 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFALCON: Autonomous Cyber Threat Intelligence Mining with LLMs for IDS Rule Generation
Aug 26, 2025Signature-based Intrusion Detection Systems (IDS) detect malicious activities by matching network or host activity against predefined rules. These rules are derived from extensive Cyber Threat Intelligence (CTI), which includes attack signatures and behavioral patterns obtained through automated tools and manual threat analysis, such as sandboxing. The CTI is then transformed into actionable rules for the IDS engine, enabling real-time detection and prevention. However, the constant evolution of cyber threats necessitates frequent rule updates, which delay deployment time and weaken overall security readiness. Recent advancements in agentic systems powered by Large Language Models (LLMs) offer the potential for autonomous IDS rule generation with internal evaluation. We introduce FALCON, an autonomous agentic framework that generates deployable IDS rules from CTI data in real-time and evaluates them using built-in multi-phased validators. To demonstrate versatility, we target both network (Snort) and host-based (YARA) mediums and construct a comprehensive dataset of IDS rules with their corresponding CTIs. Our evaluations indicate FALCON excels in automatic rule generation, with an average of 95% accuracy validated by qualitative evaluation with 84% inter-rater agreement among multiple cybersecurity analysts across all metrics. These results underscore the feasibility and effectiveness of LLM-driven data mining for real-time cyber threat mitigation.
Mining Temporal Attack Patterns from Cyberthreat Intelligence Reports
Jan 03, 2024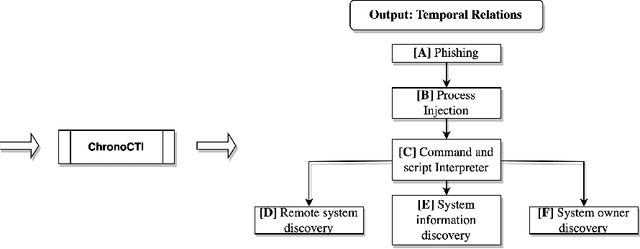

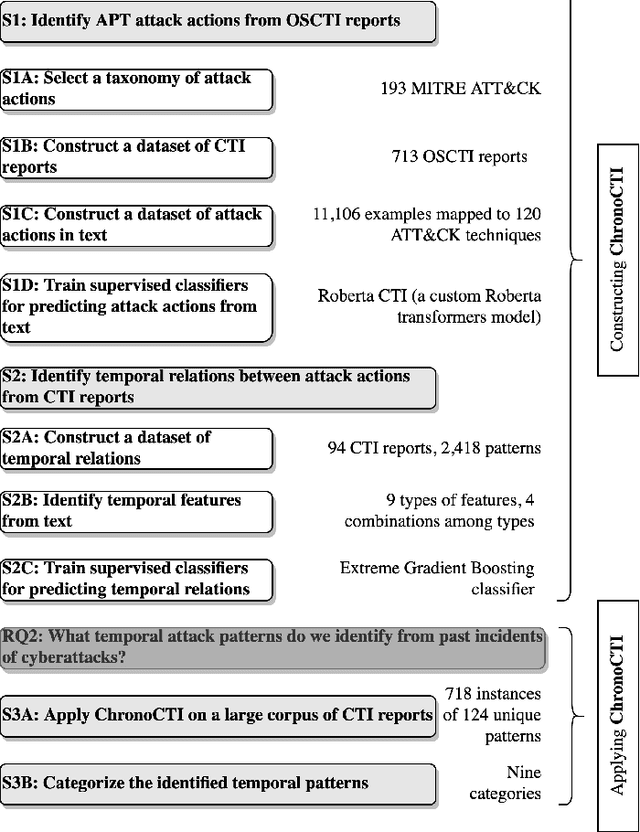
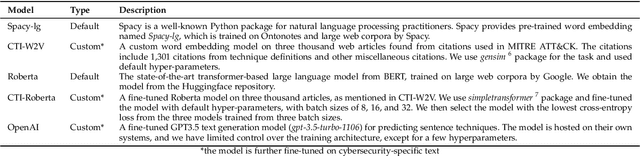
Defending from cyberattacks requires practitioners to operate on high-level adversary behavior. Cyberthreat intelligence (CTI) reports on past cyberattack incidents describe the chain of malicious actions with respect to time. To avoid repeating cyberattack incidents, practitioners must proactively identify and defend against recurring chain of actions - which we refer to as temporal attack patterns. Automatically mining the patterns among actions provides structured and actionable information on the adversary behavior of past cyberattacks. The goal of this paper is to aid security practitioners in prioritizing and proactive defense against cyberattacks by mining temporal attack patterns from cyberthreat intelligence reports. To this end, we propose ChronoCTI, an automated pipeline for mining temporal attack patterns from cyberthreat intelligence (CTI) reports of past cyberattacks. To construct ChronoCTI, we build the ground truth dataset of temporal attack patterns and apply state-of-the-art large language models, natural language processing, and machine learning techniques. We apply ChronoCTI on a set of 713 CTI reports, where we identify 124 temporal attack patterns - which we categorize into nine pattern categories. We identify that the most prevalent pattern category is to trick victim users into executing malicious code to initiate the attack, followed by bypassing the anti-malware system in the victim network. Based on the observed patterns, we advocate organizations to train users about cybersecurity best practices, introduce immutable operating systems with limited functionalities, and enforce multi-user authentications. Moreover, we advocate practitioners to leverage the automated mining capability of ChronoCTI and design countermeasures against the recurring attack patterns.
