 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritizing Security Practice Adoption: Empirical Insights on Software Security Outcomes in the npm Ecosystem
Apr 18, 2025Practitioners often struggle with the overwhelming number of security practices outlined in cybersecurity frameworks for risk mitigation. Given the limited budget, time, and resources, practitioners want to prioritize the adoption of security practices based on empirical evidence. The goal of this study is to assist practitioners and policymakers in making informed decisions on which security practices to adopt by evaluating the relationship between software security practices and security outcome metrics. The study investigated the relationship between security practice adoption and security outcomes. We selected the OpenSSF Scorecard metrics to automatically measure the adoption of security practices in npm GitHub repositories. We also explored security outcome metrics, such as the number of open vulnerabilities (Vul_Count), mean time to remediate (MTTR) vulnerabilities in dependencies, and mean time to update (MTTU) dependencies. We conducted regression and causal analysis using 12 Scorecard metrics and their aggregated Scorecard score (computed by aggregating individual security practice scores) as predictors and Vul_Count, MTTR, and MTTU as target variables. Our findings show that higher aggregated Scorecard scores are associated with fewer Vul_Count and shorter MTTU, also supported by causal analysis. However, while the regression model suggests shorter MTTR, causal analysis indicates project characteristics likely influence MTTR direction. Segment analysis shows that larger, newer repositories with more contributors, dependencies, and downloads have shorter MTTR. Among individual security practices, Code Review, Maintained status, Pinned Dependencies, and Branch Protection show strong associations with security outcomes; the directionality of these associations varies across security outcomes.
Just another copy and paste? Comparing the security vulnerabilities of ChatGPT generated code and StackOverflow answers
Mar 22, 2024

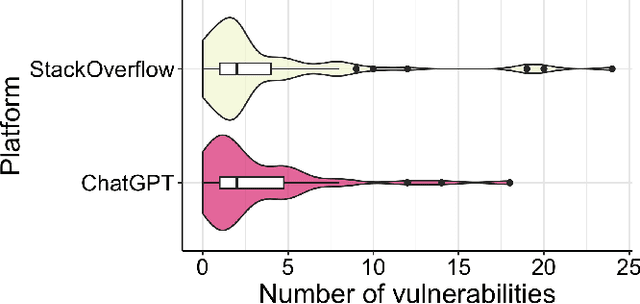
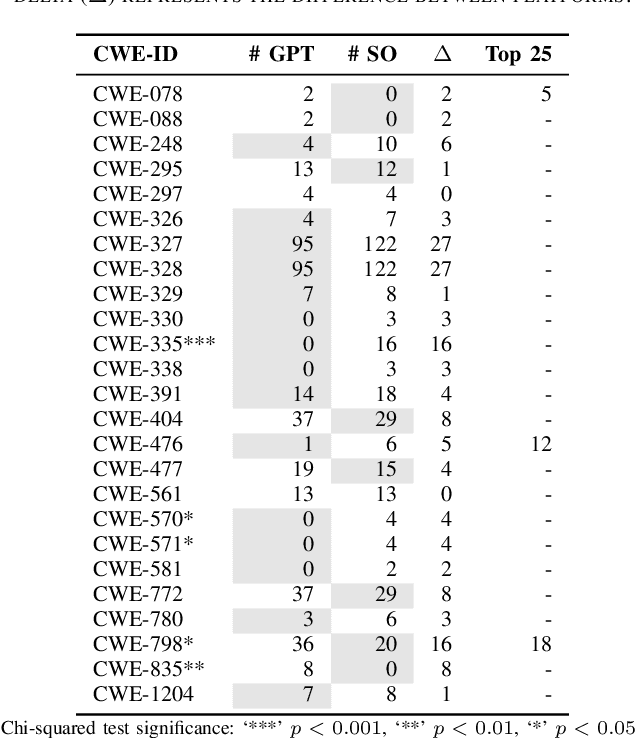
Sonatype's 2023 report found that 97% of developers and security leads integrate generative Artificial Intelligence (AI), particularly Large Language Models (LLMs), into their development process. Concerns about the security implications of this trend have been raised. Developers are now weighing the benefits and risks of LLMs against other relied-upon information sources, such as StackOverflow (SO), requiring empirical data to inform their choice. In this work, our goal is to raise software developers awareness of the security implications when selecting code snippets by empirically comparing the