 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Waitlist Mortality Prediction in Heart Transplantation Through Time-to-Event Modeling using New Longitudinal UNOS Dataset
Jul 09, 2025Decisions about managing patients on the heart transplant waitlist are currently made by committees of doctors who consider multiple factors, but the process remains largely ad-hoc. With the growing volume of longitudinal patient, donor, and organ data collected by the United Network for Organ Sharing (UNOS) since 2018, there is increasing interest in analytical approaches to support clinical decision-making at the time of organ availability. In this study, we benchmark machine learning models that leverage longitudinal waitlist history data for time-dependent, time-to-event modeling of waitlist mortality. We train on 23,807 patient records with 77 variables and evaluate both survival prediction and discrimination at a 1-year horizon. Our best model achieves a C-Index of 0.94 and AUROC of 0.89, significantly outperforming previous models. Key predictors align with known risk factors while also revealing novel associations. Our findings can support urgency assessment and policy refinement in heart transplant decision making.
Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models
Apr 08, 2025Recent advancements in large language models (LLMs) have revolutionized their ability to handle single-turn tasks, yet real-world applications demand sophisticated multi-turn interactions. This survey provides a comprehensive review of recent advancements in evaluating and enhancing multi-turn interactions in LLMs. Focusing on task-specific scenarios, from instruction following in diverse domains such as math and coding to complex conversational engagements in roleplay, healthcare, education, and even adversarial jailbreak settings, we systematically examine the challenges of maintaining context, coherence, fairness, and responsiveness over prolonged dialogues. The paper organizes current benchmarks and datasets into coherent categories that reflect the evolving landscape of multi-turn dialogue evaluation. In addition, we review a range of enhancement methodologies under multi-turn settings, including model-centric strategies (contextual learning, supervised fine-tuning, reinforcement learning, and new architectures), external integration approaches (memory-augmented, retrieval-based methods, and knowledge graph), and agent-based techniques for collaborative interactions. Finally, we discuss open challenges and propose future directions for research to further advance the robustness and effectiveness of multi-turn interactions in LLMs. Related resources and papers are available at https://github.com/yubol-cmu/Awesome-Multi-Turn-LLMs.
Can LLMs Support Medical Knowledge Imputation? An Evaluation-Based Perspective
Mar 29, 2025


Medical knowledge graphs (KGs) are essential for clinical decision support and biomedical research, yet they often exhibit incompleteness due to knowledge gaps and structural limitations in medical coding systems. This issue is particularly evident in treatment mapping, where coding systems such as ICD, Mondo, and ATC lack comprehensive coverage, resulting in missing or inconsistent associations between diseases and their potential treatments. To address this issue, we have explored the use of Large Language Models (LLMs) for imputing missing treatment relationships. Although LLMs offer promising capabilities in knowledge augmentation, their application in medical knowledge imputation presents significant risks, including factual inaccuracies, hallucinated associations, and instability between and within LLMs. In this study, we systematically evaluate LLM-driven treatment mapping, assessing its reliability through benchmark comparisons. Our findings highlight critical limitations, including inconsistencies with established clinical guidelines and potential risks to patient safety. This study serves as a cautionary guide for researchers and practitioners, underscoring the importance of critical evaluation and hybrid approaches when leveraging LLMs to enhance treatment mappings on medical knowledge graphs.
