 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoe for Fraud: Transferable Adversarial Attacks in Credit Card Fraud Detection
Aug 20, 2025Credit card fraud detection (CCFD) is a critical application of Machine Learning (ML) in the financial sector, where accurately identifying fraudulent transactions is essential for mitigating financial losses. ML models have demonstrated their effectiveness in fraud detection task, in particular with the tabular dataset. While adversarial attacks have been extensively studied in computer vision and deep learning, their impacts on the ML models, particularly those trained on CCFD tabular datasets, remains largely unexplored. These latent vulnerabilities pose significant threats to the security and stability of the financial industry, especially in high-value transactions where losses could be substantial. To address this gap, in this paper, we present a holistic framework that investigate the robustness of CCFD ML model against adversarial perturbations under different circumstances. Specifically, the gradient-based attack methods are incorporated into the tabular credit card transaction data in both black- and white-box adversarial attacks settings. Our findings confirm that tabular data is also susceptible to subtle perturbations, highlighting the need for heightened awareness among financial technology practitioners regarding ML model security and trustworthiness. Furthermore, the experiments by transferring adversarial samples from gradient-based attack method to non-gradient-based models also verify our findings. Our results demonstrate that such attacks remain effective, emphasizing the necessity of developing robust defenses for CCFD algorithms.
Efficient Neural Network Verification via Order Leading Exploration of Branch-and-Bound Trees
Jul 23, 2025The vulnerability of neural networks to adversarial perturbations has necessitated formal verification techniques that can rigorously certify the quality of neural networks. As the state-of-the-art, branch and bound (BaB) is a "divide-and-conquer" strategy that applies off-the-shelf verifiers to sub-problems for which they perform better. While BaB can identify the sub-problems that are necessary to be split, it explores the space of these sub-problems in a naive "first-come-first-serve" manner, thereby suffering from an issue of inefficiency to reach a verification conclusion. To bridge this gap, we introduce an order over different sub-problems produced by BaB, concerning with their different likelihoods of containing counterexamples. Based on this order, we propose a novel verification framework Oliva that explores the sub-problem space by prioritizing those sub-problems that are more likely to find counterexamples, in order to efficiently reach the conclusion of the verification. Even if no counterexample can be found in any sub-problem, it only changes the order of visiting different sub-problem and so will not lead to a performance degradation. Specifically, Oliva has two variants, including $Oliva^{GR}$, a greedy strategy that always prioritizes the sub-problems that are more likely to find counterexamples, and $Oliva^{SA}$, a balanced strategy inspired by simulated annealing that gradually shifts from exploration to exploitation to locate the globally optimal sub-problems. We experimentally evaluate the performance of Oliva on 690 verification problems spanning over 5 models with datasets MNIST and CIFAR10. Compared to the state-of-the-art approaches, we demonstrate the speedup of Oliva for up to 25X in MNIST, and up to 80X in CIFAR10.
FedSKC: Federated Learning with Non-IID Data via Structural Knowledge Collaboration
May 25, 2025With the advancement of edge computing, federated learning (FL) displays a bright promise as a privacy-preserving collaborative learning paradigm. However, one major challenge for FL is the data heterogeneity issue, which refers to the biased labeling preferences among multiple clients, negatively impacting convergence and model performance. Most previous FL methods attempt to tackle the data heterogeneity issue locally or globally, neglecting underlying class-wise structure information contained in each client. In this paper, we first study how data heterogeneity affects the divergence of the model and decompose it into local, global, and sampling drift sub-problems. To explore the potential of using intra-client class-wise structural knowledge in handling these drifts, we thus propose Federated Learning with Structural Knowledge Collaboration (FedSKC). The key idea of FedSKC is to extract and transfer domain preferences from inter-client data distributions, offering diverse class-relevant knowledge and a fair convergent signal. FedSKC comprises three components: i) local contrastive learning, to prevent weight divergence resulting from local training; ii) global discrepancy aggregation, which addresses the parameter deviation between the server and clients; iii) global period review, correcting for the sampling drift introduced by the server randomly selecting devices. We have theoretically analyzed FedSKC under non-convex objectives and empirically validated its superiority through extensive experimental results.
Logic Meets Magic: LLMs Cracking Smart Contract Vulnerabilities
Jan 13, 2025



Smart contract vulnerabilities caused significant economic losses in blockchain applications. Large Language Models (LLMs) provide new possibilities for addressing this time-consuming task. However, state-of-the-art LLM-based detection solutions are often plagued by high false-positive rates. In this paper, we push the boundaries of existing research in two key ways. First, our evaluation is based on Solidity v0.8, offering the most up-to-date insights compared to prior studies that focus on older versions (v0.4). Second, we leverage the latest five LLM models (across companies), ensuring comprehensive coverage across the most advanced capabilities in the field. We conducted a series of rigorous evaluations. Our experiments demonstrate that a well-designed prompt can reduce the false-positive rate by over 60%. Surprisingly, we also discovered that the recall rate for detecting some specific vulnerabilities in Solidity v0.8 has dropped to just 13% compared to earlier versions (i.e., v0.4). Further analysis reveals the root cause of this decline: the reliance of LLMs on identifying changes in newly introduced libraries and frameworks during detection.
