 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawed and Dangerous: Can We Trust Open Agentic Systems?
Mar 27, 2026Open agentic systems combine LLM-based planning with external capabilities, persistent memory, and privileged execution. They are used in coding assistants, browser copilots, and enterprise automation. OpenClaw is a visible instance of this broader class. Without much attention yet, their security challenge is fundamentally different from that of traditional software that relies on predictable execution and well-defined control flow. In open agentic systems, everything is ''probabilistic'': plans are generated at runtime, key decisions may be shaped by untrusted natural-language inputs and tool outputs, execution unfolds in uncertain environments, and actions are taken under authority delegated by human users. The central challenge is therefore not merely robustness against individual attacks, but the governance of agentic behavior under persistent uncertainty. This paper systematizes the area through a software engineering lens. We introduce a six-dimensional analytical taxonomy and synthesize 50 papers spanning attacks, benchmarks, defenses, audits, and adjacent engineering foundations. From this synthesis, we derive a reference doctrine for secure-by-construction agent platforms, together with an evaluation scorecard for assessing platform security posture. Our review shows that the literature is relatively mature in attack characterization and benchmark construction, but remains weak in deployment controls, operational governance, persistent-memory integrity, and capability revocation. These gaps define a concrete engineering agenda for building agent ecosystems that are governable, auditable, and resilient under compromise.
PlanTwin: Privacy-Preserving Planning Abstractions for Cloud-Assisted LLM Agents
Mar 19, 2026Cloud-hosted large language models (LLMs) have become the de facto planners in agentic systems, coordinating tools and guiding execution over local environments. In many deployments, however, the environment being planned over is private, containing source code, files, credentials, and metadata that cannot be exposed to the cloud. Existing solutions address adjacent concerns, such as execution isolation, access control, or confidential inference, but they do not control what cloud planners observe during planning: within the permitted scope, \textit{raw environment state is still exposed}. We introduce PlanTwin, a privacy-preserving architecture for cloud-assisted planning without exposing raw local context. The key idea is to project the real environment into a \textit{planning-oriented digital twin}: a schema-constrained and de-identified abstract graph that preserves planning-relevant structure while removing reconstructable details. The cloud planner operates solely on this sanitized twin through a bounded capability interface, while a local gatekeeper enforces safety policies and cumulative disclosure budgets. We further formalize the privacy-utility trade-off as a capability granularity problem, define architectural privacy goals using $(k,δ)$-anonymity and $ε$-unlinkability, and mitigate compositional leakage through multi-turn disclosure control. We implement PlanTwin as middleware between local agents and cloud planners and evaluate it on 60 agentic tasks across ten domains with four cloud planners. PlanTwin achieves full sensitive-item non-disclosure (SND = 1.0) while maintaining planning quality close to full-context systems: three of four planners achieve PQS $> 0.79$, and the full pipeline incurs less than 2.2\% utility loss.
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
Feb 24, 2026Agentic systems increasingly rely on reusable procedural capabilities, \textit{a.k.a., agentic skills}, to execute long-horizon workflows reliably. These capabilities are callable modules that package procedural knowledge with explicit applicability conditions, execution policies, termination criteria, and reusable interfaces. Unlike one-off plans or atomic tool calls, skills operate (and often do well) across tasks. This paper maps the skill layer across the full lifecycle (discovery, practice, distillation, storage, composition, evaluation, and update) and introduces two complementary taxonomies. The first is a system-level set of \textbf{seven design patterns} capturing how skills are packaged and executed in practice, from metadata-driven progressive disclosure and executable code skills to self-evolving libraries and marketplace distribution. The second is an orthogonal \textbf{representation $\times$ scope} taxonomy describing what skills \emph{are} (natural language, code, policy, hybrid) and what environments they operate over (web, OS, software engineering, robotics). We analyze the security and governance implications of skill-based agents, covering supply-chain risks, prompt injection via skill payloads, and trust-tiered execution, grounded by a case study of the ClawHavoc campaign in which nearly 1{,}200 malicious skills infiltrated a major agent marketplace, exfiltrating API keys, cryptocurrency wallets, and browser credentials at scale. We further survey deterministic evaluation approaches, anchored by recent benchmark evidence that curated skills can substantially improve agent success rates while self-generated skills may degrade them. We conclude with open challenges toward robust, verifiable, and certifiable skills for real-world autonomous agents.
