 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Support Medical Knowledge Imputation? An Evaluation-Based Perspective
Mar 29, 2025


Medical knowledge graphs (KGs) are essential for clinical decision support and biomedical research, yet they often exhibit incompleteness due to knowledge gaps and structural limitations in medical coding systems. This issue is particularly evident in treatment mapping, where coding systems such as ICD, Mondo, and ATC lack comprehensive coverage, resulting in missing or inconsistent associations between diseases and their potential treatments. To address this issue, we have explored the use of Large Language Models (LLMs) for imputing missing treatment relationships. Although LLMs offer promising capabilities in knowledge augmentation, their application in medical knowledge imputation presents significant risks, including factual inaccuracies, hallucinated associations, and instability between and within LLMs. In this study, we systematically evaluate LLM-driven treatment mapping, assessing its reliability through benchmark comparisons. Our findings highlight critical limitations, including inconsistencies with established clinical guidelines and potential risks to patient safety. This study serves as a cautionary guide for researchers and practitioners, underscoring the importance of critical evaluation and hybrid approaches when leveraging LLMs to enhance treatment mappings on medical knowledge graphs.
Mixed-Integer Optimization with Constraint Learning
Nov 04, 2021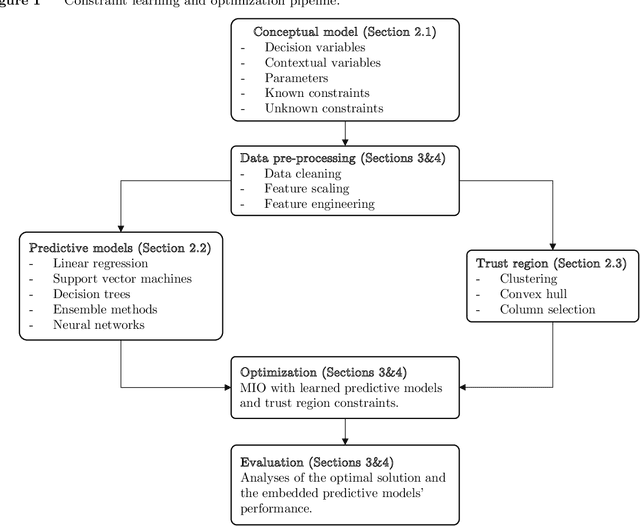

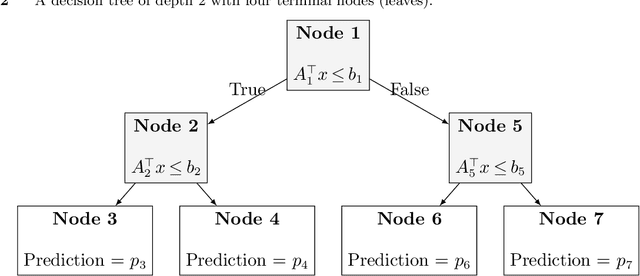
We establish a broad methodological foundation for mixed-integer optimization with learned constraints. We propose an end-to-end pipeline for data-driven decision making in which constraints and objectives are directly learned from data using machine learning, and the trained models are embedded in an optimization formulation. We exploit the mixed-integer optimization-representability of many machine learning methods, including linear models, decision trees, ensembles, and multi-layer perceptrons. The consideration of multiple methods allows us to capture various underlying relationships between decisions, contextual variables, and outcomes. We also characterize a decision trust region using the convex hull of the observations, to ensure credible recommendations and avoid extrapolation. We efficiently incorporate this representation using column generation and clustering. In combination with domain-driven constraints and objective terms, the embedded models and trust region define a mixed-integer optimization problem for prescription generation. We implement this framework as a Python package (OptiCL) for practitioners. We demonstrate the method in both chemotherapy optimization and World Food Programme planning. The case studies illustrate the benefit of the framework in generating high-quality prescriptions, the value added by the trust region, the incorporation of multiple machine learning methods, and the inclusion of multiple learned constraints.