Is Your AI Truly Yours? Leveraging Blockchain for Copyrights, Provenance, and Lineage
Apr 09, 2024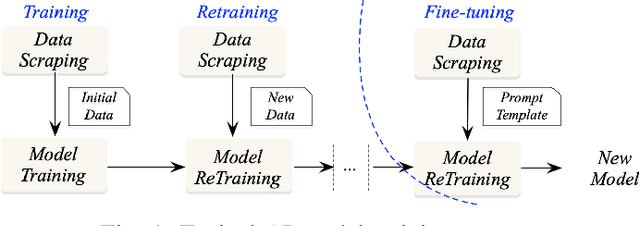

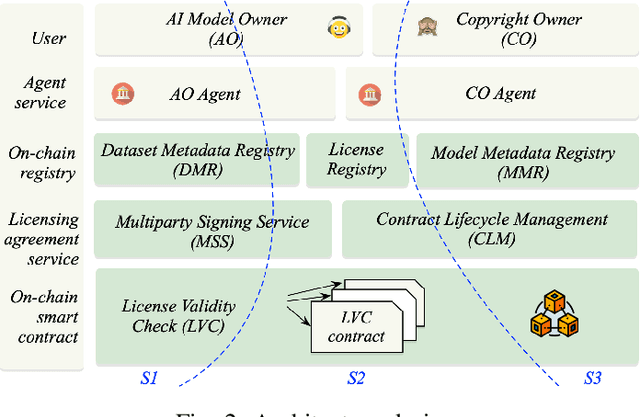
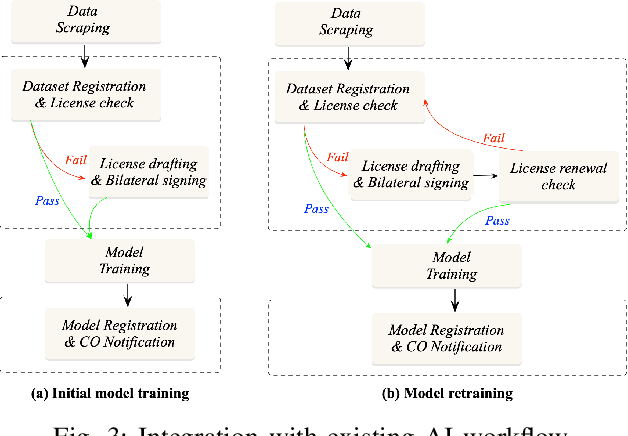
As Artificial Intelligence (AI) integrates into diverse areas, particularly in content generation, ensuring rightful ownership and ethical use becomes paramount. AI service providers are expected to prioritize responsibly sourcing training data and obtaining licenses from data owners. However, existing studies primarily center on safeguarding static copyrights, which simply treats metadata/datasets as non-fungible items with transferable/trading capabilities, neglecting the dynamic nature of training procedures that can shape an ongoing trajectory. In this paper, we present \textsc{IBis}, a blockchain-based framework tailored for AI model training workflows. \textsc{IBis} integrates on-chain registries for datasets, licenses and models, alongside off-chain signing services to facilitate collaboration among multiple participants. Our framework addresses concerns regarding data and model provenance and copyright compliance. \textsc{IBis} enables iterative model retraining and fine-tuning, and offers flexible license checks and renewals. Further, \textsc{IBis} provides APIs designed for seamless integration with existing contract management software, minimizing disruptions to established model training processes. We implement \textsc{IBis} using Daml on the Canton blockchain. Evaluation results showcase the feasibility and scalability of \textsc{IBis} across varying numbers of users, datasets, models, and licenses.
