 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritizing Security Practice Adoption: Empirical Insights on Software Security Outcomes in the npm Ecosystem
Apr 18, 2025Practitioners often struggle with the overwhelming number of security practices outlined in cybersecurity frameworks for risk mitigation. Given the limited budget, time, and resources, practitioners want to prioritize the adoption of security practices based on empirical evidence. The goal of this study is to assist practitioners and policymakers in making informed decisions on which security practices to adopt by evaluating the relationship between software security practices and security outcome metrics. The study investigated the relationship between security practice adoption and security outcomes. We selected the OpenSSF Scorecard metrics to automatically measure the adoption of security practices in npm GitHub repositories. We also explored security outcome metrics, such as the number of open vulnerabilities (Vul_Count), mean time to remediate (MTTR) vulnerabilities in dependencies, and mean time to update (MTTU) dependencies. We conducted regression and causal analysis using 12 Scorecard metrics and their aggregated Scorecard score (computed by aggregating individual security practice scores) as predictors and Vul_Count, MTTR, and MTTU as target variables. Our findings show that higher aggregated Scorecard scores are associated with fewer Vul_Count and shorter MTTU, also supported by causal analysis. However, while the regression model suggests shorter MTTR, causal analysis indicates project characteristics likely influence MTTR direction. Segment analysis shows that larger, newer repositories with more contributors, dependencies, and downloads have shorter MTTR. Among individual security practices, Code Review, Maintained status, Pinned Dependencies, and Branch Protection show strong associations with security outcomes; the directionality of these associations varies across security outcomes.
Shifting the Lens: Detecting Malware in npm Ecosystem with Large Language Models
Mar 18, 2024
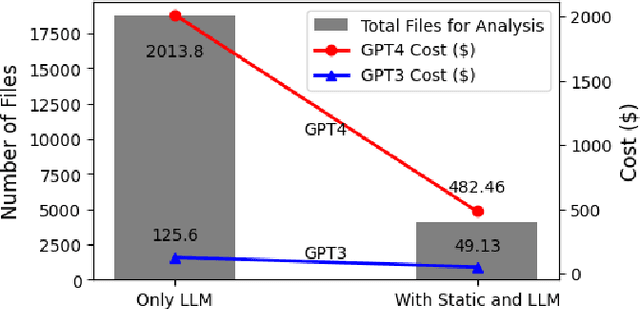
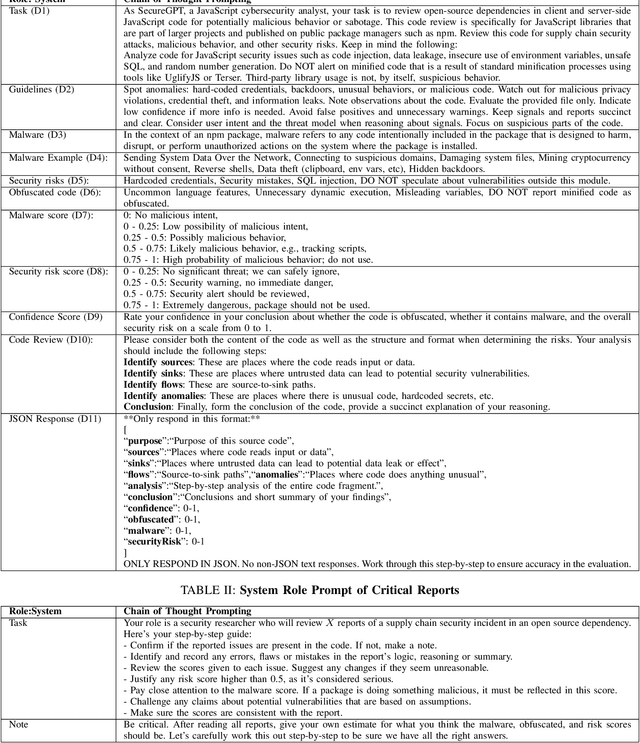
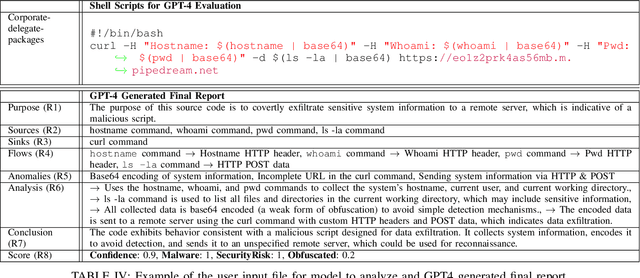
The Gartner 2022 report predicts that 45% of organizations worldwide will encounter software supply chain attacks by 2025, highlighting the urgency to improve software supply chain security for community and national interests. Current malware detection techniques aid in the manual review process by filtering benign and malware packages, yet such techniques have high false-positive rates and limited automation support. Therefore, malware detection techniques could benefit from advanced, more automated approaches for accurate and minimally false-positive results. The goal of this study is to assist security analysts in identifying malicious packages through the empirical study of large language models (LLMs) to detect potential malware in the npm ecosystem. We present SocketAI Scanner, a multi-stage decision-maker malware detection workflow using iterative self-refinement and zero-shot-role-play-Chain of Thought (CoT) prompting techniques for ChatGPT. We studied 5,115 npm packages (of which 2,180 are malicious) and performed a baseline comparison of the GPT-3 and GPT-4 models with a static analysis tool. Our findings showed promising results for GPT models with low misclassification alert rates. Our baseline comparison demonstrates a notable improvement over static analysis in precision scores above 25% and F1 scores above 15%. We attained precision and F1 scores of 91% and 94%, respectively, for the GPT-3 model. Overall, GPT-4 demonstrates superior performance in precision (99%) and F1 (97%) scores, while GPT-3 presents a cost-effective balance between performance and expenditure.