 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartOracle - An Agentic Approach to Mitigate Noise in Differential Oracles
Jan 21, 2026Differential fuzzers detect bugs by executing identical inputs across distinct implementations of the same specification, such as JavaScript interpreters. Validating the outputs requires an oracle and for differential testing of JavaScript, these are constructed manually, making them expensive, time-consuming, and prone to false positives. Worse, when the specification evolves, this manual effort must be repeated. Inspired by the success of agentic systems in other SE domains, this paper introduces SmartOracle. SmartOracle decomposes the manual triage workflow into specialized Large Language Model (LLM) sub-agents. These agents synthesize independently gathered evidence from terminal runs and targeted specification queries to reach a final verdict. For historical benchmarks, SmartOracle achieves 0.84 recall with an 18% false positive rate. Compared to a sequential Gemini 2.5 Pro baseline, it improves triage accuracy while reducing analysis time by 4$\times$ and API costs by 10$\times$. In active fuzzing campaigns, SmartOracle successfully identified and reported previously unknown specification-level issues across major engines, including bugs in V8, JavaScriptCore, and GraalJS. The success of SmartOracle's agentic architecture on Javascript suggests it might be useful other software systems- a research direction we will explore in future work.
From Coverage to Causes: Data-Centric Fuzzing for JavaScript Engines
Dec 19, 2025Context: Exhaustive fuzzing of modern JavaScript engines is infeasible due to the vast number of program states and execution paths. Coverage-guided fuzzers waste effort on low-risk inputs, often ignoring vulnerability-triggering ones that do not increase coverage. Existing heuristics proposed to mitigate this require expert effort, are brittle, and hard to adapt. Objective: We propose a data-centric, LLM-boosted alternative that learns from historical vulnerabilities to automatically identify minimal static (code) and dynamic (runtime) features for detecting high-risk inputs. Method: Guided by historical V8 bugs, iterative prompting generated 115 static and 49 dynamic features, with the latter requiring only five trace flags, minimizing instrumentation cost. After feature selection, 41 features remained to train an XGBoost model to predict high-risk inputs during fuzzing. Results: Combining static and dynamic features yields over 85% precision and under 1% false alarms. Only 25% of these features are needed for comparable performance, showing that most of the search space is irrelevant. Conclusion: This work introduces feature-guided fuzzing, an automated data-driven approach that replaces coverage with data-directed inference, guiding fuzzers toward high-risk states for faster, targeted, and reproducible vulnerability discovery. To support open science, all scripts and data are available at https://github.com/KKGanguly/DataCentricFuzzJS .
Whence Is A Model Fair? Fixing Fairness Bugs via Propensity Score Matching
Apr 23, 2025


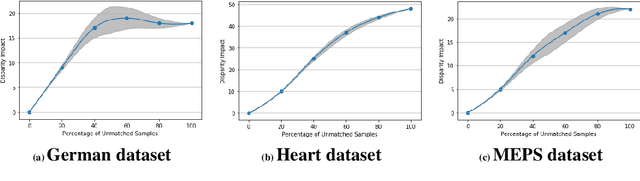
Fairness-aware learning aims to mitigate discrimination against specific protected social groups (e.g., those categorized by gender, ethnicity, age) while minimizing predictive performance loss. Despite efforts to improve fairness in machine learning, prior studies have shown that many models remain unfair when measured against various fairness metrics. In this paper, we examine whether the way training and testing data are sampled affects the reliability of reported fairness metrics. Since training and test sets are often randomly sampled from the same population, bias present in the training data may still exist in the test data, potentially skewing fairness assessments. To address this, we propose FairMatch, a post-processing method that applies propensity score matching to evaluate and mitigate bias. FairMatch identifies control and treatment pairs with similar propensity scores in the test set and adjusts decision thresholds for different subgroups accordingly. For samples that cannot be matched, we perform probabilistic calibration using fairness-aware loss functions. Experimental results demonstrate that our approach can (a) precisely locate subsets of the test data where the model is unbiased, and (b) significantly reduce bias on the remaining data. Overall, propensity score matching offers a principled way to improve both fairness evaluation and mitigation, without sacrificing predictive performance.
Software Engineering Principles for Fairer Systems: Experiments with GroupCART
Apr 17, 2025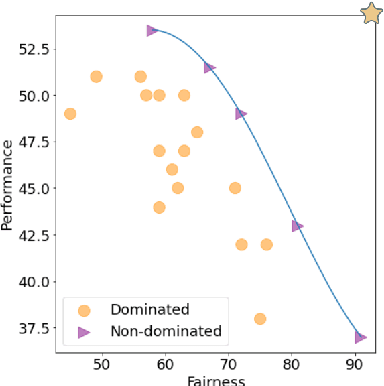