CFLight: Enhancing Safety with Traffic Signal Control through Counterfactual Learning
Dec 16, 2025Traffic accidents result in millions of injuries and fatalities globally, with a significant number occurring at intersections each year. Traffic Signal Control (TSC) is an effective strategy for enhancing safety at these urban junctures. Despite the growing popularity of Reinforcement Learning (RL) methods in optimizing TSC, these methods often prioritize driving efficiency over safety, thus failing to address the critical balance between these two aspects. Additionally, these methods usually need more interpretability. CounterFactual (CF) learning is a promising approach for various causal analysis fields. In this study, we introduce a novel framework to improve RL for safety aspects in TSC. This framework introduces a novel method based on CF learning to address the question: ``What if, when an unsafe event occurs, we backtrack to perform alternative actions, and will this unsafe event still occur in the subsequent period?'' To answer this question, we propose a new structure causal model to predict the result after executing different actions, and we propose a new CF module that integrates with additional ``X'' modules to promote safe RL practices. Our new algorithm, CFLight, which is derived from this framework, effectively tackles challenging safety events and significantly improves safety at intersections through a near-zero collision control strategy. Through extensive numerical experiments on both real-world and synthetic datasets, we demonstrate that CFLight reduces collisions and improves overall traffic performance compared to conventional RL methods and the recent safe RL model. Moreover, our method represents a generalized and safe framework for RL methods, opening possibilities for applications in other domains. The data and code are available in the github https://github.com/AdvancedAI-ComplexSystem/SmartCity/tree/main/CFLight.
PoLO: Proof-of-Learning and Proof-of-Ownership at Once with Chained Watermarking
May 18, 2025Machine learning models are increasingly shared and outsourced, raising requirements of verifying training effort (Proof-of-Learning, PoL) to ensure claimed performance and establishing ownership (Proof-of-Ownership, PoO) for transactions. When models are trained by untrusted parties, PoL and PoO must be enforced together to enable protection, attribution, and compensation. However, existing studies typically address them separately, which not only weakens protection against forgery and privacy breaches but also leads to high verification overhead. We propose PoLO, a unified framework that simultaneously achieves PoL and PoO using chained watermarks. PoLO splits the training process into fine-grained training shards and embeds a dedicated watermark in each shard. Each watermark is generated using the hash of the preceding shard, certifying the training process of the preceding shard. The chained structure makes it computationally difficult to forge any individual part of the whole training process. The complete set of watermarks serves as the PoL, while the final watermark provides the PoO. PoLO offers more efficient and privacy-preserving verification compared to the vanilla PoL solutions that rely on gradient-based trajectory tracing and inadvertently expose training data during verification, while maintaining the same level of ownership assurance of watermark-based PoO schemes. Our evaluation shows that PoLO achieves 99% watermark detection accuracy for ownership verification, while preserving data privacy and cutting verification costs to just 1.5-10% of traditional methods. Forging PoLO demands 1.1-4x more resources than honest proof generation, with the original proof retaining over 90% detection accuracy even after attacks.
Fast High-Quality Enhanced Imaging Algorithm for Layered Dielectric Targets Based on MMW MIMO-SAR System
Nov 22, 2024Millimeter-wave (MMW) multiple-input multiple-output synthetic aperture radar (MIMO-SAR) system is a technology that can achieve high resolution, high frame rate, and all-weather imaging and has received extensive attention in the non-destructive testing and internal imaging applications of layered dielectric targets. However, the non-ideal scattering effect caused by dielectric materials can significantly deteriorate the imaging quality when using the existing MIMO-SAR fast algorithms. This paper proposes a rapid, high-quality dielectric target-enhanced imaging algorithm for a new universal non-uniform MIMO-SAR system. The algorithm builds on the existing non-uniform MIMO-SAR dielectric target frequency-domain algorithm (DT-FDA) by constructing a forward sensing operator and incorporating it into the alternating direction method of multipliers (ADMM) framework. This approach avoids large matrix operations while maintaining computational efficiency. By integrating an optimal regularization parameter search, the algorithm enhances the image reconstruction quality of dielectric internal structures or defects. Experimental results show the proposed algorithm outperforms IBP and DT-FDA, achieving better focusing, sidelobe suppression, and 3D imaging accuracy. It yields the lowest image entropy (8.864) and significantly improves efficiency (imaging time: 15.29 s vs. 23295.3 s for IBP).
