 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat are the attackers doing now? Automating cyber threat intelligence extraction from text on pace with the changing threat landscape: A survey
Paper and Code

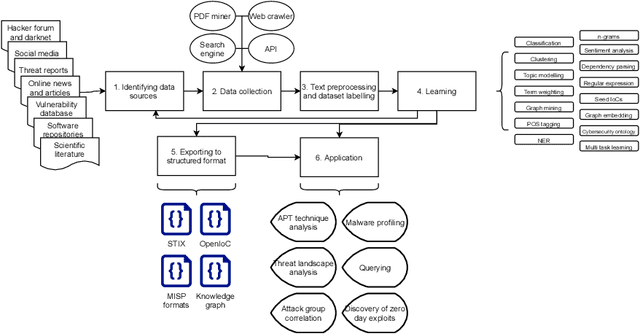
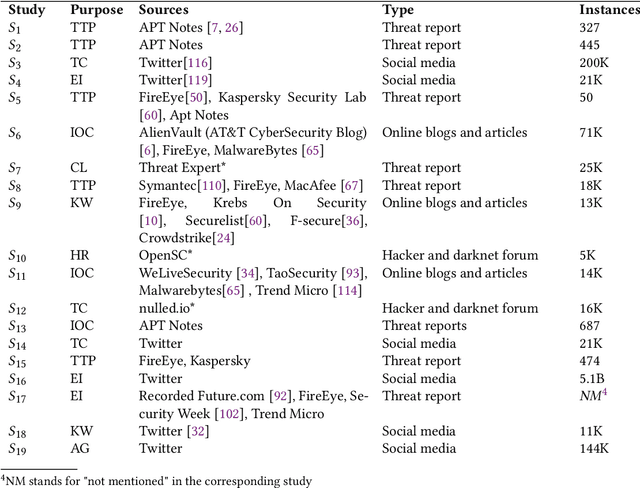
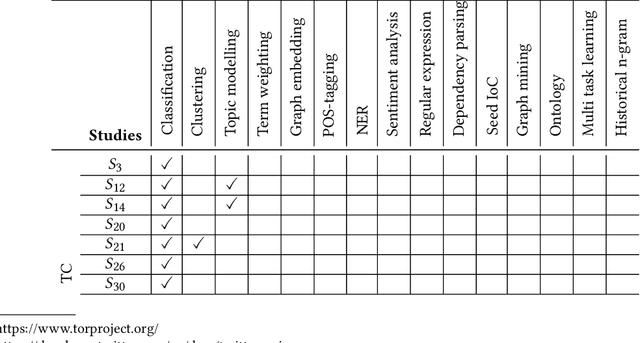
Cybersecurity researchers have contributed to the automated extraction of CTI from textual sources, such as threat reports and online articles, where cyberattack strategies, procedures, and tools are described. The goal of this article is to aid cybersecurity researchers understand the current techniques used for cyberthreat intelligence extraction from text through a survey of relevant studies in the literature. We systematically collect "CTI extraction from text"-related studies from the literature and categorize the CTI extraction purposes. We propose a CTI extraction pipeline abstracted from these studies. We identify the data sources, techniques, and CTI sharing formats utilized in the context of the proposed pipeline. Our work finds ten types of extraction purposes, such as extraction indicators of compromise extraction, TTPs (tactics, techniques, procedures of attack), and cybersecurity keywords. We also identify seven types of textual sources for CTI extraction, and textual data obtained from hacker forums, threat reports, social media posts, and online news articles have been used by almost 90% of the studies. Natural language processing along with both supervised and unsupervised machine learning techniques such as named entity recognition, topic modelling, dependency parsing, supervised classification, and clustering are used for CTI extraction. We observe the technical challenges associated with these studies related to obtaining available clean, labelled data which could assure replication, validation, and further extension of the studies. As we find the studies focusing on CTI information extraction from text, we advocate for building upon the current CTI extraction work to help cybersecurity practitioners with proactive decision making such as threat prioritization, automated threat modelling to utilize knowledge from past cybersecurity incidents.