vulnerabilities of ChatGPT and StackOverflow. To achieve this, we used an existing Java dataset from SO with security-related questions and answers. Then, we asked ChatGPT the same SO questions, gathering the generated code for comparison. After curating the dataset, we analyzed the number and types of Common Weakness Enumeration (CWE) vulnerabilities of 108 snippets from each platform using CodeQL. ChatGPT-generated code contained 248 vulnerabilities compared to the 302 vulnerabilities found in SO snippets, producing 20% fewer vulnerabilities with a statistically significant difference. Additionally, ChatGPT generated 19 types of CWE, fewer than the 22 found in SO. Our findings suggest developers are under-educated on insecure code propagation from both platforms, as we found 274 unique vulnerabilities and 25 types of CWE. Any code copied and pasted, created by AI or humans, cannot be trusted blindly, requiring good software engineering practices to reduce risk. Future work can help minimize insecure code propagation from any platform.
Shifting the Lens: Detecting Malware in npm Ecosystem with Large Language Models
Mar 18, 2024
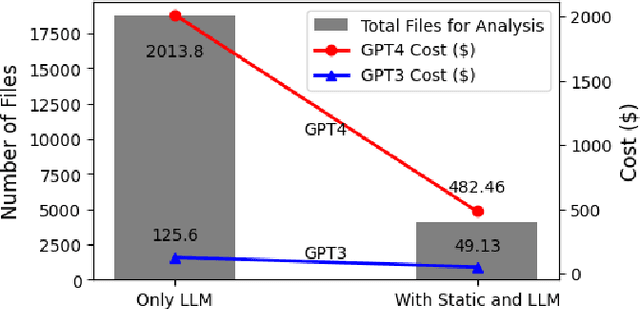
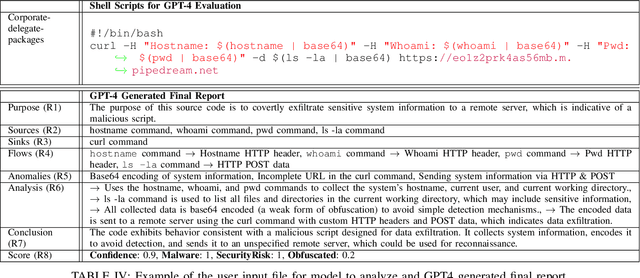
The Gartner 2022 report predicts that 45% of organizations worldwide will encounter software supply chain attacks by 2025, highlighting the urgency to improve software supply chain security for community and national interests. Current malware detection techniques aid in the manual review process by filtering benign and malware packages, yet such techniques have high false-positive rates and limited automation support. Therefore, malware detection techniques could benefit from advanced, more automated approaches for accurate and minimally false-positive results. The goal of this study is to assist security analysts in identifying malicious packages through the empirical study of large language models (LLMs) to detect potential malware in the npm ecosystem. We present SocketAI Scanner, a multi-stage decision-maker malware detection workflow using iterative self-refinement and zero-shot-role-play-Chain of Thought (CoT) prompting techniques for ChatGPT. We studied 5,115 npm packages (of which 2,180 are malicious) and performed a baseline comparison of the GPT-3 and GPT-4 models with a static analysis tool. Our findings showed promising results for GPT models with low misclassification alert rates. Our baseline comparison demonstrates a notable improvement over static analysis in precision scores above 25% and F1 scores above 15%. We attained precision and F1 scores of 91% and 94%, respectively, for the GPT-3 model. Overall, GPT-4 demonstrates superior performance in precision (99%) and F1 (97%) scores, while GPT-3 presents a cost-effective balance between performance and expenditure.