Blockchain-Empowered Trustworthy Data Sharing: Fundamentals, Applications, and Challenges
Mar 12, 2023
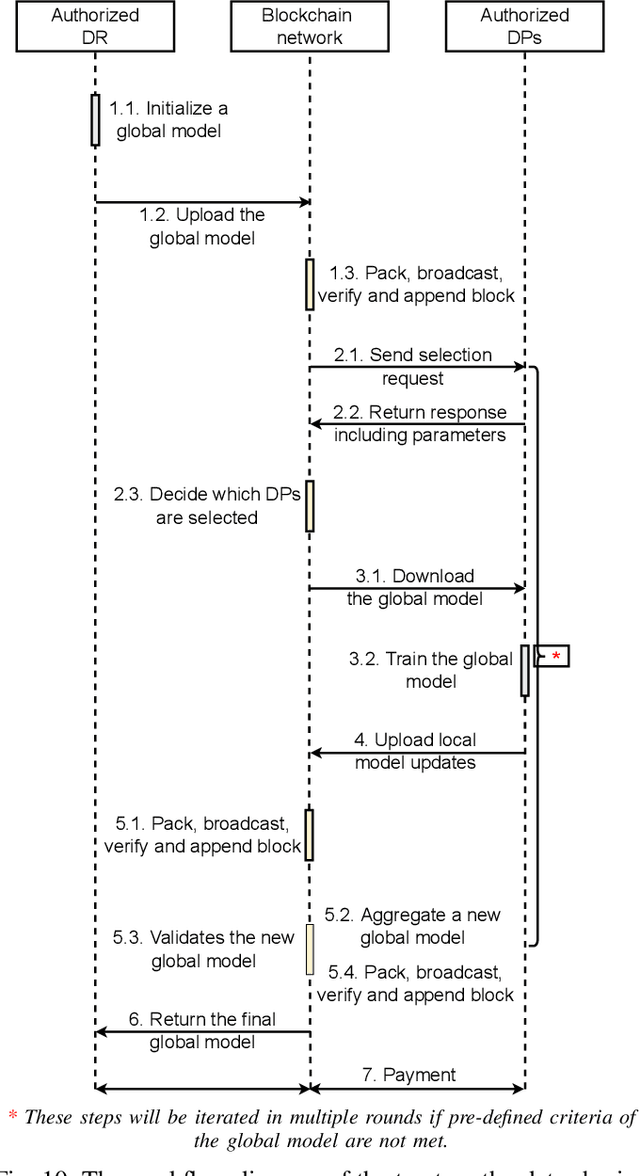
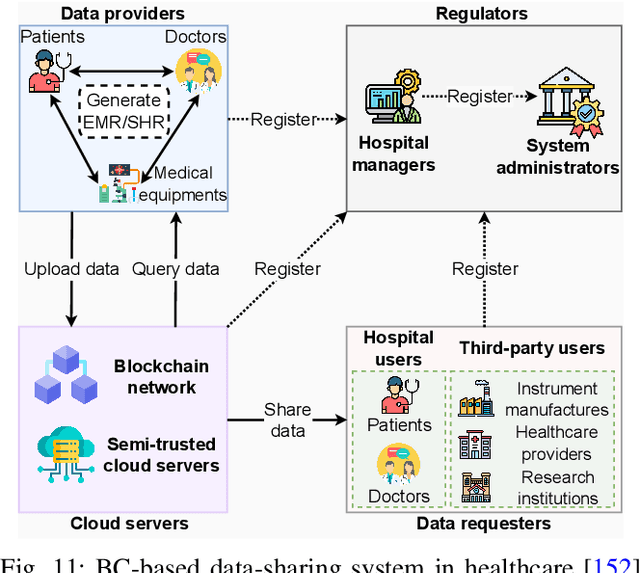

Various data-sharing platforms have emerged with the growing public demand for open data and legislation mandating certain data to remain open. Most of these platforms remain opaque, leading to many questions about data accuracy, provenance and lineage, privacy implications, consent management, and the lack of fair incentives for data providers. With their transparency, immutability, non-repudiation, and decentralization properties, blockchains could not be more apt to answer these questions and enhance trust in a data-sharing platform. However, blockchains are not good at handling the four Vs of big data (i.e., volume, variety, velocity, and veracity) due to their limited performance, scalability, and high cost. Given many related works proposes blockchain-based trustworthy data-sharing solutions, there is increasing confusion and difficulties in understanding and selecting these technologies and platforms in terms of their sharing mechanisms, sharing services, quality of services, and applications. In this paper, we conduct a comprehensive survey on blockchain-based data-sharing architectures and applications to fill the gap. First, we present the foundations of blockchains and discuss the challenges of current data-sharing techniques. Second, we focus on the convergence of blockchain and data sharing to give a clear picture of this landscape and propose a reference architecture for blockchain-based data sharing. Third, we discuss the industrial applications of blockchain-based data sharing, ranging from healthcare and smart grid to transportation and decarbonization. For each application, we provide lessons learned for the deployment of Blockchain-based data sharing. Finally, we discuss research challenges and open research directions.
A Tale of Two Cities: Data and Configuration Variances in Robust Deep Learning
Nov 25, 2022Deep neural networks (DNNs), are widely used in many industries such as image recognition, supply chain, medical diagnosis, and autonomous driving. However, prior work has shown the high accuracy of a DNN model does not imply high robustness (i.e., consistent performances on new and future datasets) because the input data and external environment (e.g., software and model configurations) for a deployed model are constantly changing. Hence, ensuring the robustness of deep learning is not an option but a priority to enhance business and consumer confidence. Previous studies mostly focus on the data aspect of model variance. In this article, we systematically summarize DNN robustness issues and formulate them in a holistic view through two important aspects, i.e., data and software configuration variances in DNNs. We also provide a predictive framework to generate representative variances (counterexamples) by considering both data and configurations for robust learning through the lens of search-based optimization.