 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Neural TSP Representations for Prescriptive Decision Support
Feb 06, 2026The field of neural combinatorial optimization (NCO) trains neural policies to solve NP-hard problems such as the traveling salesperson problem (TSP). We ask whether, beyond producing good tours, a trained TSP solver learns internal representations that transfer to other optimization-relevant objectives, in the spirit of transfer learning from other domains. We train several attention-based TSP policies, collect their internal activations, and train probes on node/edge embeddings for two NP-hard prescriptive downstream tasks inspired by real-world logistics scenarios: node-removal sensitivity (identifying the most impactful node to remove) and edge-forbid sensitivity (identifying the most critical edge to retain). On a Euclidean TSP100-trained model, probes for both tasks are competitive with existing baselines. Ensembling probe signals with geometric features outperforms the strongest baselines: 65\% top-1 accuracy (vs. 58\% baseline) for the best-node-removal task, and 73\% top-1 accuracy (vs. 67\% baseline) for the worst-edge identification task. To our knowledge, we are the first to study neural TSP solvers as transferable encoders for prescriptive what-if decision-support objectives beyond tour construction. Finally, we show that transfer accuracy increases with solver quality across training and model scale, suggesting that training stronger NCO solvers also yields more useful encoders for downstream objectives. Our code is available at: github.com/ReubenNarad/tsp_prescriptive_probe
SOLID: a Framework of Synergizing Optimization and LLMs for Intelligent Decision-Making
Nov 19, 2025This paper introduces SOLID (Synergizing Optimization and Large Language Models for Intelligent Decision-Making), a novel framework that integrates mathematical optimization with the contextual capabilities of large language models (LLMs). SOLID facilitates iterative collaboration between optimization and LLMs agents through dual prices and deviation penalties. This interaction improves the quality of the decisions while maintaining modularity and data privacy. The framework retains theoretical convergence guarantees under convexity assumptions, providing insight into the design of LLMs prompt. To evaluate SOLID, we applied it to a stock portfolio investment case with historical prices and financial news as inputs. Empirical results demonstrate convergence under various scenarios and indicate improved annualized returns compared to a baseline optimizer-only method, validating the synergy of the two agents. SOLID offers a promising framework for advancing automated and intelligent decision-making across diverse domains.