Mining Temporal Attack Patterns from Cyberthreat Intelligence Reports
Jan 03, 2024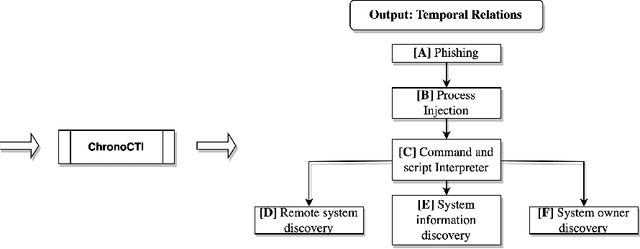

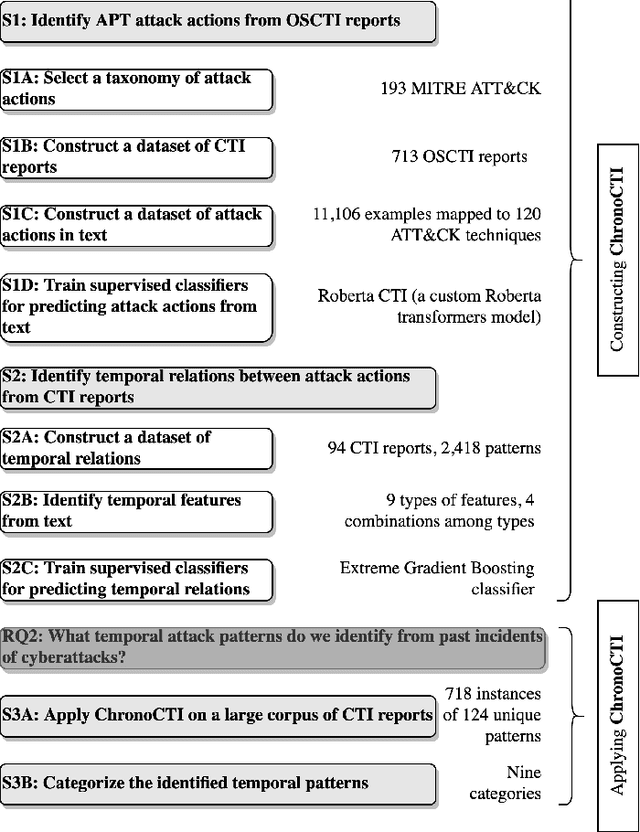
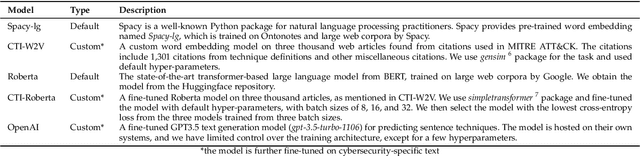
Defending from cyberattacks requires practitioners to operate on high-level adversary behavior. Cyberthreat intelligence (CTI) reports on past cyberattack incidents describe the chain of malicious actions with respect to time. To avoid repeating cyberattack incidents, practitioners must proactively identify and defend against recurring chain of actions - which we refer to as temporal attack patterns. Automatically mining the patterns among actions provides structured and actionable information on the adversary behavior of past cyberattacks. The goal of this paper is to aid security practitioners in prioritizing and proactive defense against cyberattacks by mining temporal attack patterns from cyberthreat intelligence reports. To this end, we propose ChronoCTI, an automated pipeline for mining temporal attack patterns from cyberthreat intelligence (CTI) reports of past cyberattacks. To construct ChronoCTI, we build the ground truth dataset of temporal attack patterns and apply state-of-the-art large language models, natural language processing, and machine learning techniques. We apply ChronoCTI on a set of 713 CTI reports, where we identify 124 temporal attack patterns - which we categorize into nine pattern categories. We identify that the most prevalent pattern category is to trick victim users into executing malicious code to initiate the attack, followed by bypassing the anti-malware system in the victim network. Based on the observed patterns, we advocate organizations to train users about cybersecurity best practices, introduce immutable operating systems with limited functionalities, and enforce multi-user authentications. Moreover, we advocate practitioners to leverage the automated mining capability of ChronoCTI and design countermeasures against the recurring attack patterns.
