework. This approach avoids large matrix operations while maintaining computational efficiency. By integrating an optimal regularization parameter search, the algorithm enhances the image reconstruction quality of dielectric internal structures or defects. Experimental results show the proposed algorithm outperforms IBP and DT-FDA, achieving better focusing, sidelobe suppression, and 3D imaging accuracy. It yields the lowest image entropy (8.864) and significantly improves efficiency (imaging time: 15.29 s vs. 23295.3 s for IBP).
Which Channel, Low-rank or Full-rank, more needs RIS?
Nov 21, 2024RIS, as an efficient tool to improve receive signal-to-noise ratio, extend coverage and create more spatial diversity, is viewed as a most promising technique for the future wireless networks like 6G. As you know, IRS is very suitable for a special wireless scenario with wireless link between BS and users being completely blocked. In this paper, we extend its applications to a general scenario, i.e., rank-deficient-channel, particularly some extremely low-rank ones such as no link, and line-of-sight (LoS). Actually, there are several potential important low-rank applications of like satellite, UAV communications, marine, and deep-space communications. In such a situation, it is found that RIS may make a dramatic DoF enhancement over no RIS. By using a distributed RIS placement, the DoF of channels from BS to users may be even boosted from a low-rank like 0/1 to full-rank. This will achieve an extremely rate improvement via multiple spatial streams transmission per user. In this paper, we present a complete review of make a in-depth discussion on DoF effect of RIS.
Uni-ELF: A Multi-Level Representation Learning Framework for Electrolyte Formulation Design
Jul 08, 2024



Advancements in lithium battery technology heavily rely on the design and engineering of electrolytes. However, current schemes for molecular design and recipe optimization of electrolytes lack an effective computational-experimental closed loop and often fall short in accurately predicting diverse electrolyte formulation properties. In this work, we introduce Uni-ELF, a novel multi-level representation learning framework to advance electrolyte design. Our approach involves two-stage pretraining: reconstructing three-dimensional molecular structures at the molecular level using the Uni-Mol model, and predicting statistical structural properties (e.g., radial distribution functions) from molecular dynamics simulations at the mixture level. Through this comprehensive pretraining, Uni-ELF is able to capture intricate molecular and mixture-level information, which significantly enhances its predictive capability. As a result, Uni-ELF substantially outperforms state-of-the-art methods in predicting both molecular properties (e.g., melting point, boiling point, synthesizability) and formulation properties (e.g., conductivity, Coulombic efficiency). Moreover, Uni-ELF can be seamlessly integrated into an automatic experimental design workflow. We believe this innovative framework will pave the way for automated AI-based electrolyte design and engineering.
Universal Domain Adaptation from Foundation Models
May 18, 2023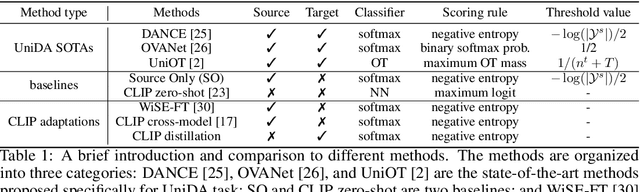
