 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr. DocBench: A Comprehensive Benchmark for Expert-Level and Difficult Document Parsing
May 31, 2026Document parsing and recognition are fundamental capabilities for vision-language models (VLMs) and document processing systems. However, existing Optical Character Recognition (OCR) and document parsing benchmarks are increasingly limited in coverage and difficulty: many focus on common document genres or uniformly sampled pages where modern parsers already perform strongly, while offering limited annotation for expert-domain structures such as chemical formula, music notation, complex tables, and cross-page layouts. We introduce Dr. DocBench, a difficulty-aware benchmark for expert-level document parsing. Built from a large-scale multilingual book corpus, Dr. DocBench spans 52 BISAC subject domains and selects challenging documents through parser-failure-based sampling, targeting cases where multiple state-of-the-art systems struggle. It contains 4,514 annotated pages from long documents averaging around 100 pages, with 65k high-quality page- and block-level annotations for layout, reading order, hierarchical relations, and domain-specific visual contents. Evaluations of pipeline-based parsers and general-purpose VLMs show that strong performance on existing benchmarks does not transfer to our expert-level document parsing. Our analysis reveals substantial failures across subjects, content types, and structural attributes, highlighting Dr. DocBench as a comprehensive testbed for diagnosing and advancing document intelligence.
The CRITICAL Records Integrated Standardization Pipeline (CRISP): End-to-End Processing of Large-scale Multi-institutional OMOP CDM Data
Sep 10, 2025While existing critical care EHR datasets such as MIMIC and eICU have enabled significant advances in clinical AI research, the CRITICAL dataset opens new frontiers by providing extensive scale and diversity -- containing 1.95 billion records from 371,365 patients across four geographically diverse CTSA institutions. CRITICAL's unique strength lies in capturing full-spectrum patient journeys, including pre-ICU, ICU, and post-ICU encounters across both inpatient and outpatient settings. This multi-institutional, longitudinal perspective creates transformative opportunities for developing generalizable predictive models and advancing health equity research. However, the richness of this multi-site resource introduces substantial complexity in data harmonization, with heterogeneous collection practices and diverse vocabulary usage patterns requiring sophisticated preprocessing approaches. We present CRISP to unlock the full potential of this valuable resource. CRISP systematically transforms raw Observational Medical Outcomes Partnership Common Data Model data into ML-ready datasets through: (1) transparent data quality management with comprehensive audit trails, (2) cross-vocabulary mapping of heterogeneous medical terminologies to unified SNOMED-CT standards, with deduplication and unit standardization, (3) modular architecture with parallel optimization enabling complete dataset processing in $<$1 day even on standard computing hardware, and (4) comprehensive baseline model benchmarks spanning multiple clinical prediction tasks to establish reproducible performance standards. By providing processing pipeline, baseline implementations, and detailed transformation documentation, CRISP saves researchers months of preprocessing effort and democratizes access to large-scale multi-institutional critical care data, enabling them to focus on advancing clinical AI.
Balancing Optimality and Diversity: Human-Centered Decision Making through Generative Curation
Sep 17, 2024



