 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Neural Network Verification via Order Leading Exploration of Branch-and-Bound Trees
Jul 23, 2025The vulnerability of neural networks to adversarial perturbations has necessitated formal verification techniques that can rigorously certify the quality of neural networks. As the state-of-the-art, branch and bound (BaB) is a "divide-and-conquer" strategy that applies off-the-shelf verifiers to sub-problems for which they perform better. While BaB can identify the sub-problems that are necessary to be split, it explores the space of these sub-problems in a naive "first-come-first-serve" manner, thereby suffering from an issue of inefficiency to reach a verification conclusion. To bridge this gap, we introduce an order over different sub-problems produced by BaB, concerning with their different likelihoods of containing counterexamples. Based on this order, we propose a novel verification framework Oliva that explores the sub-problem space by prioritizing those sub-problems that are more likely to find counterexamples, in order to efficiently reach the conclusion of the verification. Even if no counterexample can be found in any sub-problem, it only changes the order of visiting different sub-problem and so will not lead to a performance degradation. Specifically, Oliva has two variants, including $Oliva^{GR}$, a greedy strategy that always prioritizes the sub-problems that are more likely to find counterexamples, and $Oliva^{SA}$, a balanced strategy inspired by simulated annealing that gradually shifts from exploration to exploitation to locate the globally optimal sub-problems. We experimentally evaluate the performance of Oliva on 690 verification problems spanning over 5 models with datasets MNIST and CIFAR10. Compared to the state-of-the-art approaches, we demonstrate the speedup of Oliva for up to 25X in MNIST, and up to 80X in CIFAR10.
Is Your AI Truly Yours? Leveraging Blockchain for Copyrights, Provenance, and Lineage
Apr 09, 2024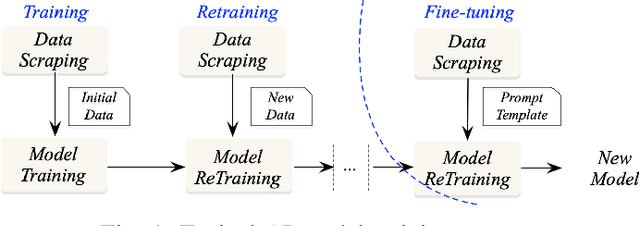

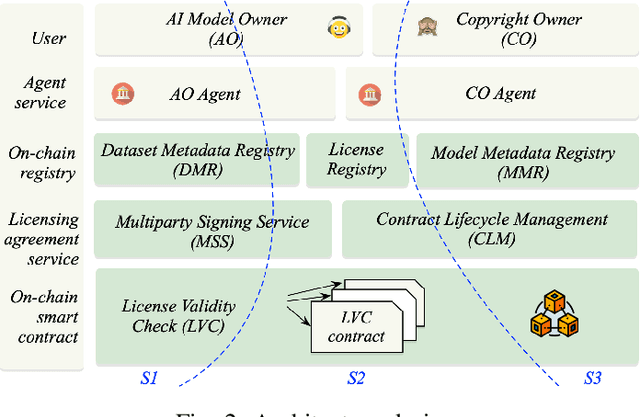
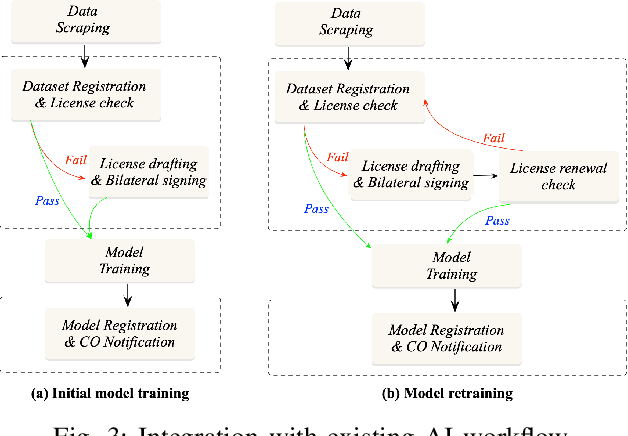
As Artificial Intelligence (AI) integrates into diverse areas, particularly in content generation, ensuring rightful ownership and ethical use becomes paramount. AI service providers are expected to prioritize responsibly sourcing training data and obtaining licenses from data owners. However, existing studies primarily center on safeguarding static copyrights, which simply treats metadata/datasets as non-fungible items with transferable/trading capabilities, neglecting the dynamic nature of training procedures that can shape an ongoing trajectory. In this paper, we present \textsc{IBis}, a blockchain-based framework tailored for AI model training workflows. \textsc{IBis} integrates on-chain registries for datasets, licenses and models, alongside off-chain signing services to facilitate collaboration among multiple participants. Our framework addresses concerns regarding data and model provenance and copyright compliance. \textsc{IBis} enables iterative model retraining and fine-tuning, and offers flexible license checks and renewals. Further, \textsc{IBis} provides APIs designed for seamless integration with existing contract management software, minimizing disruptions to established model training processes. We implement \textsc{IBis} using Daml on the Canton blockchain. Evaluation results showcase the feasibility and scalability of \textsc{IBis} across varying numbers of users, datasets, models, and licenses.
A Tale of Two Cities: Data and Configuration Variances in Robust Deep Learning
Nov 25, 2022Deep neural networks (DNNs), are widely used in many industries such as image recognition, supply chain, medical diagnosis, and autonomous driving. However, prior work has shown the high accuracy of a DNN model does not imply high robustness (i.e., consistent performances on new and future datasets) because the input data and external environment (e.g., software and model configurations) for a deployed model are constantly changing. Hence, ensuring the robustness of deep learning is not an option but a priority to enhance business and consumer confidence. Previous studies mostly focus on the data aspect of model variance. In this article, we systematically summarize DNN robustness issues and formulate them in a holistic view through two important aspects, i.e., data and software configuration variances in DNNs. We also provide a predictive framework to generate representative variances (counterexamples) by considering both data and configurations for robust learning through the lens of search-based optimization.