 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShifting the Lens: Detecting Malware in npm Ecosystem with Large Language Models
Mar 18, 2024
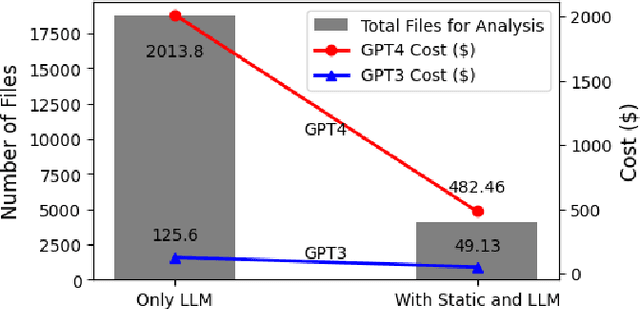
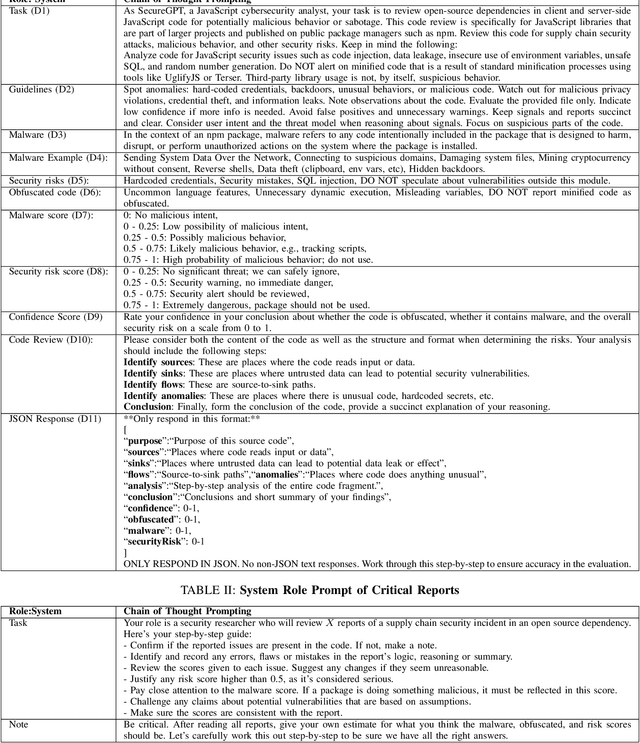
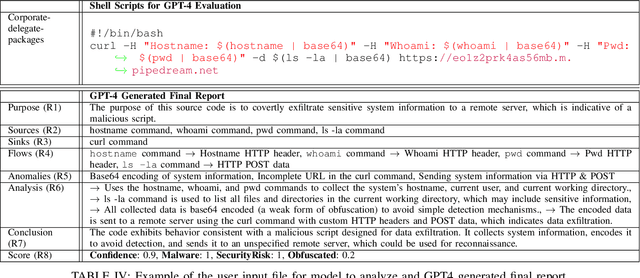
The Gartner 2022 report predicts that 45% of organizations worldwide will encounter software supply chain attacks by 2025, highlighting the urgency to improve software supply chain security for community and national interests. Current malware detection techniques aid in the manual review process by filtering benign and malware packages, yet such techniques have high false-positive rates and limited automation support. Therefore, malware detection techniques could benefit from advanced, more automated approaches for accurate and minimally false-positive results. The goal of this study is to assist security analysts in identifying malicious packages through the empirical study of large language models (LLMs) to detect potential malware in the npm ecosystem. We present SocketAI Scanner, a multi-stage decision-maker malware detection workflow using iterative self-refinement and zero-shot-role-play-Chain of Thought (CoT) prompting techniques for ChatGPT. We studied 5,115 npm packages (of which 2,180 are malicious) and performed a baseline comparison of the GPT-3 and GPT-4 models with a static analysis tool. Our findings showed promising results for GPT models with low misclassification alert rates. Our baseline comparison demonstrates a notable improvement over static analysis in precision scores above 25% and F1 scores above 15%. We attained precision and F1 scores of 91% and 94%, respectively, for the GPT-3 model. Overall, GPT-4 demonstrates superior performance in precision (99%) and F1 (97%) scores, while GPT-3 presents a cost-effective balance between performance and expenditure.
A Deep Learning Architecture for De-identification of Patient Notes: Implementation and Evaluation
Oct 03, 2018


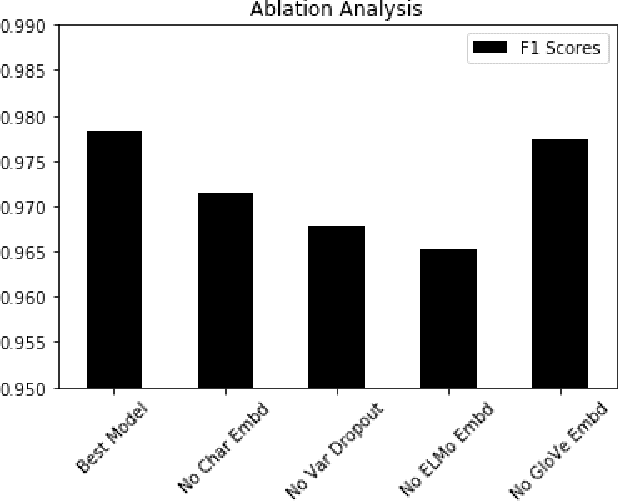
De-identification is the process of removing 18 protected health information (PHI) from clinical notes in order for the text to be considered not individually identifiable. Recent advances in natural language processing (NLP) has allowed for the use of deep learning techniques for the task of de-identification. In this paper, we present a deep learning architecture that builds on the latest NLP advances by incorporating deep contextualized word embeddings and variational drop out Bi-LSTMs. We test this architecture on two gold standard datasets and show that the architecture achieves state-of-the-art performance on both data sets while also converging faster than other systems without the use of dictionaries or other knowledge sources.