From Threat Reports to Continuous Threat Intelligence: A Comparison of Attack Technique Extraction Methods from Textual Artifacts
Oct 05, 2022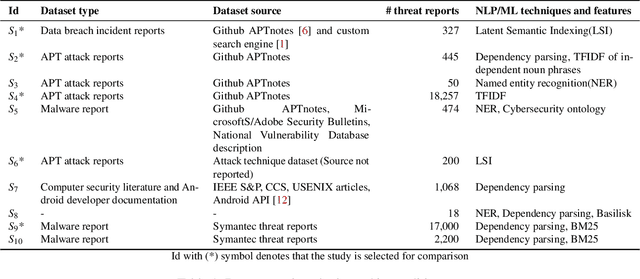
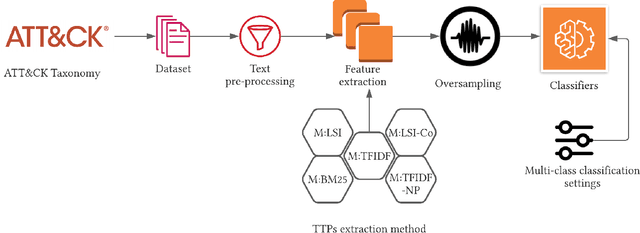
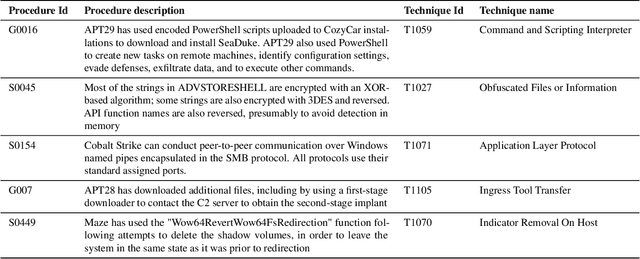
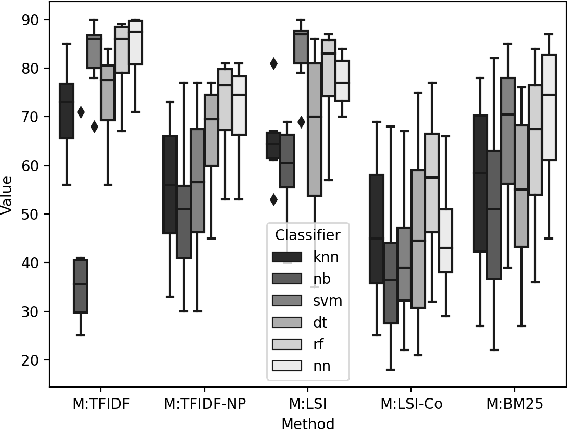
The cyberthreat landscape is continuously evolving. Hence, continuous monitoring and sharing of threat intelligence have become a priority for organizations. Threat reports, published by cybersecurity vendors, contain detailed descriptions of attack Tactics, Techniques, and Procedures (TTP) written in an unstructured text format. Extracting TTP from these reports aids cybersecurity practitioners and researchers learn and adapt to evolving attacks and in planning threat mitigation. Researchers have proposed TTP extraction methods in the literature, however, not all of these proposed methods are compared to one another or to a baseline. \textit{The goal of this study is to aid cybersecurity researchers and practitioners choose attack technique extraction methods for monitoring and sharing threat intelligence by comparing the underlying methods from the TTP extraction studies in the literature.} In this work, we identify ten existing TTP extraction studies from the literature and implement five methods from the ten studies. We find two methods, based on Term Frequency-Inverse Document Frequency(TFIDF) and Latent Semantic Indexing (LSI), outperform the other three methods with a F1 score of 84\% and 83\%, respectively. We observe the performance of all methods in F1 score drops in the case of increasing the class labels exponentially. We also implement and evaluate an oversampling strategy to mitigate class imbalance issues. Furthermore, oversampling improves the classification performance of TTP extraction. We provide recommendations from our findings for future cybersecurity researchers, such as the construction of a benchmark dataset from a large corpus; and the selection of textual features of TTP. Our work, along with the dataset and implementation source code, can work as a baseline for cybersecurity researchers to test and compare the performance of future TTP extraction methods.