TabText: a Systematic Approach to Aggregate Knowledge Across Tabular Data Structures
Jun 21, 2022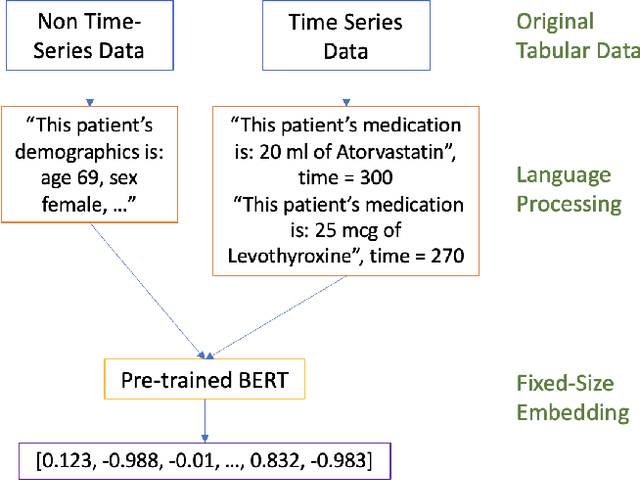
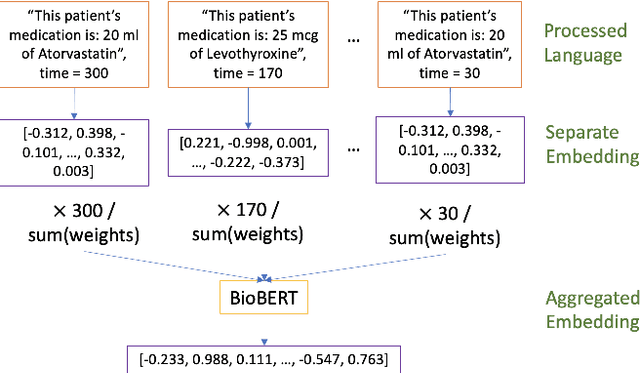
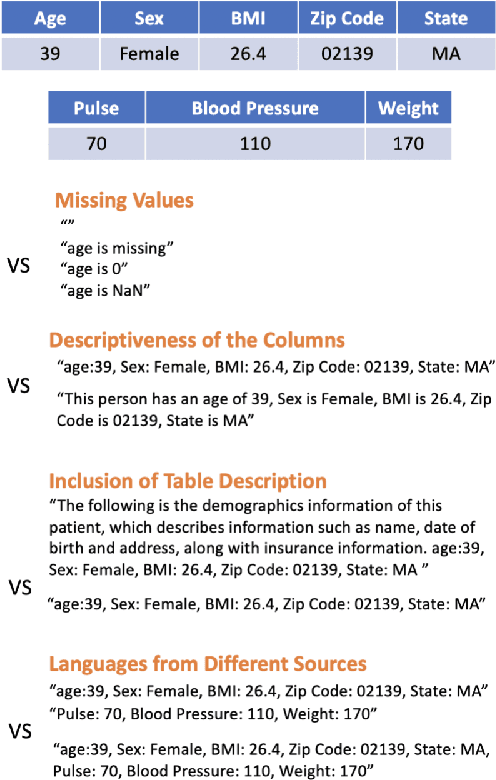
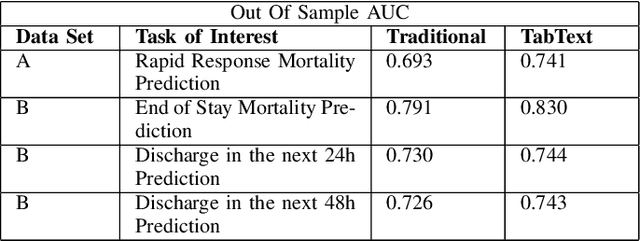
Processing and analyzing tabular data in a productive and efficient way is essential for building successful applications of machine learning in fields such as healthcare. However, the lack of a unified framework for representing and standardizing tabular information poses a significant challenge to researchers and professionals alike. In this work, we present TabText, a methodology that leverages the unstructured data format of language to encode tabular data from different table structures and time periods efficiently and accurately. We show using two healthcare datasets and four prediction tasks that features extracted via TabText outperform those extracted with traditional processing methods by 2-5%. Furthermore, we analyze the sensitivity of our framework against different choices for sentence representations of missing values, meta information and language descriptiveness, and provide insights into winning strategies that improve performance.
Holistic Deep Learning
Oct 29, 2021
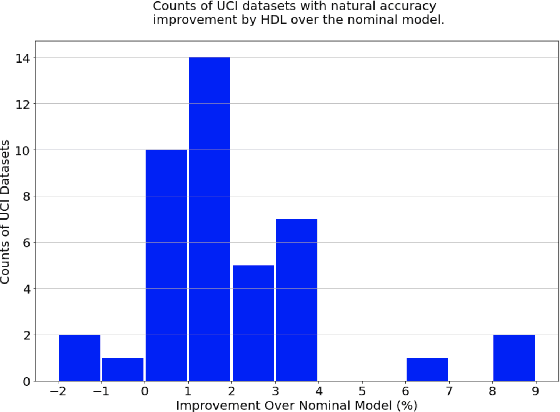
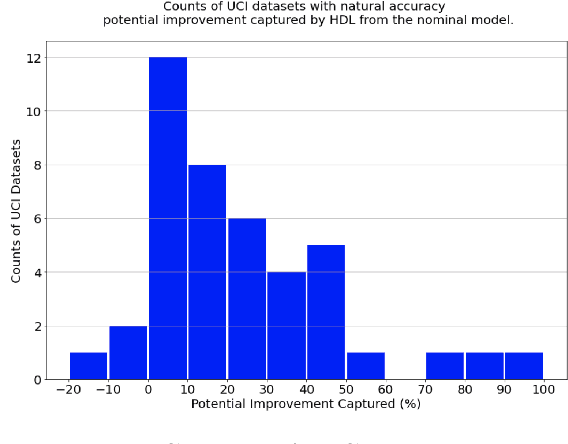

There is much interest in deep learning to solve challenges that arise in applying neural network models in real-world environments. In particular, three areas have received considerable attention: adversarial robustness, parameter sparsity, and output stability. Despite numerous attempts on solving these problems independently, there is very little work addressing the challenges simultaneously. In this paper, we address this problem of constructing holistic deep learning models by proposing a novel formulation that solves these issues in combination. Real-world experiments on both tabular and MNIST dataset show that our formulation is able to simultaneously improve the accuracy, robustness, stability, and sparsity over traditional deep learning models among many others.