Firm or Fickle? Evaluating Large Language Models Consistency in Sequential Interactions
Mar 28, 2025


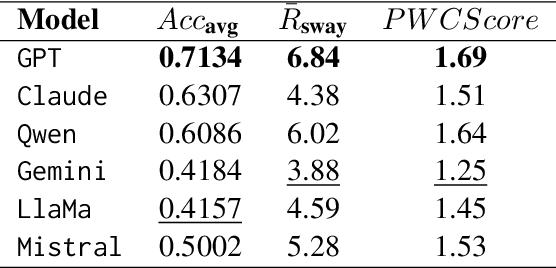
Large Language Models (LLMs) have shown remarkable capabilities across various tasks, but their deployment in high-stake domains requires consistent performance across multiple interaction rounds. This paper introduces a comprehensive framework for evaluating and improving LLM response consistency, making three key contributions. First, we propose a novel Position-Weighted Consistency (PWC) score that captures both the importance of early-stage stability and recovery patterns in multi-turn interactions. Second, we present a carefully curated benchmark dataset spanning diverse domains and difficulty levels, specifically designed to evaluate LLM consistency under various challenging follow-up scenarios. Third, we introduce Confidence-Aware Response Generation (CARG), a framework that significantly improves response stability by incorporating model confidence signals into the generation process. Empirical results demonstrate that CARG significantly improves response stability without sacrificing accuracy, underscoring its potential for reliable LLM deployment in critical applications.
No Black Box Anymore: Demystifying Clinical Predictive Modeling with Temporal-Feature Cross Attention Mechanism
Mar 26, 2025
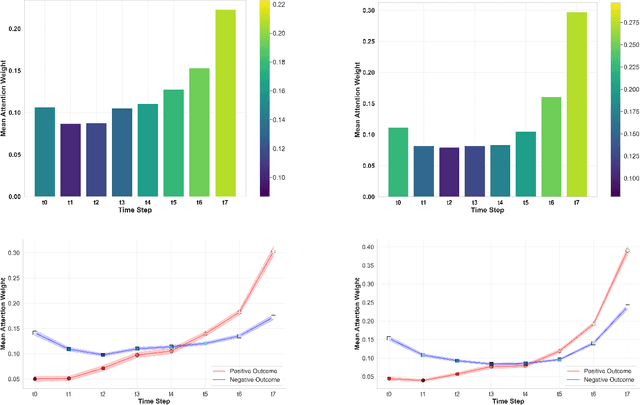


Despite the outstanding performance of deep learning models in clinical prediction tasks, explainability remains a significant challenge. Inspired by transformer architectures, we introduce the Temporal-Feature Cross Attention Mechanism (TFCAM), a novel deep learning framework designed to capture dynamic interactions among clinical features across time, enhancing both predictive accuracy and interpretability. In an experiment with 1,422 patients with Chronic Kidney Disease, predicting progression to End-Stage Renal Disease, TFCAM outperformed LSTM and RETAIN baselines, achieving an AUROC of 0.95 and an F1-score of 0.69. Beyond performance gains, TFCAM provides multi-level explainability by identifying critical temporal periods, ranking feature importance, and quantifying how features influence each other across time before affecting predictions. Our approach addresses the "black box" limitations of deep learning in healthcare, offering clinicians transparent insights into disease progression mechanisms while maintaining state-of-the-art predictive performance.
Enhancing End Stage Renal Disease Outcome Prediction: A Multi-Sourced Data-Driven Approach
Oct 02, 2024Objective: To improve prediction of Chronic Kidney Disease (CKD) progression to End Stage Renal Disease (ESRD) using machine learning (ML) and deep learning (DL) models applied to an integrated clinical and claims dataset of varying observation windows, supported by explainable AI (XAI) to enhance interpretability and reduce bias. Materials and Methods: We utilized data about 10,326 CKD patients, combining their clinical and claims information from 2009 to 2018. Following data preprocessing, cohort identification, and feature engineering, we evaluated multiple statistical, ML and DL models using data extracted from five distinct observation windows. Feature importance and Shapley value analysis were employed to understand key predictors. Models were tested for robustness, clinical relevance, misclassification errors and bias issues. Results: Integrated data models outperformed those using single data sources, with the Long Short-Term Memory (LSTM) model achieving the highest AUC (0.93) and F1 score (0.65). A 24-month observation window was identified as optimal for balancing early detection and prediction accuracy. The 2021 eGFR equation improved prediction accuracy and reduced racial bias, notably for African American patients. Discussion: Improved ESRD prediction accuracy, results interpretability and bias mitigation strategies presented in this study have the potential to significantly enhance CKD and ESRD management, support targeted early interventions and reduce healthcare disparities. Conclusion: This study presents a robust framework for predicting ESRD outcomes in CKD patients, improving clinical decision-making and patient care through multi-sourced, integrated data and AI/ML methods. Future research will expand data integration and explore the application of this framework to other chronic diseases.