The surge in data availability has inundated decision-makers with an overwhelming array of choices. While existing approaches focus on optimizing decisions based on quantifiable metrics, practical decision-making often requires balancing measurable quantitative criteria with unmeasurable qualitative factors embedded in the broader context. In such cases, algorithms can generate high-quality recommendations, but the final decision rests with the human, who must weigh both dimensions. We define the process of selecting the optimal set of algorithmic recommendations in this context as human-centered decision making. To address this challenge, we introduce a novel framework called generative curation, which optimizes the true desirability of decision options by integrating both quantitative and qualitative aspects. Our framework uses a Gaussian process to model unknown qualitative factors and derives a diversity metric that balances quantitative optimality with qualitative diversity. This trade-off enables the generation of a manageable subset of diverse, near-optimal actions that are robust to unknown qualitative preferences. To operationalize this framework, we propose two implementation approaches: a generative neural network architecture that produces a distribution $\pi$ to efficiently sample a diverse set of near-optimal actions, and a sequential optimization method to iteratively generates solutions that can be easily incorporated into complex optimization formulations. We validate our approach with extensive datasets, demonstrating its effectiveness in enhancing decision-making processes across a range of complex environments, with significant implications for policy and management.
Learning to Cover: Online Learning and Optimization with Irreversible Decisions
Jun 20, 2024We define an online learning and optimization problem with irreversible decisions contributing toward a coverage target. At each period, a decision-maker selects facilities to open, receives information on the success of each one, and updates a machine learning model to guide future decisions. The goal is to minimize costs across a finite horizon under a chance constraint reflecting the coverage target. We derive an optimal algorithm and a tight lower bound in an asymptotic regime characterized by a large target number of facilities $m\to\infty$ but a finite horizon $T\in\mathbb{Z}_+$. We find that the regret grows sub-linearly at a rate $\Theta\left(m^{\frac{1}{2}\cdot\frac{1}{1-2^{-T}}}\right)$, thus converging exponentially fast to $\Theta(\sqrt{m})$. We establish the robustness of this result to the learning environment; we also extend it to a more complicated facility location setting in a bipartite facility-customer graph with a target on customer coverage. Throughout, constructive proofs identify a policy featuring limited exploration initially for learning purposes, and fast exploitation later on for optimization purposes once uncertainty gets mitigated. These findings underscore the benefits of limited online learning and optimization, in that even a few rounds can provide significant benefits as compared to a no-learning baseline.
Neyman Meets Causal Machine Learning: Experimental Evaluation of Individualized Treatment Rules
Apr 25, 2024A century ago, Neyman showed how to evaluate the efficacy of treatment using a randomized experiment under a minimal set of assumptions. This classical repeated sampling framework serves as a basis of routine experimental analyses conducted by today's scientists across disciplines. In this paper, we demonstrate that Neyman's methodology can also be used to experimentally evaluate the efficacy of individualized treatment rules (ITRs), which are derived by modern causal machine learning algorithms. In particular, we show how to account for additional uncertainty resulting from a training process based on cross-fitting. The primary advantage of Neyman's approach is that it can be applied to any ITR regardless of the properties of machine learning algorithms that are used to derive the ITR. We also show, somewhat surprisingly, that for certain metrics, it is more efficient to conduct this ex-post experimental evaluation of an ITR than to conduct an ex-ante experimental evaluation that randomly assigns some units to the ITR. Our analysis demonstrates that Neyman's repeated sampling framework is as relevant for causal inference today as it has been since its inception.
The Cram Method for Efficient Simultaneous Learning and Evaluation
Mar 11, 2024We introduce the "cram" method, a general and efficient approach to simultaneous learning and evaluation using a generic machine learning (ML) algorithm. In a single pass of batched data, the proposed method repeatedly trains an ML algorithm and tests its empirical performance. Because it utilizes the entire sample for both learning and evaluation, cramming is significantly more data-efficient than sample-splitting. The cram method also naturally accommodates online learning algorithms, making its implementation computationally efficient. To demonstrate the power of the cram method, we consider the standard policy learning setting where cramming is applied to the same data to both develop an individualized treatment rule (ITR) and estimate the average outcome that would result if the learned ITR were to be deployed. We show that under a minimal set of assumptions, the resulting crammed evaluation estimator is consistent and asymptotically normal. While our asymptotic results require a relatively weak stabilization condition of ML algorithm, we develop a simple, generic method that can be used with any policy learning algorithm to satisfy this condition. Our extensive simulation studies show that, when compared to sample-splitting, cramming reduces the evaluation standard error by more than 40% while improving the performance of learned policy. We also apply the cram method to a randomized clinical trial to demonstrate its applicability to real-world problems. Finally, we briefly discuss future extensions of the cram method to other learning and evaluation settings.
Statistical Performance Guarantee for Selecting Those Predicted to Benefit Most from Treatment
Oct 12, 2023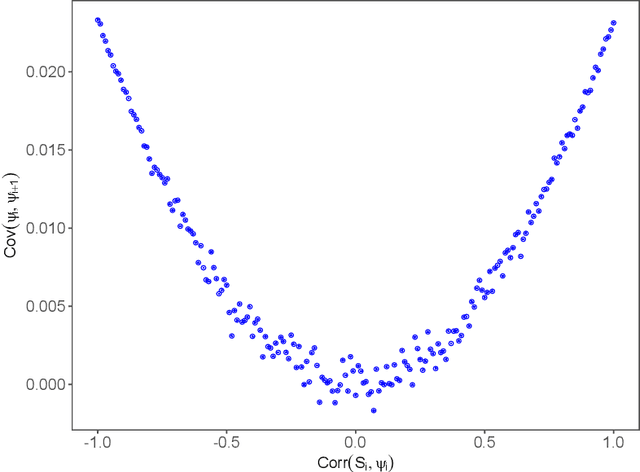



Across a wide array of disciplines, many researchers use machine learning (ML) algorithms to identify a subgroup of individuals, called exceptional responders, who are likely to be helped by a treatment the most. A common approach consists of two steps. One first estimates the conditional average treatment effect or its proxy using an ML algorithm. They then determine the cutoff of the resulting treatment prioritization score to select those predicted to benefit most from the treatment. Unfortunately, these estimated treatment prioritization scores are often biased and noisy. Furthermore, utilizing the same data to both choose a cutoff value and estimate the average treatment effect among the selected individuals suffer from a multiple testing problem. To address these challenges, we develop a uniform confidence band for experimentally evaluating the sorted average treatment effect (GATES) among the individuals whose treatment prioritization score is at least as high as any given quantile value, regardless of how the quantile is chosen. This provides a statistical guarantee that the GATES for the selected subgroup exceeds a certain threshold. The validity of the proposed methodology depends solely on randomization of treatment and random sampling of units without requiring modeling assumptions or resampling methods. This widens its applicability including a wide range of other causal quantities. A simulation study shows that the empirical coverage of the proposed uniform confidence bands is close to the nominal coverage when the sample is as small as 100. We analyze a clinical trial of late-stage prostate cancer and find a relatively large proportion of exceptional responders with a statistical performance guarantee.
Benchmarking Large Language Models on CMExam -- A Comprehensive Chinese Medical Exam Dataset
Jun 08, 2023