Geo-Spatiotemporal Features and Shape-Based Prior Knowledge for Fine-grained Imbalanced Data Classification
Mar 21, 2021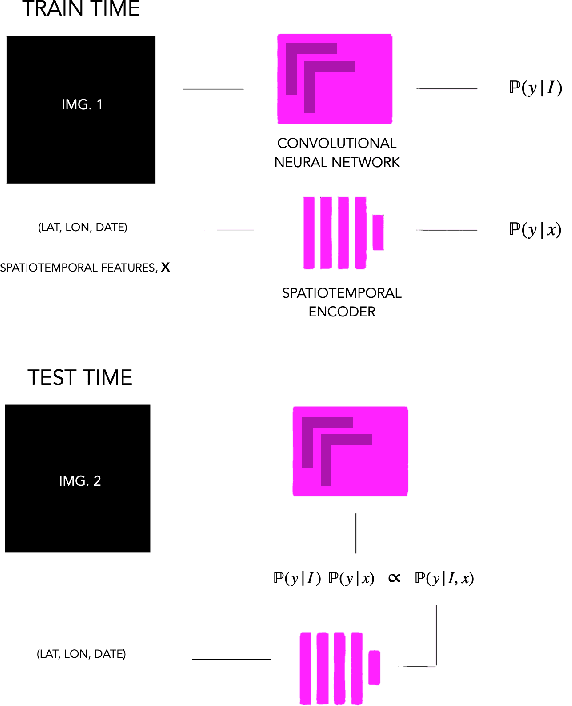
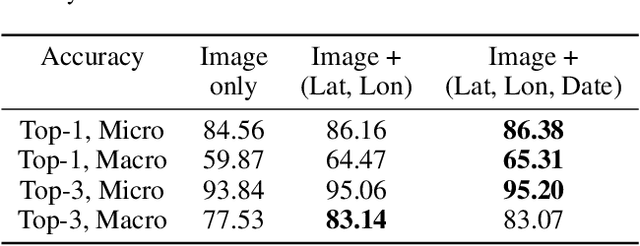

Fine-grained classification aims at distinguishing between items with similar global perception and patterns, but that differ by minute details. Our primary challenges come from both small inter-class variations and large intra-class variations. In this article, we propose to combine several innovations to improve fine-grained classification within the use-case of wildlife, which is of practical interest for experts. We utilize geo-spatiotemporal data to enrich the picture information and further improve the performance. We also investigate state-of-the-art methods for handling the imbalanced data issue.