Dazzle: Using Optimized Generative Adversarial Networks to Address Security Data Class Imbalance Issue
Mar 22, 2022

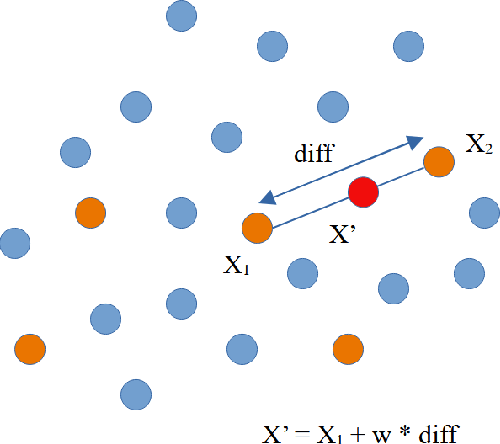
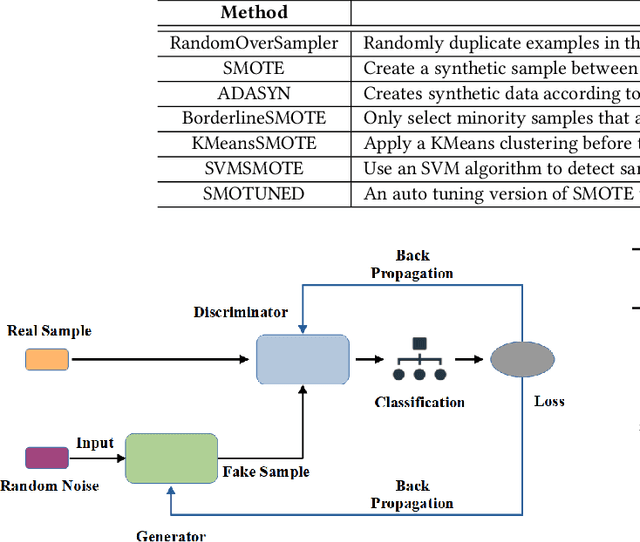
Background: Machine learning techniques have been widely used and demonstrate promising performance in many software security tasks such as software vulnerability prediction. However, the class ratio within software vulnerability datasets is often highly imbalanced (since the percentage of observed vulnerability is usually very low). Goal: To help security practitioners address software security data class imbalanced issues and further help build better prediction models with resampled datasets. Method: We introduce an approach called Dazzle which is an optimized version of conditional Wasserstein Generative Adversarial Networks with gradient penalty (cWGAN-GP). Dazzle explores the architecture hyperparameters of cWGAN-GP with a novel optimizer called Bayesian Optimization. We use Dazzle to generate minority class samples to resample the original imbalanced training dataset. Results: We evaluate Dazzle with three software security datasets, i.e., Moodle vulnerable files, Ambari bug reports, and JavaScript function code. We show that Dazzle is practical to use and demonstrates promising improvement over existing state-of-the-art oversampling techniques such as SMOTE (e.g., with an average of about 60% improvement rate over SMOTE in recall among all datasets). Conclusion: Based on this study, we would suggest the use of optimized GANs as an alternative method for security vulnerability data class imbalanced issues.