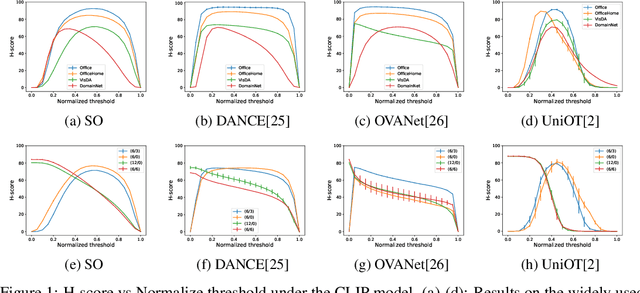
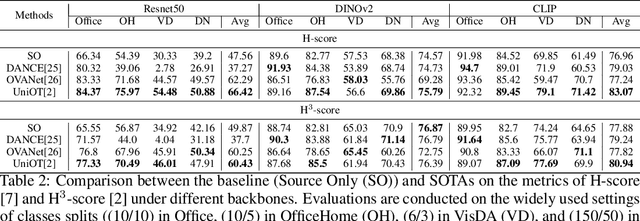
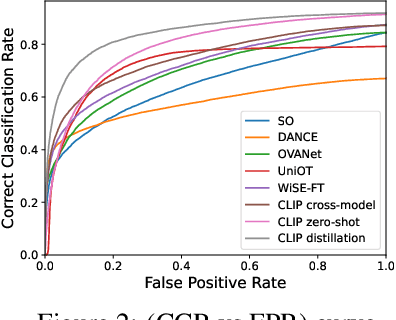
Foundation models (e.g., CLIP or DINOv2) have shown their impressive learning and transferring capabilities on a wide range of visual tasks, by training on a large corpus of data and adapting to specific downstream tasks. It is, however, interesting that foundation models have not been fully explored for universal domain adaptation (UniDA), which is to learn models using labeled data in a source domain and unlabeled data in a target one, such that the learned models can successfully adapt to the target data. In this paper, we make comprehensive empirical studies of state-of-the-art UniDA methods using foundation models. We first demonstrate that, while foundation models greatly improve the performance of the baseline methods that train the models on the source data alone, existing UniDA methods generally fail to improve over the baseline. This suggests that new research efforts are very necessary for UniDA using foundation models. To this end, we propose a very simple method of target data distillation on the CLIP model, and achieves consistent improvement over the baseline across all the UniDA benchmarks. Our studies are under a newly proposed evaluation metric of universal classification rate (UCR), which is threshold- and ratio-free and addresses the threshold-sensitive issue encountered when using the existing H-score metric.
Adversarial Style Augmentation for Domain Generalization
Jan 30, 2023It is well-known that the performance of well-trained deep neural networks may degrade significantly when they are applied to data with even slightly shifted distributions. Recent studies have shown that introducing certain perturbation on feature statistics (\eg, mean and standard deviation) during training can enhance the cross-domain generalization ability. Existing methods typically conduct such perturbation by utilizing the feature statistics within a mini-batch, limiting their representation capability. Inspired by the domain generalization objective, we introduce a novel Adversarial Style Augmentation (ASA) method, which explores broader style spaces by generating more effective statistics perturbation via adversarial training. Specifically, we first search for the most sensitive direction and intensity for statistics perturbation by maximizing the task loss. By updating the model against the adversarial statistics perturbation during training, we allow the model to explore the worst-case domain and hence improve its generalization performance. To facilitate the application of ASA, we design a simple yet effective module, namely AdvStyle, which instantiates the ASA method in a plug-and-play manner. We justify the efficacy of AdvStyle on tasks of cross-domain classification and instance retrieval. It achieves higher mean accuracy and lower performance fluctuation. Especially, our method significantly outperforms its competitors on the PACS dataset under the single source generalization setting, \eg, boosting the classification accuracy from 61.2\% to 67.1\% with a ResNet50 backbone. Our code will be available at \url{https://github.com/YBZh/AdvStyle}.