* Copyright by the authors. All rights reserved to authors only. Correspondence to: ckantor (at) stanford [dot] edu
Hurricane Forecasting: A Novel Multimodal Machine Learning Framework
Nov 11, 2020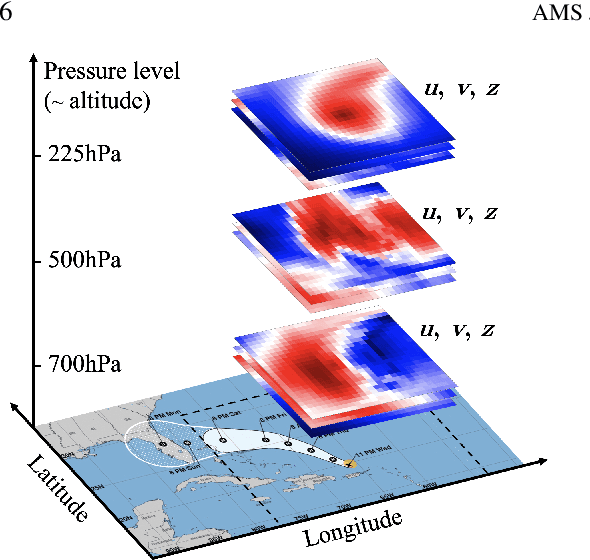
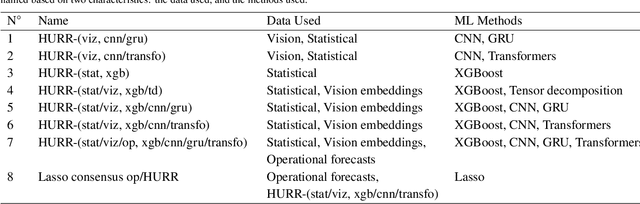
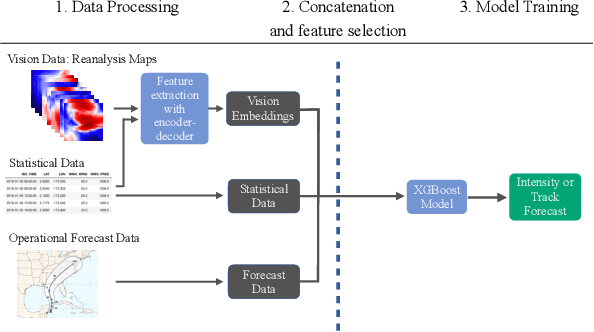

This paper describes a machine learning (ML) framework for tropical cyclone intensity and track forecasting, combining multiple distinct ML techniques and utilizing diverse data sources. Our framework, which we refer to as Hurricast (HURR), is built upon the combination of distinct data processing techniques using gradient-boosted trees and novel encoder-decoder architectures, including CNN, GRU and Transformers components. We propose a deep-feature extractor methodology to mix spatial-temporal data with statistical data efficiently. Our multimodal framework unleashes the potential of making forecasts based on a wide range of data sources, including historical storm data, reanalysis atmospheric images, and operational forecasts. Evaluating our models with current operational forecasts in North Atlantic and Eastern Pacific basins on the last years of available data, results show our models consistently outperform statistical-dynamical models and, albeit less accurate than the best dynamical models, our framework computes forecasts in seconds. Furthermore, the inclusion of Hurricast into an operational forecast consensus model leads to a significant improvement of 5% - 15% over NHC's official forecast, thus highlighting the complementary properties with existing approaches. In summary, our work demonstrates that combining different data sources and distinct machine learning methodologies can lead to superior tropical cyclone forecasting.
From predictions to prescriptions: A data-driven response to COVID-19
Jun 30, 2020The COVID-19 pandemic has created unprecedented challenges worldwide. Strained healthcare providers make difficult decisions on patient triage, treatment and care management on a daily basis. Policy makers have imposed social distancing measures to slow the disease, at a steep economic price. We design analytical tools to support these decisions and combat the pandemic. Specifically, we propose a comprehensive data-driven approach to understand the clinical characteristics of COVID-19, predict its mortality, forecast its evolution, and ultimately alleviate its impact. By leveraging cohort-level clinical data, patient-level hospital data, and census-level epidemiological data, we develop an integrated four-step approach, combining descriptive, predictive and prescriptive analytics. First, we aggregate hundreds of clinical studies into the most comprehensive database on COVID-19 to paint a new macroscopic picture of the disease. Second, we build personalized calculators to predict the risk of infection and mortality as a function of demographics, symptoms, comorbidities, and lab values. Third, we develop a novel epidemiological model to project the pandemic's spread and inform social distancing policies. Fourth, we propose an optimization model to re-allocate ventilators and alleviate shortages. Our results have been used at the clinical level by several hospitals to triage patients, guide care management, plan ICU capacity, and re-distribute ventilators. At the policy level, they are currently supporting safe back-to-work policies at a major institution and equitable vaccine distribution planning at a major pharmaceutical company, and have been integrated into the US Center for Disease Control's pandemic forecast.