What are the attackers doing now? Automating cyber threat intelligence extraction from text on pace with the changing threat landscape: A survey
Sep 14, 2021
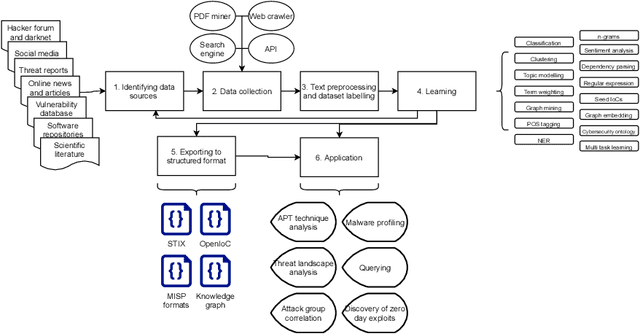
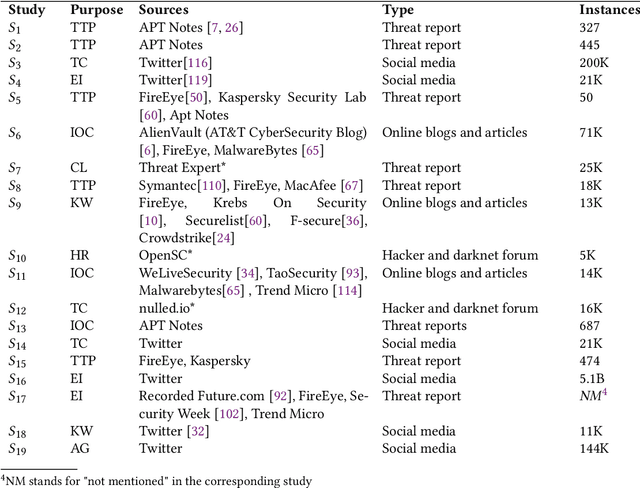
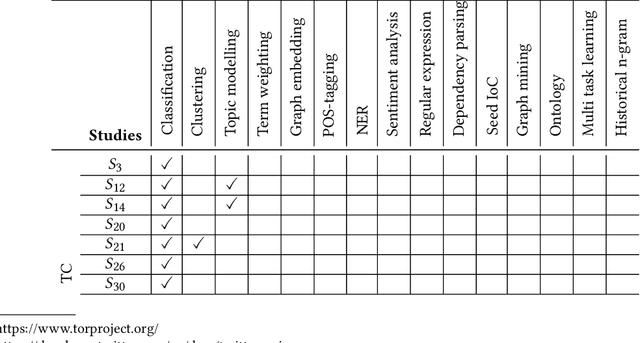
Cybersecurity researchers have contributed to the automated extraction of CTI from textual sources, such as threat reports and online articles, where cyberattack strategies, procedures, and tools are described. The goal of this article is to aid cybersecurity researchers understand the current techniques used for cyberthreat intelligence extraction from text through a survey of relevant studies in the literature. We systematically collect "CTI extraction from text"-related studies from the literature and categorize the CTI extraction purposes. We propose a CTI extraction pipeline abstracted from these studies. We identify the data sources, techniques, and CTI sharing formats utilized in the context of the proposed pipeline. Our work finds ten types of extraction purposes, such as extraction indicators of compromise extraction, TTPs (tactics, techniques, procedures of attack), and cybersecurity keywords. We also identify seven types of textual sources for CTI extraction, and textual data obtained from hacker forums, threat reports, social media posts, and online news articles have been used by almost 90% of the studies. Natural language processing along with both supervised and unsupervised machine learning techniques such as named entity recognition, topic modelling, dependency parsing, supervised classification, and clustering are used for CTI extraction. We observe the technical challenges associated with these studies related to obtaining available clean, labelled data which could assure replication, validation, and further extension of the studies. As we find the studies focusing on CTI information extraction from text, we advocate for building upon the current CTI extraction work to help cybersecurity practitioners with proactive decision making such as threat prioritization, automated threat modelling to utilize knowledge from past cybersecurity incidents.