Towards Interpretable End-Stage Renal Disease (ESRD) Prediction: Utilizing Administrative Claims Data with Explainable AI Techniques
Sep 18, 2024



This study explores the potential of utilizing administrative claims data, combined with advanced machine learning and deep learning techniques, to predict the progression of Chronic Kidney Disease (CKD) to End-Stage Renal Disease (ESRD). We analyze a comprehensive, 10-year dataset provided by a major health insurance organization to develop prediction models for multiple observation windows using traditional machine learning methods such as Random Forest and XGBoost as well as deep learning approaches such as Long Short-Term Memory (LSTM) networks. Our findings demonstrate that the LSTM model, particularly with a 24-month observation window, exhibits superior performance in predicting ESRD progression, outperforming existing models in the literature. We further apply SHapley Additive exPlanations (SHAP) analysis to enhance interpretability, providing insights into the impact of individual features on predictions at the individual patient level. This study underscores the value of leveraging administrative claims data for CKD management and predicting ESRD progression.
On Curating Responsible and Representative Healthcare Video Recommendations for Patient Education and Health Literacy: An Augmented Intelligence Approach
Jul 13, 2022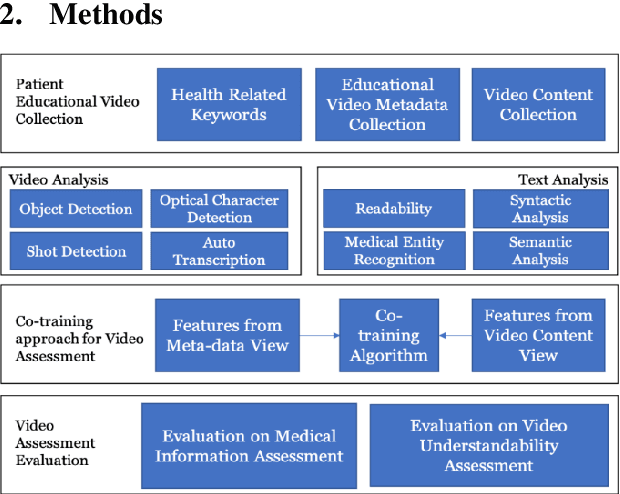
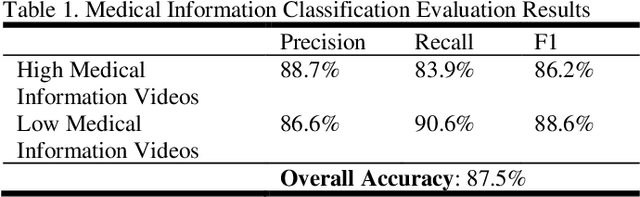
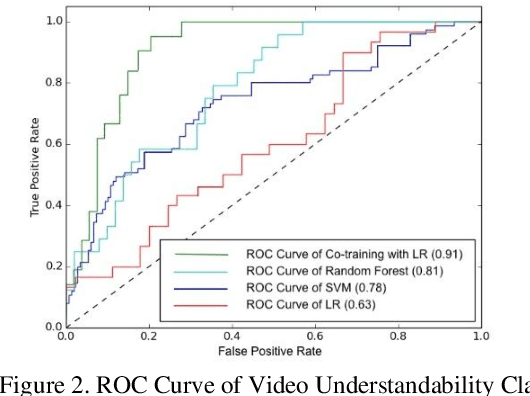
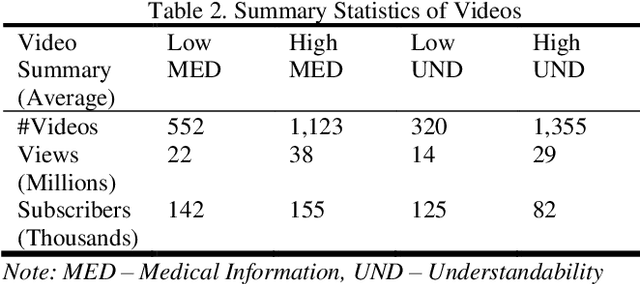
Studies suggest that one in three US adults use the Internet to diagnose or learn about a health concern. However, such access to health information online could exacerbate the disparities in health information availability and use. Health information seeking behavior (HISB) refers to the ways in which individuals seek information about their health, risks, illnesses, and health-protective behaviors. For patients engaging in searches for health information on digital media platforms, health literacy divides can be exacerbated both by their own