Recent advancements in large language models (LLMs) have transformed the field of question answering (QA). However, evaluating LLMs in the medical field is challenging due to the lack of standardized and comprehensive datasets. To address this gap, we introduce CMExam, sourced from the Chinese National Medical Licensing Examination. CMExam consists of 60K+ multiple-choice questions for standardized and objective evaluations, as well as solution explanations for model reasoning evaluation in an open-ended manner. For in-depth analyses of LLMs, we invited medical professionals to label five additional question-wise annotations, including disease groups, clinical departments, medical disciplines, areas of competency, and question difficulty levels. Alongside the dataset, we further conducted thorough experiments with representative LLMs and QA algorithms on CMExam. The results show that GPT-4 had the best accuracy of 61.6% and a weighted F1 score of 0.617. These results highlight a great disparity when compared to human accuracy, which stood at 71.6%. For explanation tasks, while LLMs could generate relevant reasoning and demonstrate improved performance after finetuning, they fall short of a desired standard, indicating ample room for improvement. To the best of our knowledge, CMExam is the first Chinese medical exam dataset to provide comprehensive medical annotations. The experiments and findings of LLM evaluation also provide valuable insights into the challenges and potential solutions in developing Chinese medical QA systems and LLM evaluation pipelines. The dataset and relevant code are available at https://github.com/williamliujl/CMExam.
Distributionally Robust Causal Inference with Observational Data
Oct 15, 2022
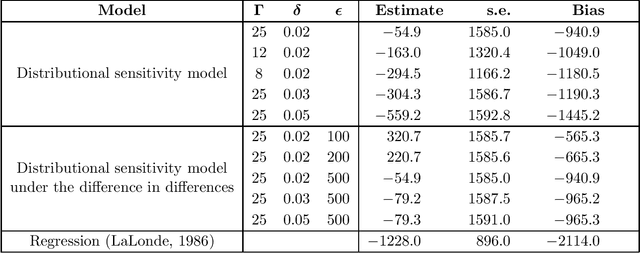
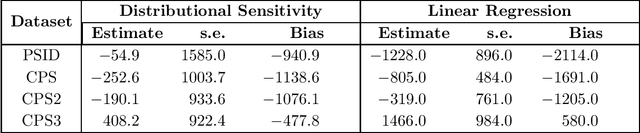

We consider the estimation of average treatment effects in observational studies without the standard assumption of unconfoundedness. We propose a new framework of robust causal inference under the general observational study setting with the possible existence of unobserved confounders. Our approach is based on the method of distributionally robust optimization and proceeds in two steps. We first specify the maximal degree to which the distribution of unobserved potential outcomes may deviate from that of obsered outcomes. We then derive sharp bounds on the average treatment effects under this assumption. Our framework encompasses the popular marginal sensitivity model as a special case and can be extended to the difference-in-difference and regression discontinuity designs as well as instrumental variables. Through simulation and empirical studies, we demonstrate the applicability of the proposed methodology to real-world settings.
Statistical Inference for Heterogeneous Treatment Effects Discovered by Generic Machine Learning in Randomized Experiments
Mar 28, 2022
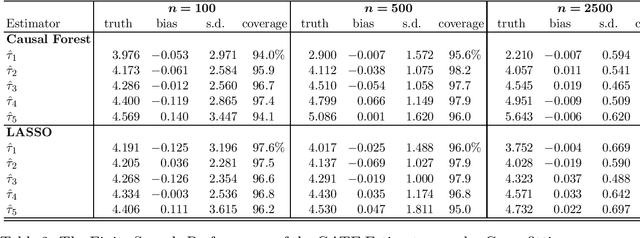

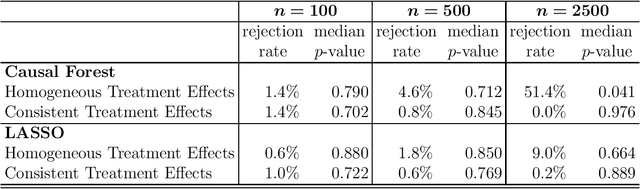
Researchers are increasingly turning to machine learning (ML) algorithms to investigate causal heterogeneity in randomized experiments. Despite their promise, ML algorithms may fail to accurately ascertain heterogeneous treatment effects under practical settings with many covariates and small sample size. In addition, the quantification of estimation uncertainty remains a challenge. We develop a general approach to statistical inference for heterogeneous treatment effects discovered by a generic ML algorithm. We apply the Neyman's repeated sampling framework to a common setting, in which researchers use an ML algorithm to estimate the conditional average treatment effect and then divide the sample into several groups based on the magnitude of the estimated effects. We show how to estimate the average treatment effect within each of these groups, and construct a valid confidence interval. In addition, we develop nonparametric tests of treatment effect homogeneity across groups, and rank-consistency of within-group average treatment effects. The validity of our methodology does not rely on the properties of ML algorithms because it is solely based on the randomization of treatment assignment and random sampling of units. Finally, we generalize our methodology to the cross-fitting procedure by accounting for the additional uncertainty induced by the random splitting of data.