Counterfactual Supervision-based Information Bottleneck for Out-of-Distribution Generalization
Aug 16, 2022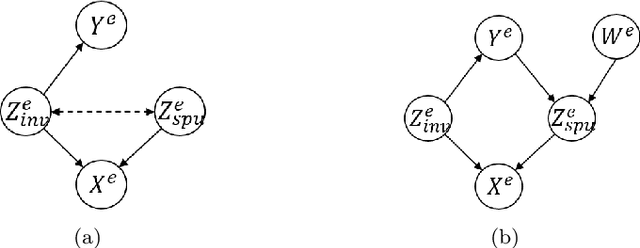

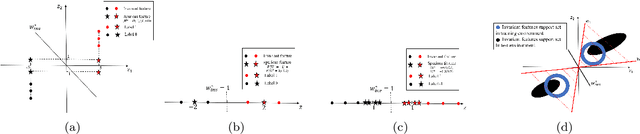
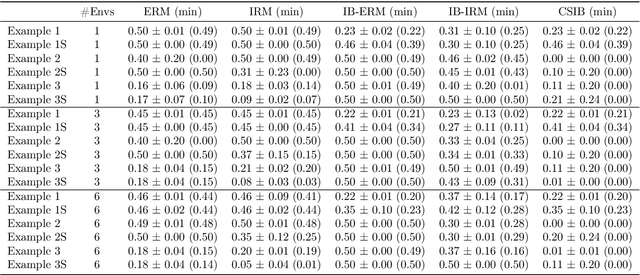
Learning invariant (causal) features for out-of-distribution (OOD) generalization has attracted extensive attention recently, and among the proposals invariant risk minimization (IRM) (Arjovsky et al., 2019) is a notable solution. In spite of its theoretical promise for linear regression, the challenges of using IRM in linear classification problems yet remain (Rosenfeld et al.,2020, Nagarajan et al., 2021). Along this line, a recent study (Arjovsky et al., 2019) has made a first step and proposes a learning principle of information bottleneck based invariant risk minimization (IB-IRM). In this paper, we first show that the key assumption of support overlap of invariant features used in (Arjovsky et al., 2019) is rather strong for the guarantee of OOD generalization and it is still possible to achieve the optimal solution without such assumption. To further answer the question of whether IB-IRM is sufficient for learning invariant features in linear classification problems, we show that IB-IRM would still fail in two cases whether or not the invariant features capture all information about the label. To address such failures, we propose a \textit{Counterfactual Supervision-based Information Bottleneck (CSIB)} learning algorithm that provably recovers the invariant features. The proposed algorithm works even when accessing data from a single environment, and has theoretically consistent results for both binary and multi-class problems. We present empirical experiments on three synthetic datasets that verify the efficacy of our proposed method.
Gradual Domain Adaptation via Self-Training of Auxiliary Models
Jun 18, 2021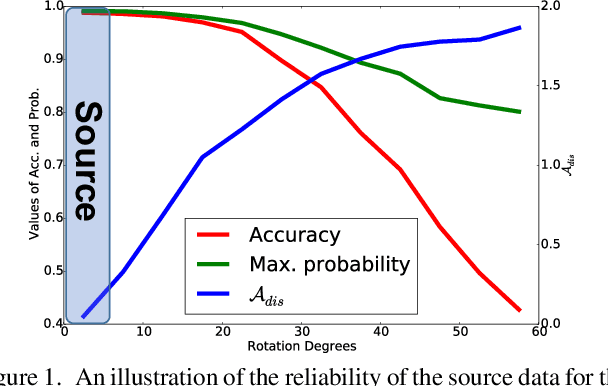
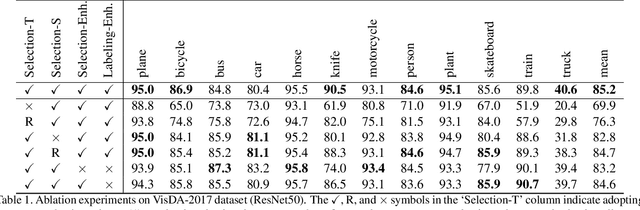
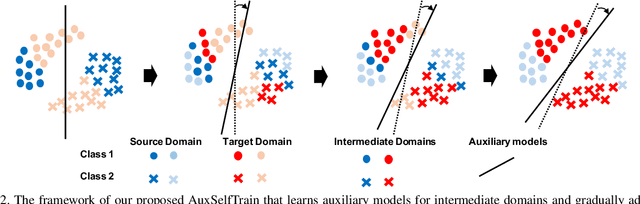
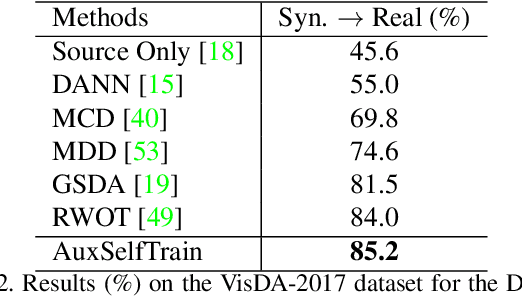
Domain adaptation becomes more challenging with increasing gaps between source and target domains. Motivated from an empirical analysis on the reliability of labeled source data for the use of distancing target domains, we propose self-training of auxiliary models (AuxSelfTrain) that learns models for intermediate domains and gradually combats the distancing shifts across domains. We introduce evolving intermediate domains as combinations of decreasing proportion of source data and increasing proportion of target data, which are sampled to minimize the domain distance between consecutive domains. Then the source model could be gradually adapted for the use in the target domain by self-training of auxiliary models on evolving intermediate domains. We also introduce an enhanced indicator for sample selection via implicit ensemble and extend the proposed method to semi-supervised domain adaptation. Experiments on benchmark datasets of unsupervised and semi-supervised domain adaptation verify its efficacy.