From predictions to prescriptions: A data-driven response to COVID-19
Jun 30, 2020The COVID-19 pandemic has created unprecedented challenges worldwide. Strained healthcare providers make difficult decisions on patient triage, treatment and care management on a daily basis. Policy makers have imposed social distancing measures to slow the disease, at a steep economic price. We design analytical tools to support these decisions and combat the pandemic. Specifically, we propose a comprehensive data-driven approach to understand the clinical characteristics of COVID-19, predict its mortality, forecast its evolution, and ultimately alleviate its impact. By leveraging cohort-level clinical data, patient-level hospital data, and census-level epidemiological data, we develop an integrated four-step approach, combining descriptive, predictive and prescriptive analytics. First, we aggregate hundreds of clinical studies into the most comprehensive database on COVID-19 to paint a new macroscopic picture of the disease. Second, we build personalized calculators to predict the risk of infection and mortality as a function of demographics, symptoms, comorbidities, and lab values. Third, we develop a novel epidemiological model to project the pandemic's spread and inform social distancing policies. Fourth, we propose an optimization model to re-allocate ventilators and alleviate shortages. Our results have been used at the clinical level by several hospitals to triage patients, guide care management, plan ICU capacity, and re-distribute ventilators. At the policy level, they are currently supporting safe back-to-work policies at a major institution and equitable vaccine distribution planning at a major pharmaceutical company, and have been integrated into the US Center for Disease Control's pandemic forecast.
Interpretable Clustering via Optimal Trees
Dec 03, 2018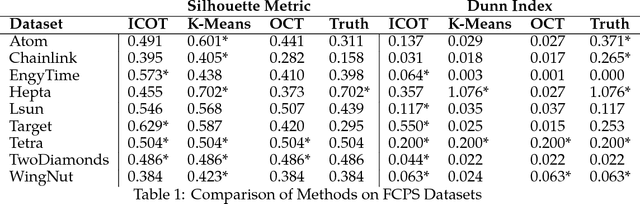
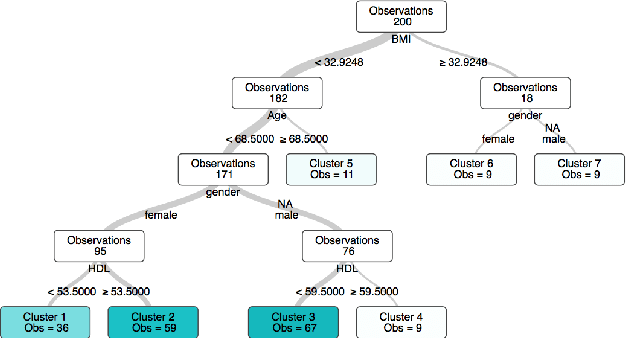
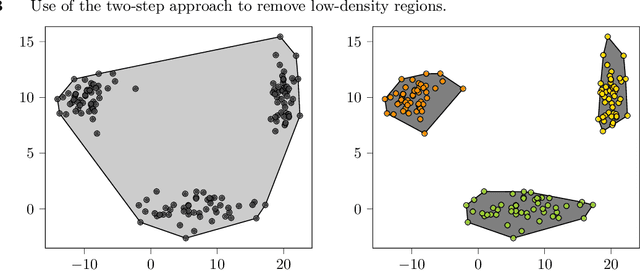
State-of-the-art clustering algorithms use heuristics to partition the feature space and provide little insight into the rationale for cluster membership, limiting their interpretability. In healthcare applications, the latter poses a barrier to the adoption of these methods since medical researchers are required to provide detailed explanations of their decisions in order to gain patient trust and limit liability. We present a new unsupervised learning algorithm that leverages Mixed Integer Optimization techniques to generate interpretable tree-based clustering models. Utilizing the flexible framework of Optimal Trees, our method approximates the globally optimal solution leading to high quality partitions of the feature space. Our algorithm, can incorporate various internal validation metrics, naturally determines the optimal number of clusters, and is able to account for mixed numeric and categorical data. It achieves comparable or superior performance on both synthetic and real world datasets when compared to K-Means while offering significantly higher interpretability.