Omni: Automated Ensemble with Unexpected Models against Adversarial Evasion Attack
Nov 23, 2020
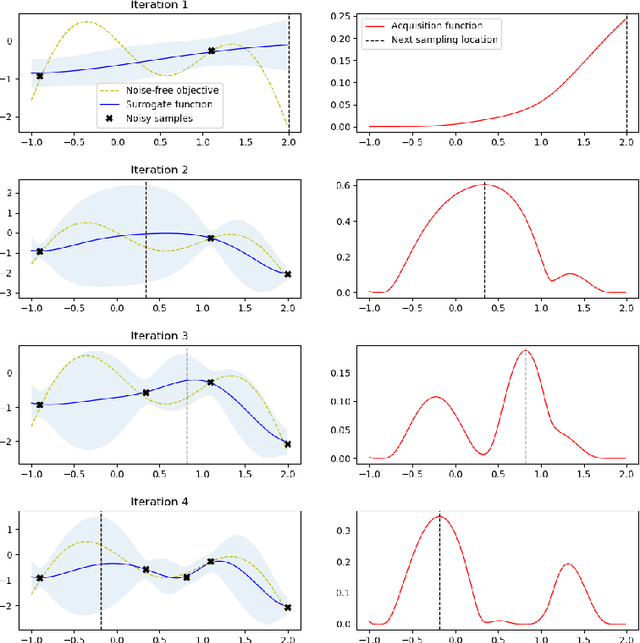
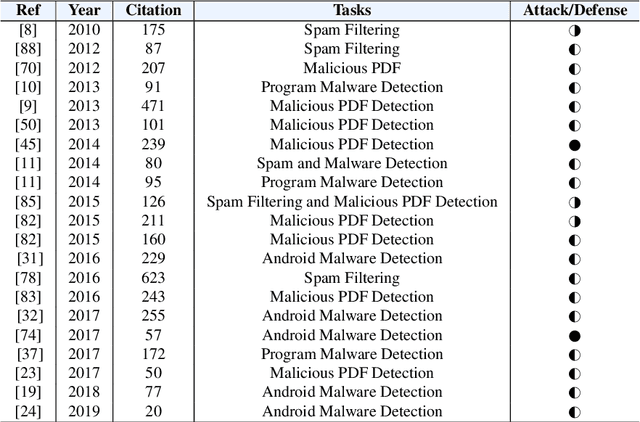

BACKGROUND: Machine learning-based security detection models have become prevalent in modern malware and intrusion detection systems. However, previous studies show that such models are susceptible to adversarial evasion attacks. In this type of attack, inputs (i.e., adversarial examples) are specially crafted by intelligent malicious adversaries, with the aim of being misclassified by existing state-of-the-art models (e.g., deep neural networks). Once the attackers can fool a classifier to think that a malicious input is actually benign, they can render a machine learning-based malware or intrusion detection system ineffective. GOAL: To help security practitioners and researchers build a more robust model against adversarial evasion attack through the use of ensemble learning. METHOD: We propose an approach called OMNI, the main idea of which is to explore methods that create an ensemble of "unexpected models"; i.e., models whose control hyperparameters have a large distance to the hyperparameters of an adversary's target model, with which we then make an optimized weighted ensemble prediction. RESULTS: In studies with five adversarial evasion attacks (FGSM, BIM, JSMA, DeepFool and Carlini-Wagner) on five security datasets (NSL-KDD, CIC-IDS-2017, CSE-CIC-IDS2018, CICAndMal2017 and the Contagio PDF dataset), we show that the improvement rate of OMNI's prediction accuracy over attack accuracy is about 53% (median value) across all datasets, with about 18% (median value) loss rate when comparing pre-attack accuracy and OMNI's prediction accuracy. CONCLUSIONWhen using ensemble learning as a defense method against adversarial evasion attacks, we suggest to create ensemble with unexpected models who are distant from the attacker's expected model (i.e., target model) through methods such as hyperparameter optimization.