Semi-supervised Models are Strong Unsupervised Domain Adaptation Learners
Jun 01, 2021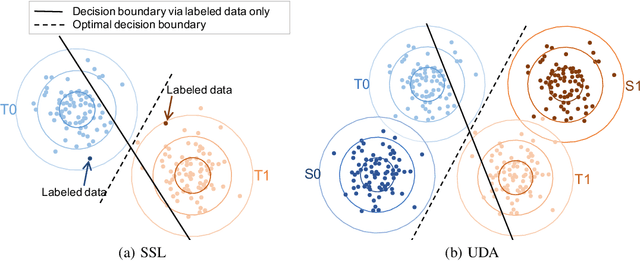

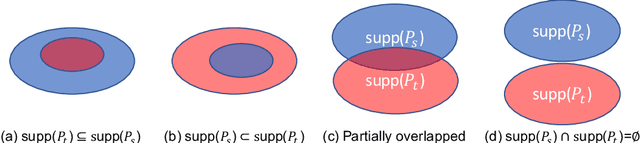
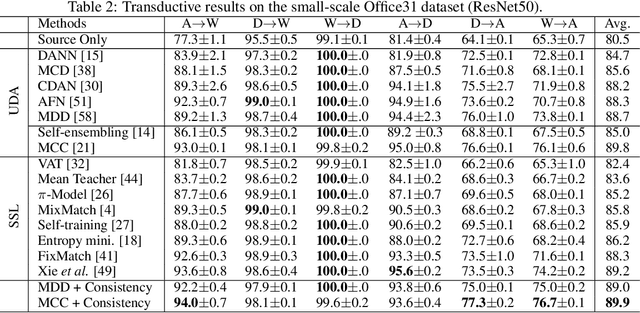
Unsupervised domain adaptation (UDA) and semi-supervised learning (SSL) are two typical strategies to reduce expensive manual annotations in machine learning. In order to learn effective models for a target task, UDA utilizes the available labeled source data, which may have different distributions from unlabeled samples in the target domain, while SSL employs few manually annotated target samples. Although UDA and SSL are seemingly very different strategies, we find that they are closely related in terms of task objectives and solutions, and SSL is a special case of UDA problems. Based on this finding, we further investigate whether SSL methods work on UDA tasks. By adapting eight representative SSL algorithms on UDA benchmarks, we show that SSL methods are strong UDA learners. Especially, state-of-the-art SSL methods significantly outperform existing UDA methods on the challenging UDA benchmark of DomainNet, and state-of-the-art UDA methods could be further enhanced with SSL techniques. We thus promote that SSL methods should be employed as baselines in future UDA studies and expect that the revealed relationship between UDA and SSL could shed light on future UDA development. Codes are available at \url{https://github.com/YBZh}.