ByCAN: Reverse Engineering Controller Area Network (CAN) Messages from Bit to Byte Level
Aug 17, 2024



As the primary standard protocol for modern cars, the Controller Area Network (CAN) is a critical research target for automotive cybersecurity threats and autonomous applications. As the decoding specification of CAN is a proprietary black-box maintained by Original Equipment Manufacturers (OEMs), conducting related research and industry developments can be challenging without a comprehensive understanding of the meaning of CAN messages. In this paper, we propose a fully automated reverse-engineering system, named ByCAN, to reverse engineer CAN messages. ByCAN outperforms existing research by introducing byte-level clusters and integrating multiple features at both byte and bit levels. ByCAN employs the clustering and template matching algorithms to automatically decode the specifications of CAN frames without the need for prior knowledge. Experimental results demonstrate that ByCAN achieves high accuracy in slicing and labeling performance, i.e., the identification of CAN signal boundaries and labels. In the experiments, ByCAN achieves slicing accuracy of 80.21%, slicing coverage of 95.21%, and labeling accuracy of 68.72% for general labels when analyzing the real-world CAN frames.
Fishers Harvest Parallel Unlearning in Inherited Model Networks
Aug 16, 2024

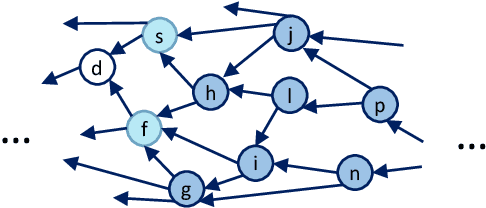

Unlearning in various learning frameworks remains challenging, with the continuous growth and updates of models exhibiting complex inheritance relationships. This paper presents a novel unlearning framework, which enables fully parallel unlearning among models exhibiting inheritance. A key enabler is the new Unified Model Inheritance Graph (UMIG), which captures the inheritance using a Directed Acyclic Graph (DAG).Central to our framework is the new Fisher Inheritance Unlearning (FIUn) algorithm, which utilizes the Fisher Information Matrix (FIM) from initial unlearning models to pinpoint impacted parameters in inherited models. By employing FIM, the FIUn method breaks the sequential dependencies among the models, facilitating simultaneous unlearning and reducing computational overhead. We further design to merge disparate FIMs into a single matrix, synchronizing updates across inherited models. Experiments confirm the effectiveness of our unlearning framework. For single-class tasks, it achieves complete unlearning with 0\% accuracy for unlearned labels while maintaining 94.53\% accuracy for retained labels on average. For multi-class tasks, the accuracy is 1.07\% for unlearned labels and 84.77\% for retained labels on average. Our framework accelerates unlearning by 99\% compared to alternative methods.