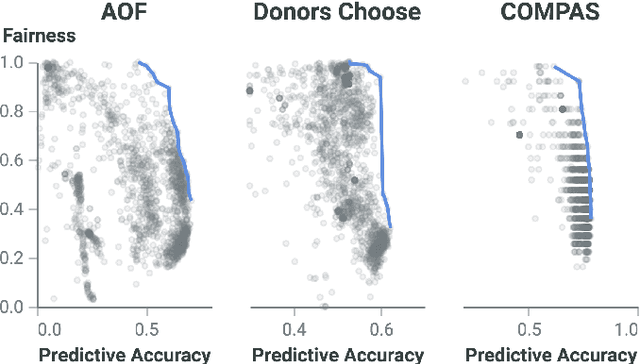

Discrimination-aware classification aims to make accurate predictions while satisfying fairness constraints. Traditional decision tree learners typically optimize for information gain in the target attribute alone, which can result in models that unfairly discriminate against protected social groups (e.g., gender, ethnicity). Motivated by these shortcomings, we propose GroupCART, a tree-based ensemble optimizer that avoids bias during model construction by optimizing not only for decreased entropy in the target attribute but also for increased entropy in protected attributes. Our experiments show that GroupCART achieves fairer models without data transformation and with minimal performance degradation. Furthermore, the method supports customizable weighting, offering a smooth and flexible trade-off between predictive performance and fairness based on user requirements. These results demonstrate that algorithmic bias in decision tree models can be mitigated through multi-task, fairness-aware learning. All code and datasets used in this study are available at: https://github.com/anonymous12138/groupCART.
SMOOTHIE: A Theory of Hyper-parameter Optimization for Software Analytics
Jan 17, 2024Hyper-parameter optimization is the black art of tuning a learner's control parameters. In software analytics, a repeated result is that such tuning can result in dramatic performance improvements. Despite this, hyper-parameter optimization is often applied rarely or poorly in software analytics--perhaps due to the CPU cost of exploring all those parameter options can be prohibitive. We theorize that learners generalize better when the loss landscape is ``smooth''. This theory is useful since the influence on ``smoothness'' of different hyper-parameter choices can be tested very quickly (e.g. for a deep learner, after just one epoch). To test this theory, this paper implements and tests SMOOTHIE, a novel hyper-parameter optimizer that guides its optimizations via considerations of ``smothness''. The experiments of this paper test SMOOTHIE on numerous SE tasks including (a) GitHub issue lifetime prediction; (b) detecting false alarms in static code warnings; (c) defect prediction, and (d) a set of standard ML datasets. In all these experiments, SMOOTHIE out-performed state-of-the-art optimizers. Better yet, SMOOTHIE ran 300% faster than the prior state-of-the art. We hence conclude that this theory (that hyper-parameter optimization is best viewed as a ``smoothing'' function for the decision landscape), is both theoretically interesting and practically very useful. To support open science and other researchers working in this area, all our scripts and datasets are available on-line at https://github.com/yrahul3910/smoothness-hpo/.
Mining Temporal Attack Patterns from Cyberthreat Intelligence Reports
Jan 03, 2024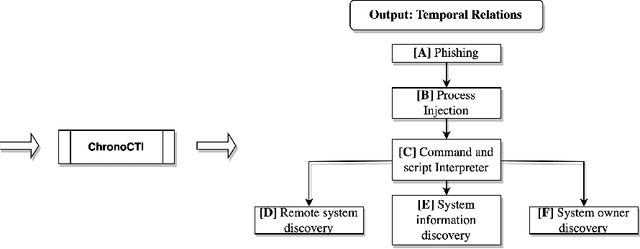