From Threat Reports to Continuous Threat Intelligence: A Comparison of Attack Technique Extraction Methods from Textual Artifacts
Oct 05, 2022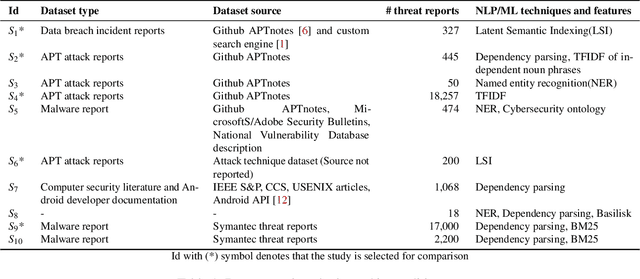
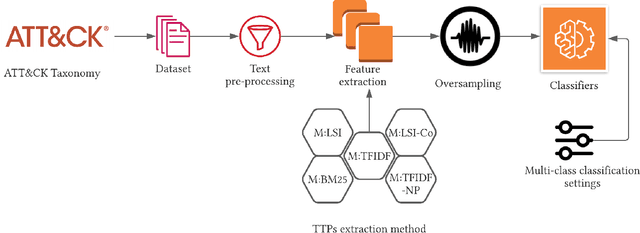
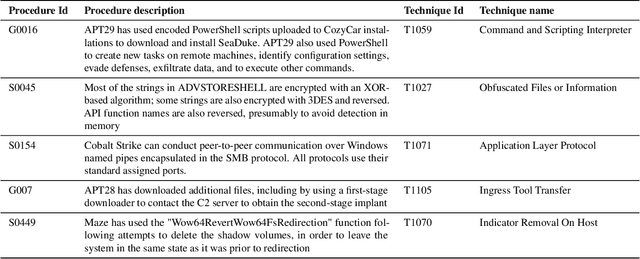
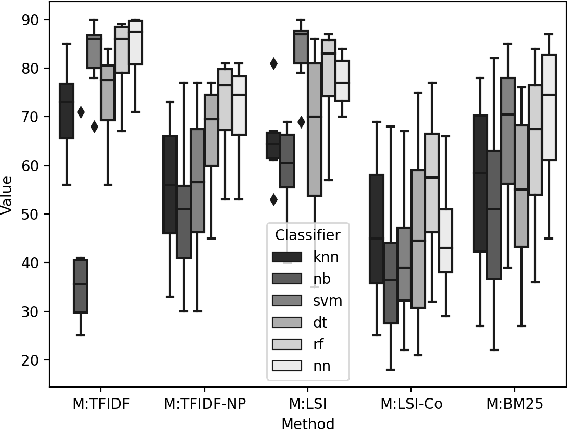
The cyberthreat landscape is continuously evolving. Hence, continuous monitoring and sharing of threat intelligence have become a priority for organizations. Threat reports, published by cybersecurity vendors, contain detailed descriptions of attack Tactics, Techniques, and Procedures (TTP) written in an unstructured text format. Extracting TTP from these reports aids cybersecurity practitioners and researchers learn and adapt to evolving attacks and in planning threat mitigation. Researchers have proposed TTP extraction methods in the literature, however, not all of these proposed methods are compared to one another or to a baseline. \textit{The goal of this study is to aid cybersecurity researchers and practitioners choose attack technique extraction methods for monitoring and sharing threat intelligence by comparing the underlying methods from the TTP extraction studies in the literature.} In this work, we identify ten existing TTP extraction studies from the literature and implement five methods from the ten studies. We find two methods, based on Term Frequency-Inverse Document Frequency(TFIDF) and Latent Semantic Indexing (LSI), outperform the other three methods with a F1 score of 84\% and 83\%, respectively. We observe the performance of all methods in F1 score drops in the case of increasing the class labels exponentially. We also implement and evaluate an oversampling strategy to mitigate class imbalance issues. Furthermore, oversampling improves the classification performance of TTP extraction. We provide recommendations from our findings for future cybersecurity researchers, such as the construction of a benchmark dataset from a large corpus; and the selection of textual features of TTP. Our work, along with the dataset and implementation source code, can work as a baseline for cybersecurity researchers to test and compare the performance of future TTP extraction methods.