Is Your AI Truly Yours? Leveraging Blockchain for Copyrights, Provenance, and Lineage
Apr 09, 2024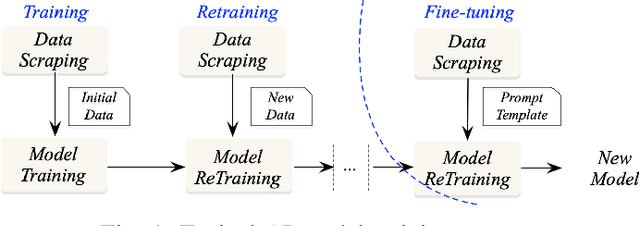

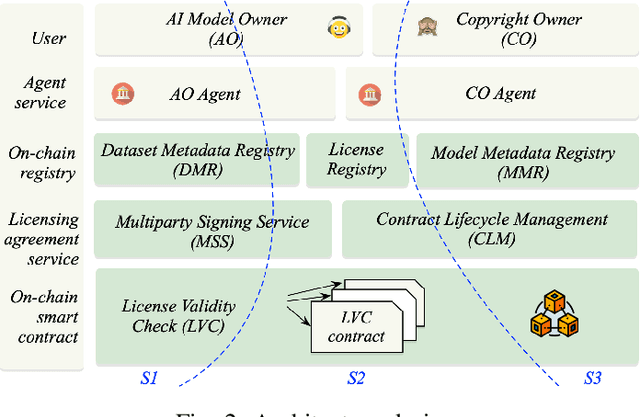
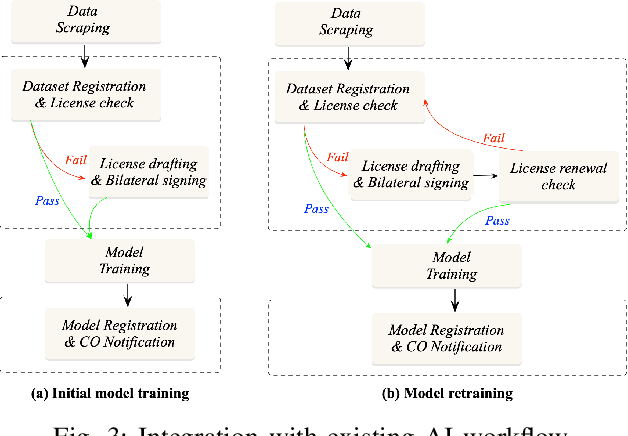
As Artificial Intelligence (AI) integrates into diverse areas, particularly in content generation, ensuring rightful ownership and ethical use becomes paramount. AI service providers are expected to prioritize responsibly sourcing training data and obtaining licenses from data owners. However, existing studies primarily center on safeguarding static copyrights, which simply treats metadata/datasets as non-fungible items with transferable/trading capabilities, neglecting the dynamic nature of training procedures that can shape an ongoing trajectory. In this paper, we present \textsc{IBis}, a blockchain-based framework tailored for AI model training workflows. \textsc{IBis} integrates on-chain registries for datasets, licenses and models, alongside off-chain signing services to facilitate collaboration among multiple participants. Our framework addresses concerns regarding data and model provenance and copyright compliance. \textsc{IBis} enables iterative model retraining and fine-tuning, and offers flexible license checks and renewals. Further, \textsc{IBis} provides APIs designed for seamless integration with existing contract management software, minimizing disruptions to established model training processes. We implement \textsc{IBis} using Daml on the Canton blockchain. Evaluation results showcase the feasibility and scalability of \textsc{IBis} across varying numbers of users, datasets, models, and licenses.
Decentralized Federated Unlearning on Blockchain
Feb 26, 2024



Blockchained Federated Learning (FL) has been gaining traction for ensuring the integrity and traceability of FL processes. Blockchained FL involves participants training models locally with their data and subsequently publishing the models on the blockchain, forming a Directed Acyclic Graph (DAG)-like inheritance structure that represents the model relationship. However, this particular DAG-based structure presents challenges in updating models with sensitive data, due to the complexity and overhead involved. To address this, we propose Blockchained Federated Unlearning (BlockFUL), a generic framework that redesigns the blockchain structure using Chameleon Hash (CH) technology to mitigate the complexity of model updating, thereby reducing the computational and consensus costs of unlearning tasks.Furthermore, BlockFUL supports various federated unlearning methods, ensuring the integrity and traceability of model updates, whether conducted in parallel or serial. We conduct a comprehensive study of two typical unlearning methods, gradient ascent and re-training, demonstrating the efficient unlearning workflow in these two categories with minimal CH and block update operations. Additionally, we compare the computation and communication costs of these methods.