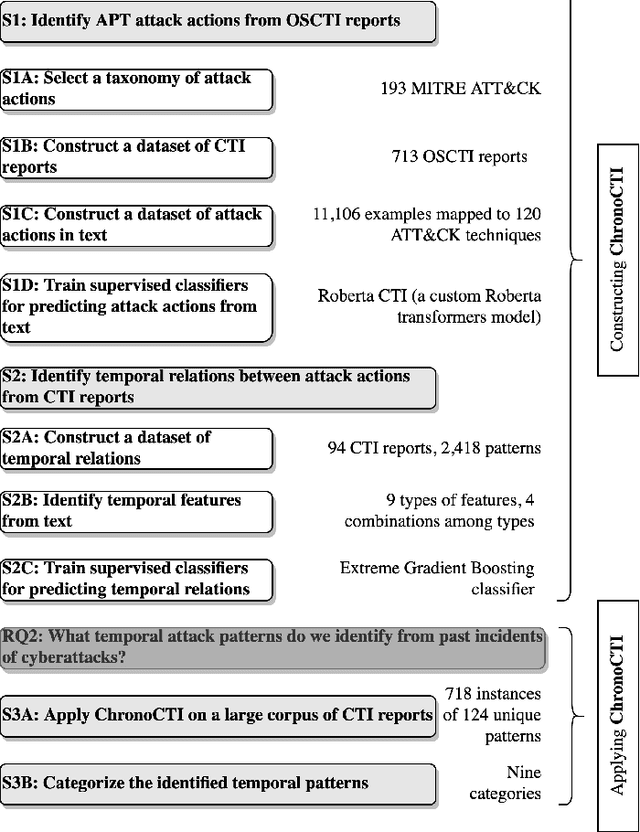
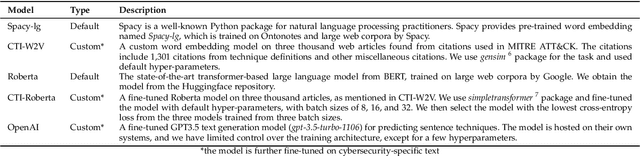
Defending from cyberattacks requires practitioners to operate on high-level adversary behavior. Cyberthreat intelligence (CTI) reports on past cyberattack incidents describe the chain of malicious actions with respect to time. To avoid repeating cyberattack incidents, practitioners must proactively identify and defend against recurring chain of actions - which we refer to as temporal attack patterns. Automatically mining the patterns among actions provides structured and actionable information on the adversary behavior of past cyberattacks. The goal of this paper is to aid security practitioners in prioritizing and proactive defense against cyberattacks by mining temporal attack patterns from cyberthreat intelligence reports. To this end, we propose ChronoCTI, an automated pipeline for mining temporal attack patterns from cyberthreat intelligence (CTI) reports of past cyberattacks. To construct ChronoCTI, we build the ground truth dataset of temporal attack patterns and apply state-of-the-art large language models, natural language processing, and machine learning techniques. We apply ChronoCTI on a set of 713 CTI reports, where we identify 124 temporal attack patterns - which we categorize into nine pattern categories. We identify that the most prevalent pattern category is to trick victim users into executing malicious code to initiate the attack, followed by bypassing the anti-malware system in the victim network. Based on the observed patterns, we advocate organizations to train users about cybersecurity best practices, introduce immutable operating systems with limited functionalities, and enforce multi-user authentications. Moreover, we advocate practitioners to leverage the automated mining capability of ChronoCTI and design countermeasures against the recurring attack patterns.
Less, but Stronger: On the Value of Strong Heuristics in Semi-supervised Learning for Software Analytics
Feb 03, 2023