lack of knowledge and by algorithmic recommendations, with results that disproportionately impact disadvantaged populations, minorities, and low health literacy users. This study reports on an exploratory investigation of the above challenges by examining whether responsible and representative recommendations can be generated using advanced analytic methods applied to a large corpus of videos and their metadata on a chronic condition (diabetes) from the YouTube social media platform. The paper focusses on biases associated with demographic characters of actors using videos on diabetes that were retrieved and curated for multiple criteria such as encoded medical content and their understandability to address patient education and population health literacy needs. This approach offers an immense opportunity for innovation in human-in-the-loop, augmented-intelligence, bias-aware and responsible algorithmic recommendations by combining the perspectives of health professionals and patients into a scalable and generalizable machine learning framework for patient empowerment and improved health outcomes.
Limitations of ROC on Imbalanced Data: Evaluation of LVAD Mortality Risk Scores
Oct 29, 2020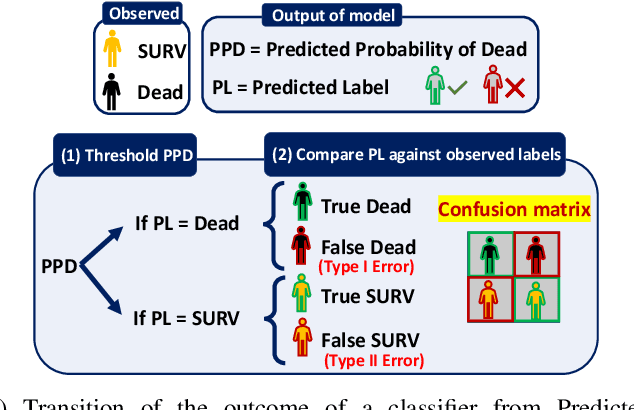

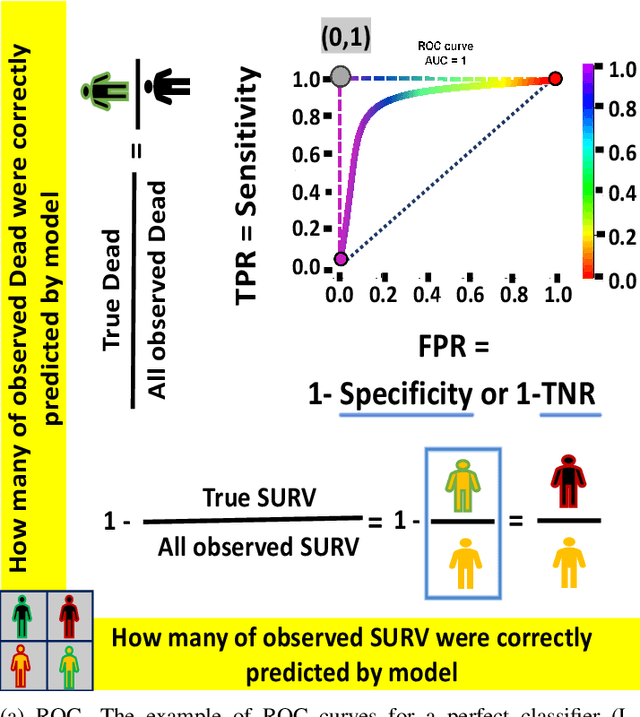
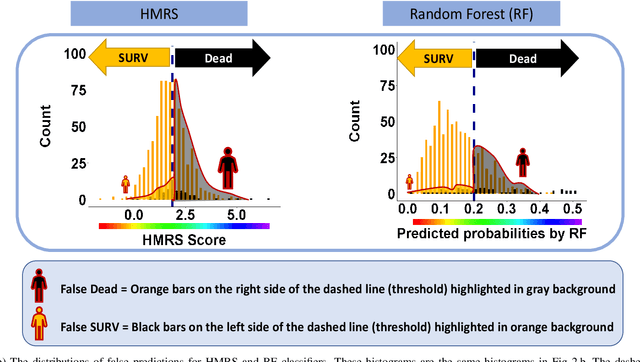
Objective: This study illustrates the ambiguity of ROC in evaluating two classifiers of 90-day LVAD mortality. This paper also introduces the precision recall curve (PRC) as a supplemental metric that is more representative of LVAD classifiers performance in predicting the minority class. Background: In the LVAD domain, the receiver operating characteristic (ROC) is a commonly applied metric of performance of classifiers. However, ROC can provide a distorted view of classifiers ability to predict short-term mortality due to the overwhelmingly greater proportion of patients who survive, i.e. imbalanced data. Methods: This study compared the ROC and PRC for the outcome of two classifiers for 90-day LVAD mortality for 800 patients (test group) recorded in INTERMACS who received