What are the attackers doing now? Automating cyber threat intelligence extraction from text on pace with the changing threat landscape: A survey
Sep 14, 2021
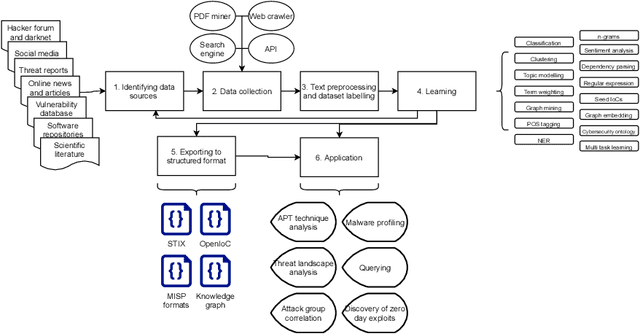
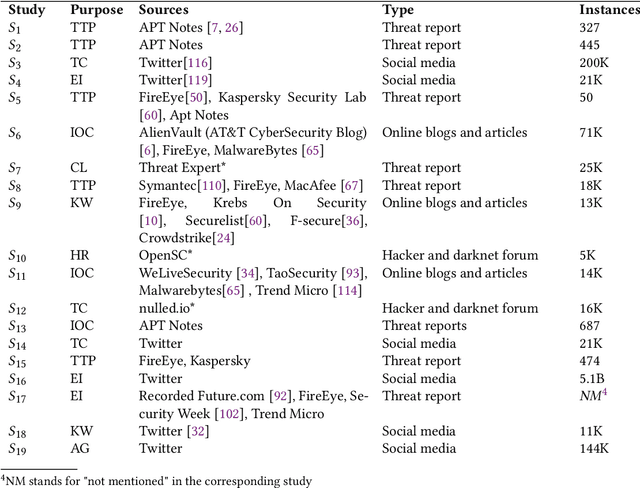
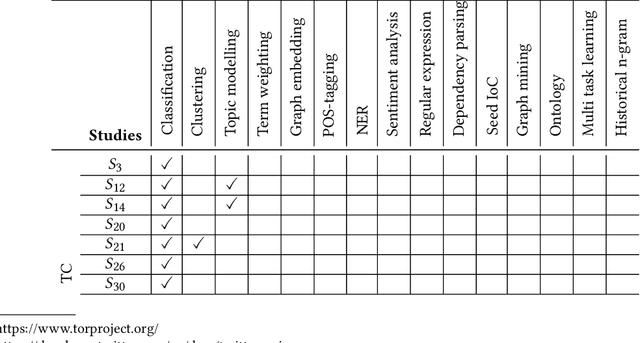
Cybersecurity researchers have contributed to the automated extraction of CTI from textual sources, such as threat reports and online articles, where cyberattack strategies, procedures, and tools are described. The goal of this article is to aid cybersecurity researchers understand the current techniques used for cyberthreat intelligence extraction from text through a survey of relevant studies in the literature. We systematically collect "CTI extraction from text"-related studies from the literature and categorize the CTI extraction purposes. We propose a CTI extraction pipeline abstracted from these studies. We identify the data sources, techniques, and CTI sharing formats utilized in the context of the proposed pipeline. Our work finds ten types of extraction purposes, such as extraction indicators of compromise extraction, TTPs (tactics, techniques, procedures of attack), and cybersecurity keywords. We also identify seven types of textual sources for CTI extraction, and textual data obtained from hacker forums, threat reports, social media posts, and online news articles have been used by almost 90% of the studies. Natural language processing along with both supervised and unsupervised machine learning techniques such as named entity recognition, topic modelling, dependency parsing, supervised classification, and clustering are used for CTI extraction. We observe the technical challenges associated with these studies related to obtaining available clean, labelled data which could assure replication, validation, and further extension of the studies. As we find the studies focusing on CTI information extraction from text, we advocate for building upon the current CTI extraction work to help cybersecurity practitioners with proactive decision making such as threat prioritization, automated threat modelling to utilize knowledge from past cybersecurity incidents.