In many domains, there are many examples and far fewer labels for those examples; e.g. we may have access to millions of lines of source code, but access to only a handful of warnings about that code. In those domains, semi-supervised learners (SSL) can extrapolate labels from a small number of examples to the rest of the data. Standard SSL algorithms use ``weak'' knowledge (i.e. those not based on specific SE knowledge) such as (e.g.) co-train two learners and use good labels from one to train the other. Another approach of SSL in software analytics is potentially use ``strong'' knowledge that use SE knowledge. For example, an often-used heuristic in SE is that unusually large artifacts contain undesired properties (e.g. more bugs). This paper argues that such ``strong'' algorithms perform better than those standard, weaker, SSL algorithms. We show this by learning models from labels generated using weak SSL or our ``stronger'' FRUGAL algorithm. In four domains (distinguishing security-related bug reports; mitigating bias in decision-making; predicting issue close time; and (reducing false alarms in static code warnings), FRUGAL required only 2.5% of the data to be labeled yet out-performed standard semi-supervised learners that relied on (e.g.) some domain-independent graph theory concepts. Hence, for future work, we strongly recommend the use of strong heuristics for semi-supervised learning for SE applications. To better support other researchers, our scripts and data are on-line at https://github.com/HuyTu7/FRUGAL.
Don't Lie to Me: Avoiding Malicious Explanations with STEALTH
Jan 25, 2023
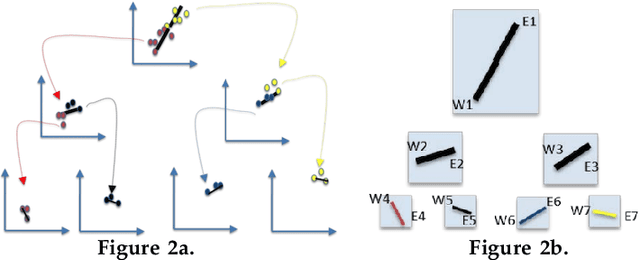

STEALTH is a method for using some AI-generated model, without suffering from malicious attacks (i.e. lying) or associated unfairness issues. After recursively bi-clustering the data, STEALTH system asks the AI model a limited number of queries about class labels. STEALTH asks so few queries (1 per data cluster) that malicious algorithms (a) cannot detect its operation, nor (b) know when to lie.
Optimizing Predictions for Very Small Data Sets: a case study on Open-Source Project Health Prediction
Jan 16, 2023



When learning from very small data sets, the resulting models can make many mistakes. For example, consider learning predictors for open source project health. The training data for this task may be very small (e.g. five years of data, collected every month means just 60 rows of training data). Using this data, prior work had unacceptably large errors in their learned predictors. We show that these high errors rates can be tamed by better configuration of the control parameters of the machine learners. For example, we present here a {\em landscape analytics} method (called SNEAK) that (a)~clusters the data to find the general landscape of the hyperparameters; then (b)~explores a few representatives from each part of that landscape. SNEAK is both faster and and more effective than prior state-of-the-art hyperparameter optimization algorithms (FLASH, HYPEROPT, OPTUNA, and differential evolution). More importantly, the configurations found by SNEAK had far less error that other methods. We conjecture that SNEAK works so well since it finds the most informative regions of the hyperparameters, then jumps to those regions. Other methods (that do not reflect over the landscape) can waste time exploring less informative options. From this, we make the following conclusions. Firstly, for predicting open source project health, we recommend landscape analytics (e.g.SNEAK). Secondly, and more generally, when learning from very small data sets, using hyperparameter optimization (e.g. SNEAK) to select learning control parameters. Due to its speed and implementation simplicity, we suggest SNEAK might also be useful in other ``data-light'' SE domains. To assist other researchers in repeating, improving, or even refuting our results, all our scripts and data are available on GitHub at https://github.com/zxcv123456qwe/niSneak
A Tale of Two Cities: Data and Configuration Variances in Robust Deep Learning
Nov 25, 2022Deep neural networks (DNNs), are widely used in many industries such as image recognition, supply chain, medical diagnosis, and autonomous driving. However, prior work has shown the high accuracy of a DNN model does not imply high robustness (i.e., consistent performances on new and future datasets) because the input data and external environment (e.g., software and model configurations) for a deployed model are constantly changing. Hence, ensuring the robustness of deep learning is not an option but a priority to enhance business and consumer confidence. Previous studies mostly focus on the data aspect of model variance. In this article, we systematically summarize DNN robustness issues and formulate them in a holistic view through two important aspects, i.e., data and software configuration variances in DNNs. We also provide a predictive framework to generate representative variances (counterexamples) by considering both data and configurations for robust learning through the lens of search-based optimization.