a continuous-flow LVAD between 2006 and 2016 (mean age of 59 years; 146 females vs. 654 males) in which mortality rate is only %8 at 90-day (imbalanced data). The two classifiers were HeartMate Risk Score (HMRS) and a Random Forest (RF). Results: The ROC indicates fairly good performance of RF and HRMS classifiers with Area Under Curves (AUC) of 0.77 vs. 0.63, respectively. This is in contrast with their PRC with AUC of 0.43 vs. 0.16 for RF and HRMS, respectively. The PRC for HRMS showed the precision rapidly dropped to only 10% with slightly increasing sensitivity. Conclusion: The ROC can portray an overly-optimistic performance of a classifier or risk score when applied to imbalanced data. The PRC provides better insight about the performance of a classifier by focusing on the minority class.
Early Stratification of Patients at Risk for Postoperative Complications after Elective Colectomy
Nov 29, 2018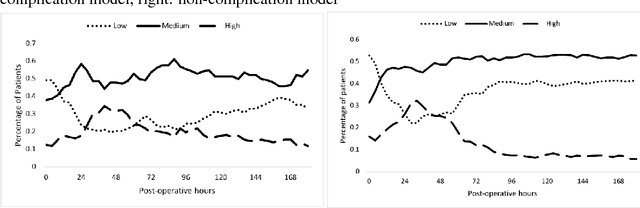
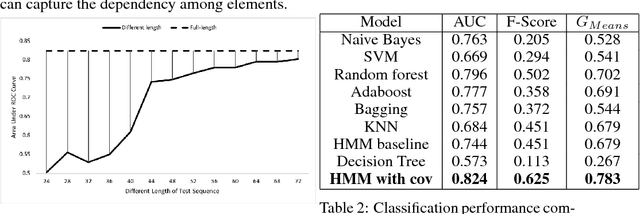
Stratifying patients at risk for postoperative complications may facilitate timely and accurate workups and reduce the burden of adverse events on patients and the health system. Currently, a widely-used surgical risk calculator created by the American College of Surgeons, NSQIP, uses 21 preoperative covariates to assess risk of postoperative complications, but lacks dynamic, real-time capabilities to accommodate postoperative information. We propose a new Hidden Markov Model sequence classifier for analyzing patients' postoperative temperature sequences that incorporates their time-invariant characteristics in both transition probability and initial state probability in order to develop a postoperative "real-time" complication detector. Data from elective Colectomy surgery indicate that our method has improved classification performance compared to 8 other machine learning classifiers when using the full temperature sequence associated with the patients' length of stay. Additionally, within 44 hours after surgery, the performance of the model is close to that of full-length temperature sequence.